memsql_memsql olap_memsql 5
电脑杂谈 发布时间:2016-12-22 00:01:28 来源:网络整理
MemSQL的分布式架构被设计为直接的、简单的并且快速的。这里概述了MemSQL集群,包括各式组件的交互。同时介绍了当你执行一个查询或者管理操作的时候,MemSQL环境发生了什么。
1、Aggregators(汇聚器) MemSQL集群的一种节点,为访问MemSQL集群的网关,一个集群中可以有多个汇聚器,汇聚器主要负责向叶子节点发送DML请求、汇聚操作结果并返回给客户端
2、Master Aggregator(主汇聚器)是一种特殊的汇聚器,除了一般汇聚器的功能,还负责监控集群、失效切换及DDL语句的操作。每一个MemSQL的集群只能有一个主汇聚器。当主汇聚器失效时,MemSQL的集群和DDL语句操作将被挂起,而一般的DML语句仍可以通过其他的汇聚器进行操作。如果主汇聚器的程序文件没有丢失,那么只要重启一下主汇聚器即可,主汇聚器将会自动重连。否则的话,可以在一个子汇聚器上执行命令来将子汇聚器提升为主汇聚器。
3、Leaf Node(叶子节点)在MemSQL集群中,叶子节点的作用是存储和计算。memsql负责在集群中存储数据的切片。为了优化性能,MemSQL会围绕叶子节点自动分布数据到分区。每一个叶子节点由若干个分区组成。每一个分区其实就是一个database。
4、Partitions(分区) 一个叶子节点由多个分区组成。每一个分区其实就是一个database。比如说,如有你创建了一个database名为test,那么当你在一个叶子节点执行SHOW DATABASES时,会看到名为类似test_5,表明这是分区5。通过SHOWDATABASESEXTENDED命令输出的State列,可以查看分区是Master或者slave分区或者正处于其他状态的分区。Master分区是真正执行操作的分区,而slave分区则是通过网络和sql操作将Master上的数据复制到slave上。另外,slave分区是只读的。
MemSQL分布式系统的设计遵循如下的原则:
性能优先 MemSQL是世界上最快的single-box,分布式部署在多台服务器上时更是能让性能有线性的提升。MemSQL集群能够处理每秒数十亿行数据,而硬件只需要普通的商用硬件即可。
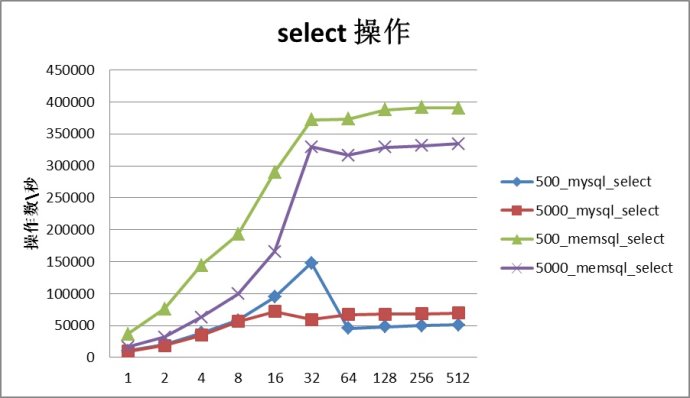
将集群分为汇聚层和叶子层同时尽可能多的将工作交由叶子层处理这允许你增加额外的叶子节点到集群来提升集群容量和查询性能
无单点失败风险通过运行冗余的集群,可以确保每一个数据分区都有一个热备份。当叶子节点失效时,MemSQL将自动切换到salve分区。汇聚层同样也有类似的技术来规避单节点风险。
强大但又简单的集群管理 分布式系统提供了REBALANCE PARTITIONS功能来恢复分区数据
没有隐式的数据移动
一个MemSQL集群由两个层面组成:
汇聚器 汇聚器处理分布式系统的元数据,路由查询并汇聚结果。依赖于查询量,一个集群可能有一个或者多个汇聚器。memsql主汇聚器是一个特殊的汇聚器,只处理元数据并负责集群的监控和失效切换
叶子节点 叶子节点存储和执行sql查询。一个叶子节点是一个由多个分区组成的MemSQL服务实例。
汇聚器和叶子节点共享同一套MemSQL的二进制程序文件,因此你在集群中部署时可以完全相同。默认的话MemSQL只会作为叶子节点来运行。要运行MemSQL作为一个汇聚器,需要使用./memsqld --master-aggregator来指定主汇聚器。
MemSQL集群最小安装只需要一个主汇聚器和一个叶子几点即可。你可以添加更多的汇聚器,这些汇聚器会从主汇聚器读取元素据,也能够在叶子节点运行DML命令
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-23187-1.html
-

-
胡舜陟
这个只有对的方向才是最好的不是吗
-
钱闪闪
宝宝美哭
 发表论文需要审稿费吗 官方通报107篇论文被撤稿:涉521人 正依规处理
发表论文需要审稿费吗 官方通报107篇论文被撤稿:涉521人 正依规处理 对毕业论文的重复率有要求吗?
对毕业论文的重复率有要求吗? OpenCV学习(13)改进算法(1)
OpenCV学习(13)改进算法(1) 面向将来的计算方式普适计算与云计算报告人ppt下载
面向将来的计算方式普适计算与云计算报告人ppt下载
康师傅在大陆确实赚的太多太多