结构尺寸的计算
电脑杂谈 发布时间:2020-06-18 21:26:53 来源:网络整理
结构中的成员可以具有不同的数据类型,并且成员按照定义的顺序存储在连续的内存空间中. 与数组不同,结构的大小并不是简单地将所有成员的大小相加. 存储结构变量时,需要考虑系统的地址对齐. 看一下这样的结构:
struct stu1
{
int i; //偏移量为0
字符c; //第一个成员的偏移量加上第一个成员的大小(0 + 4)
int j; //第二个成员的偏移量加上第二个成员的大小(4 + 1)
};
首先介绍一个相关的概念偏移. 偏移量是指结构变量中成员的地址与结构变量地址之间的差. 结构的大小等于最后一个成员的偏移量加上最后一个成员的大小. 显然,结构变量的第一个成员的地址是结构变量的第一个地址. 因此,第一成员i的偏移量为0. 第二成员c的偏移量为第一成员的偏移量加上第一成员的大小(0 + 4),其值为4;第三个成员的偏移量j是第二个成员的偏移量加上第二个成员的大小(4 + 1),该值为5.
实际上,由于存储变量时需要地址对齐,因此编译器在编译程序时将遵循两个原则:
首先,成员在结构变量中的偏移量必须是成员大小的整数倍(0被视为任何数字的整数倍)
第二,结构的大小必须是所有成员大小的整数倍.
与第一项相比,上例中前两个成员的偏移量满足要求,但第三个成员的偏移量为5,这不是其自身大小(int)的整数倍. 处理时,编译器将在第二个成员之后添加3个空字节,以使第三个成员的偏移量变为8.
比较第二个项目,结构的大小等于最后一个成员的偏移量加上它的大小. 上例中计算出的大小为12,符合要求.
看看满足第一条规则而不满足第二条规则的情况
struct stu2
{

int k;
短t;
};
成员k的偏移量为0;成员t的偏移量为4,无需调整. 但是计算得出的大小为6,这显然不是成员k大小的整数倍. 因此,编译器将在成员t之后添加2个字节,以便结构的大小变为8以满足第二个要求. 可以看出,在定义结构类型时,需要考虑字节对齐. 不同的顺序将影响结构的大小. 比较以下两个定义顺序
struct stu3
{
char c1; //偏移量为0符合要求
int i; //偏移量为1,结构变量中成员的偏移量必须是成员大小的整数倍(0被视为任何数字的整数倍),因此偏移量应为4 <
char c2; //偏移量为8(偏移量4 + int大2小4),符合要求
}
计算sizeof(stu3)= 1 + 8 = 9,但9不是int的整数倍,因此最终大小为12
struct stu4
{
char c1; //偏移量为0符合要求
char c2; ////偏移量为1以满足要求
int i; //偏移量为2不符合要求,因此偏移量为4

}
计算sizeof(stu4)= 4 + 4 = 8,8是int的整数倍,所以最终大小是8
如果结构的成员是另一种类型的结构,应如何计算它们?只是扩大它. 但是,应注意,扩展结构的第一成员的偏移量应为扩展结构中最大成员的整数倍. 请参见以下示例:
struct stu5
{
简短的我;
结构
{
字符c;
int j;
} ss;
int k;
}
结构stu5的成员ss.c的偏移量应为4,而不是2. 整个结构的大小应为16.
以下是一些补充:
一个. 什么是字节对齐?为什么要对齐?
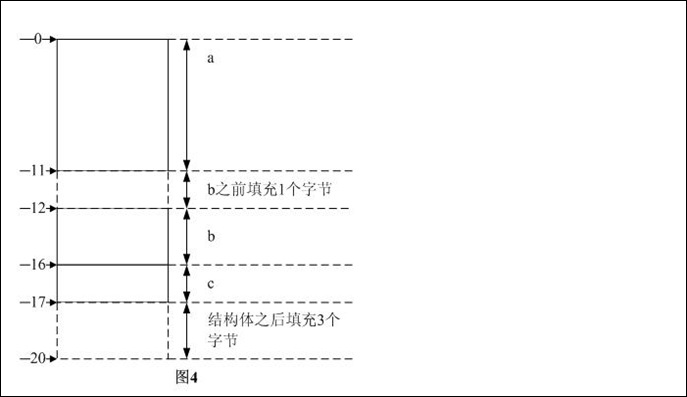
现代计算机中的内存空间按字节划分. 从理论上讲,对任何类型的变量的访问似乎都可以从任何地址开始,但是实际情况是,当访问特定类型的变量时,它通常位于特定的内存地址. 访问,它要求根据特定规则在空间中排列各种类型的数据,而不是一个接一个地排列,这就是对齐.
对齐的作用和原因: 每个硬件平台处理存储空间的方式都非常不同. 某些平台只能从某些地址访问某些类型的数据. 例如,某些体系结构的CPU在访问未对齐的变量时将遇到错误. 然后,在此架构下进行编程必须确保字节对齐. 其他平台可能没有这种情况,但是最常见的是如果它们不适合这种情况. 该平台需要对齐数据存储,这将导致访问效率下降. 例如,某些平台每次都从偶数地址开始. 如果将int类型(假定为32位系统)存储在偶数地址的开头,则可以在一个读取周期中读取32位,如果将其存储在奇数地址中,则在开始时需要2次读取周期,两次读取结果的高字节和低字节拼凑在一起,以获得32位数据. 显然,读取效率下降很多.
两个. 编译器遵循什么原则?
让我们首先看看四个重要的基本概念:
1. 数据类型本身的对齐值:
对于char型数据,其自身的对齐值为1,对于short型为2,对于int计算结构体大小,float和double型,其自对齐值为4,单位字节.
2. 结构或类的自对准值: 在其成员中具有最大自对准值的那个.
3. 指定对齐值: 指定对齐值时#pragma pack(值).
4. 数据成员,结构和类的有效对齐值: 自对齐值和指定的对齐值中较小的一个.
使用这些值,我们可以轻松地讨论特定数据结构的成员及其自身的对齐方式. 有效对齐值N是最终用于确定数据如何存储在地址中的值,并且是最重要的值. 有效地对齐N表示“对齐N”,这意味着数据的“存储起始地址%N = 0”. 数据结构中的数据变量按定义的顺序排列. 第一个数据变量的起始地址是数据结构的起始地址. 结构的成员变量应对齐并释放,并且结构本身应根据其自身的有效对齐值进行四舍五入(即,结构成员变量的总长度应为的有效对齐值的整数倍)的结构,并结合以下示例进行理解). 这使得无法理解上述示例的值.
示例分析:
分析示例B;
结构B
{
字符b;
int a;

