最佳二叉搜索树
电脑杂谈 发布时间:2020-06-03 17:05:48 来源:网络整理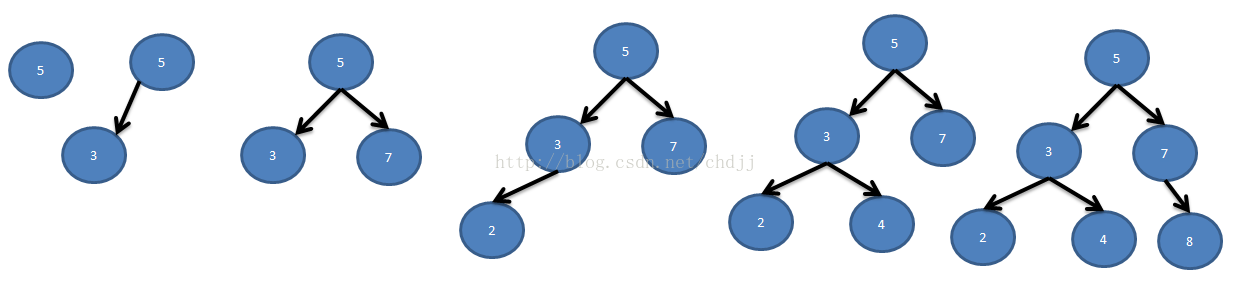
最佳二叉搜索树:
给定一个由n个不同的关键字K = 知道每个关键字和虚拟关键字被搜索的概率,可以计算给定二进制搜索树中的预期搜索成本. 假设搜索的实际成本是检查的节点数,即发现的节点的深度加1. 计算预期搜索成本的公式为: 建立一个二叉搜索树并期望搜索成本最小,那么该二叉搜索树就是最佳的二叉搜索树. 也: 最佳子结构: 如果最优二叉搜索树T具有包含关键字ki,...,kj的子树T',则该用于关键字Ki,...,kj和虚拟关键字的子树T' di-1,... dj也必须是最优的. 给定关键字ki,...,kj,假定kr(i <= r <= j)是包含这些关键字的最优子树的根. 左子树包含关键字ki,...,kr-1和虚拟键di-1,...,dr-1,右子树包含关键字kr + 1,...,kj和虚拟键dr ,... dj. 我们检查所有候选根kr,以确保找到最佳的二叉搜索树. 递归解决方案: 将e [i,j]定义为包含关键字ki,...,kj的最佳二叉搜索树的预期成本. 最终计算结果为e [1,n]. 当j = i-1时,子树中只有虚拟键,并且预期搜索成本为e [i,i-1] = qi-1. 当j> = i时,您需要从ki,...,kj中选择一个根kr,然后分别构造其左子树和右子树. 接下来,我们需要计算以kr为根的树的预期搜索成本. 然后选择导致最低预期搜索成本的kr作为根. 子树中每个节点的深度增加1. 预期的搜索成本增加是子树中所有概率的总和. 对于关键字为ki,...,kj的子树,所有概率之和为: 以kr为根的子树的预期搜索成本为: 注意: 因此e [i] [j]可以重写为: 最后可用的递归公式: 实施代码:

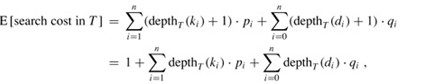

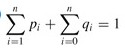


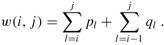



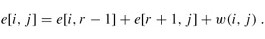
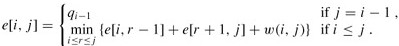
package obst;
/**
*最优二叉搜索树
*@author wxisme
*@time 2015-10-22 下午8:06:04
*/
public class Solve_obst {
public static int[][] e;
public static int[][] w;
public static int[] p;
public static int[] q;
public static int[][] root;
public static void optional_bst() {
int n = p.length+1;
e = new int[n+1][n];
w = new int[n+1][n];
root = new int[n][n];
for(int i=1; i<=n; i++) {
e[i][i-1] = q[i-1];
w[i][i-1] = q[i-1];
}
for(int l=1; l<=n; l++) {
for(int i=l; i<=n-l+1; i++) {
int j = i+l-1;
e[i][j] = Integer.MAX_VALUE;
w[i][j] = w[i][j-1] + p[i] +q[j];
for(int r=i; r<=j; r++) {
int t = w[i][r-1] + e[r+1][j] + w[i][j];
if(t < e[i][j]) {
e[i][j] = t;
root[i][j] = r;
}
}
}
}
}
}
水平旋转e,w的对角线. 如下图所示:
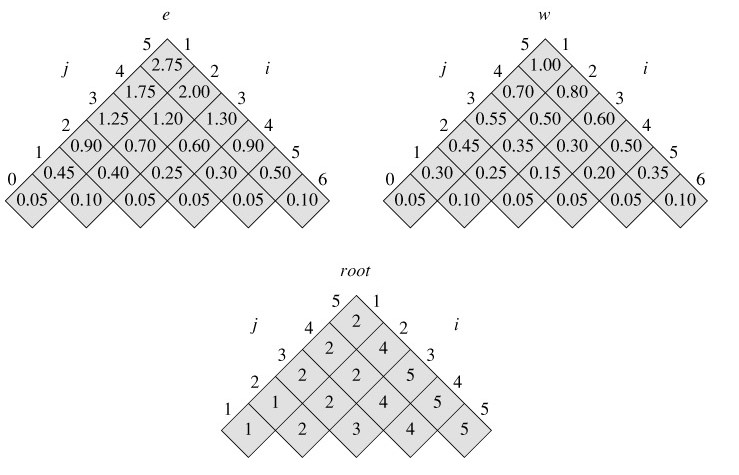
时间复杂度为O(n ^ 3)
FROM算法简介
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-232595-1.html
 win10 系统还原 这 9 款优秀的 Windows 国产应用,让你的 PC 更
win10 系统还原 这 9 款优秀的 Windows 国产应用,让你的 PC 更 英国最快的超级计算机的秘密: 每秒100万亿次操作
英国最快的超级计算机的秘密: 每秒100万亿次操作 gitforvs2012插件
gitforvs2012插件 如何在C ++中实现Trim函数,删除字符串前后的所有空格
如何在C ++中实现Trim函数,删除字符串前后的所有空格
否则美国实在受不了这个刺激会发疯的