Python搜寻器: 模拟登录知识的完整详细信息
电脑杂谈 发布时间:2020-06-08 05:12:40 来源:网络整理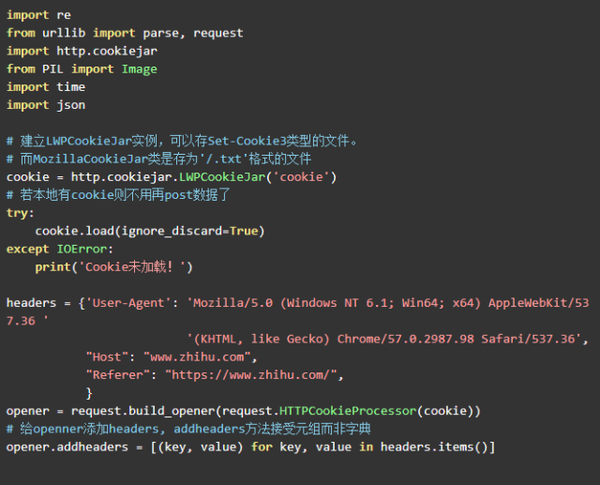
在过去的几天中,我一直在研究模拟登录,并以Zhihu分享您与世界的知识,经验和见解为例. 在实现过程中遇到很多问题,我学到了有关xchaoinfo的代码,非常感谢!
知道登录分为两种方式: 电子邮件登录和手机登录,您可以通过浏览器的开发人员工具进行检查. 当我们通过不同的方法登录时,URL是不同的. 电子邮件登录的地址为email_url ='zhihu.com / login / email'python模拟登录 爬虫,而手机的登录URL为phone_url ='zhihu.com / login / phone_num'.
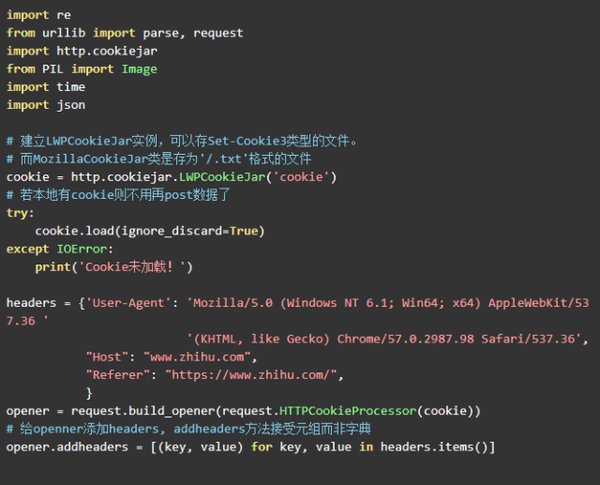
1. 创建一个可以传输Cookie的开启器
登录网站时,浏览器会提醒您是否保存帐户和密码信息,以便下次可以自动登录,省去了手动输入的麻烦. 这个过程实际上是将cookie保存在本地,并且浏览器将在下次登录时加载cookie数据,并实现自动登录. 默认的urllib.requst.urlopen()仅具有三个参数: url,data和timeout,并且不携带cookie之类的信息. http.cookiejar库可以很好地帮助我们. 有两类: CookieJar和FileCookieJar. 其中,CookieJar可以将cookie信息传递给变量,而其名称FileCookieJar可以将cookie保存到本地文件. 其中,FileCookieJar子类LWPCookieJar可以存储Set-Cookie3类型的文件,而MozillaCookieJar子类保存为/.txt格式的文件. 在这里,我使用LWPCookieJar.

这将创建一个可以保存cookie的实例对象. 它还有一个load()方法可以在本地加载存储的cookie数据python模拟登录 爬虫,这类似于浏览器为我们自动登录所执行的操作,因此我们无需将所需数据登录到网站POST.

参数ignore_discard = True表示保存cookie,即使它们将被丢弃. 它还具有另一个参数igonre_expires,以指示当前数据将覆盖原始文件.
现在创建一个可以处理cookie的开启器.