short c;
};
假定B从地址空间0x0000开始. 在此示例中,未定义指定的对齐值. 在作者的环境中,该值默认为4. 第一个成员变量b的自对准值是1,小于指定的或默认指定的对准值4,因此其有效对准值为1,因此其存储地址0x0000符合0x0000%1 = 0. 第二个成员变量a,自对准值为4,因此有效对准值也为4,因此它只能存储在四个连续的字节空间中计算结构体大小,起始地址为0x0004至0x0007,重新检查0x0004%4 = 0,并且在第一个变量旁边. 第三个变量c,自对准值为2,因此有效对准值也为2,可以将其存储在两个字节空间0x0008至0x0009中,与0x0008%2 = 0一致. 因此,从0x0000到0x0009存储了B内容. 从数据结构B的自对准值来看,其变量(此处为b)的最大对准值为4,因此该结构的有效对准值也为4. 根据结构的圆度要求,从0x0009到0x0000 = 10字节(10 + 2)%4 = 0. 因此,结构B也占用了0x0000A到0x000B. 因此,B具有从0x0000到0x000B的12个字节,sizeof(struct B)= 12;实际上,如果是这种情况,它将满足字节对齐方式,因为其起始地址为0,因此必须对齐. 是的,之所以在后面添加2个字节是因为编译器为了实现结构数组的访问效率,想象一下,如果我们定义结构B的数组,那么第一个结构的起始地址为0,但是那又怎么样呢?第二种结构?根据数组的定义,数组中的所有元素都彼此相邻. 如果我们不将结构的大小加到4的整数倍,则下一个结构的起始地址将是0x0000A,这显然是无法满足该结构的地址对齐的,因此我们需要将该结构添加到有效对齐大小的整数倍. 实际上,例如: 对于char数据,其自身的对齐值是1,对于short类型是2,对于int,float类型,其自对齐值是4,而double自对齐值是8. 自对准值的类型也基于数组考虑,但是由于这些类型的长度已知,因此它们的自对准值也是已知的.
类似地,分析上面的示例C:
#pragma pack(2)/ *指定2字节对齐* /
结构C
{
字符b;
int a;
short c;
};
#pragma pack()/ *取消指定的对齐方式并恢复默认对齐方式* /
第一个变量b的自对准值是1,指定的对准值是2. 因此,其有效对准值是1. 假定C从0x0000开始,则b存储在0x0000,这是一致的0x0000%1 = 0;这两个变量的自对准值为4,指定的对准值为2,因此有效对准值为2,因此顺序存储在四个连续的字节0x0002、0x0003、0x0004、0x0005中,与0x0002%2一致= 0. 第三个变量c的自对准值为2,因此有效对准值为2,并按顺序存储
在0x0006、0x0007中,它是0x0006%2 = 0. 因此,从0x0000到0x00007总共有八个字节是C变量. 并且C的自对准值为4,因此C的有效对准值为2. 8%2 = 0,C仅占用从0x0000到0x0007的八个字节. 因此sizeof(struct C)= 8.
三个. 如何修改编译器的默认对齐值?
1. 在VC IDE中,可以对其进行如下修改: [Project] | [Settings],“ c / c ++”选项卡“ Category Code Generation”选项“ Struct Member Alignment Modification”,默认值为8个字节.
2. 编码时,您可以像这样动态修改它: #pragma pack.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-250173-1.html
 integration engineer_集成工程师_globalfoundries
integration engineer_集成工程师_globalfoundries 二叉排序树的建立_中序线索二叉树的建立_二叉树的建立流程图
二叉排序树的建立_中序线索二叉树的建立_二叉树的建立流程图 如何使用源代码构建网站(php网站源代码安装教程)
如何使用源代码构建网站(php网站源代码安装教程) 智能云平台为企业提供“私人管家”
智能云平台为企业提供“私人管家”
爱玩微博~~~~