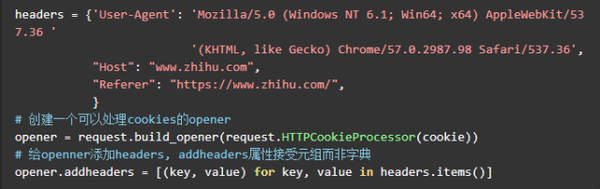
接下来,我们可以使用opener.open()来传递url和数据.
2. 获取登录所需的关键参数
模拟登录名知道,除了发布自己的帐户密码外,还有两个动态生成的参数,一个是_xsrf,另一个是烦人的验证码. 输入帐户密码后,我们通过开发人员工具找到了一个名为email的json文件. 请求方法是POST,我们可以看到它的域名是zhihu.com/login/email. 我使用Firefox开发人员工具打开了该文件. 请参阅其中的参数.
标题下的表单数据似乎对应于chrome. 如果找到它,请检查网络中的保留日志.

在这里,我已经为我的电子邮件和密码编码了,呵呵.
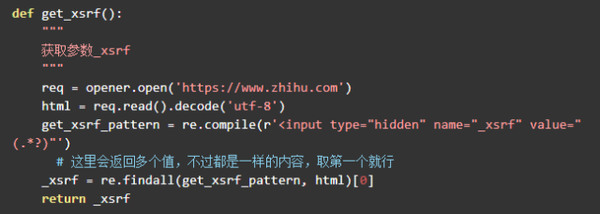
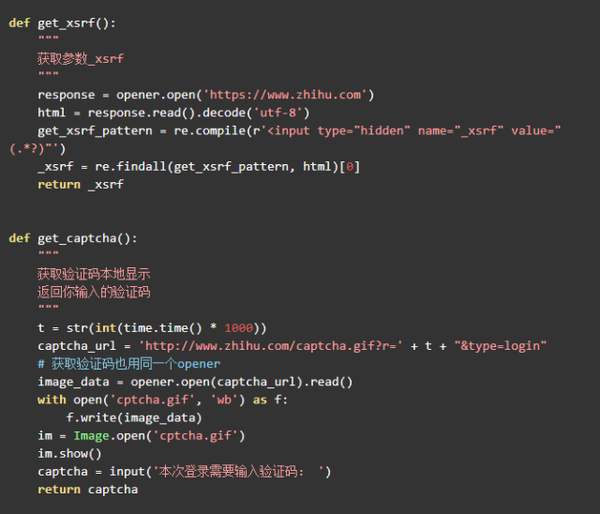
获取_xsrf
此参数会动态更改,因此一旦无法获取,它将一劳永逸. 从html正文中搜索_xsrf,然后使用正则表达式进行匹配.

获取验证码
尽管我现在知道登录很少需要输入验证码(无论如何,我很少),但是当您遇到登录时,如果没有post参数,就无法成功登录.
Zhuhu的验证码开始给我带来麻烦. 搜索可在html内容页面中看到验证码图片的URL,但实际上使用xxx.read(). decode('utf-8')来获取它. 网页的内容没有此URL,它隐藏!好狡猾. 这项研究没有成果,我不得不进行搜索. 我从知道这个问题的xchaoinfo的答案中找到了答案. 结果是图像URL中的数字字符串是一个时间戳.
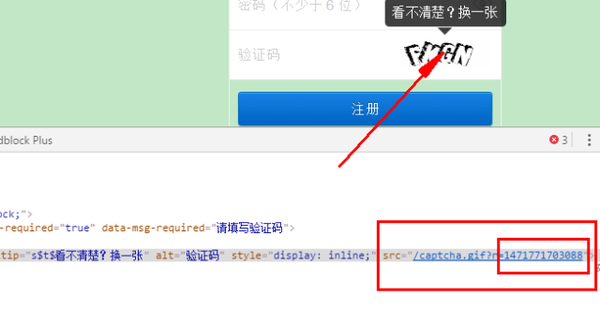
时间戳是指从1970年1月1日格林威治标准时间00:00:00(北京时间1970年1月1日08:00: 00)到现在的总秒数.
您可以通过time.time()查看当前时间戳. 例如,我现在是1471771678.5400066,看它是否非常靠近上面的红色框!通过转换关系t = time.time()* 1000,可以获得图片链接的关键部分,其余部分保持不变. 验证码的完整地址为captcha_url ='zhihu.com / captcha.gif?r ='+ t +“&type = login”. 好的,链接是已知的,只需下载,查看并手动输入即可. 这篇文章之后,您应该能够成功登录,感到非常兴奋.

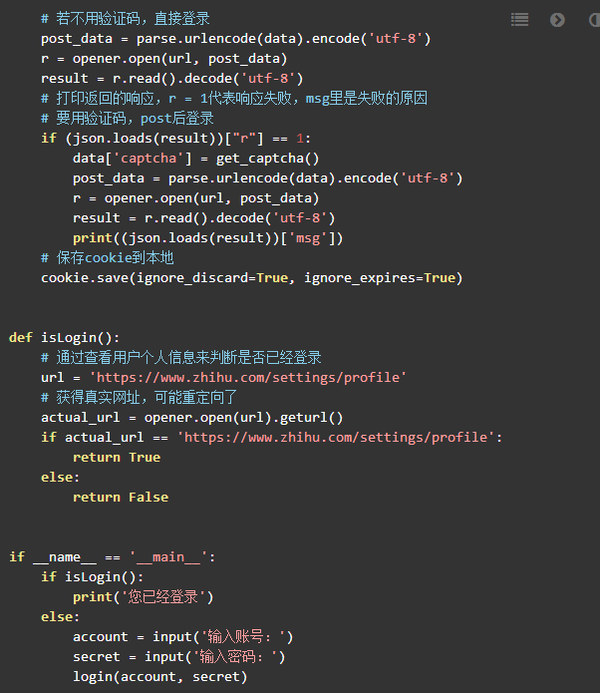
3. 尝试模拟登录知识

我们已经获得了两个关键的东西. 立即登录并尝试!考虑到登录方式,如果检测到输入手机号,我们应该访问手机登录URL;否则是邮箱登录.

关于句子print((json.loads(result))['msg']),打开程序携带过去的数据,从请求URL获得的响应将返回登录信息. 数据是json类型,如果要查看它的话上面的语句,eval()函数也是可能的. 一开始,我总是无法登录. 回到这样的事情!

请注意,登录是一个连贯的过程. 在此过程中,我们总共访问了URL 3次,并且必须确保使用相同的打开程序来获取动态参数,获取验证码并最终模拟登录. 这也是登录失败的原因之一,因为urlopen()用于获取_xsrf和验证代码. urllib标准库不是很强大,您可以尝试使用请求库,这将使过程变得简单.
查看结果. 如果登录成功,则可以访问以下个人信息的URL. 如果登录失败,则无法查看,它将返回登录界面的URL.
页面
好的,这种模拟登录比前两项研究更加困难. 许多问题必须通过搜索解决. 来吧.
所有代码都发布在这里.


更新
我今天阅读了请求文件. 阅读urllib库并再次阅读它并不难. 我使用请求的最基本功能来重新实现上述功能,当然,大多数代码都是重复的.
requests.get()与urllib.request.urlopen()类似. 如果名称是由get请求的,则它将接收url,字典样式的标头,超时,allow_redirects和其他参数,当然,requests.post(),您可以传入data参数,这与urllib不同,您需要对数据进行编码字典形式,请求将被自动处理,数据可以json数据形式传递.
allow_redirects此参数可以为True或False. 默认值为True. 如果选择False,则禁止重定向. 据我了解,禁止自动重定向.
看看两个库之间的区别. 响应可以作为可选的文本和内容返回,其中文本作为文本返回,而内容作为二进制数据返回. 例如,如果我们请求的URL是图像,则返回内容,您可以使用以wb模式写入文件. 查看这两个库在实现返回的网页内容方面的区别. 顺便说一句,返回的对象(例如响应)还具有status_code访问成功的属性,当然会返回200.

然后是具有相同大写字母的requests.Session()或requests.session(). 我不知道有什么区别. 看类型是一个类'requests.sessions.Session'这样的类. request.Session()将创建一个新会话,该会话可以连接同一用户的不同请求,并且将自动处理cookie直到会话结束,这比urllib方便得多. 如果每次独立访问网页时仅使用request.get()或request.post(),则它不会与当前用户的多次访问相关联,因此模拟登录需要request.Session(). 然后使用新会话使用post(),get()和其他函数. 如下.

本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-237973-1.html
 联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统
联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统 结构关系模型 华人娱乐网
结构关系模型 华人娱乐网 松原激光烧结尼龙,工业3D打印机
松原激光烧结尼龙,工业3D打印机 Photoshop19 32位下载19.1.2 Lite Lite破解版
Photoshop19 32位下载19.1.2 Lite Lite破解版
真够恶心的