分布式内存计算简介: 定义,目的和原理
电脑杂谈 发布时间:2020-05-29 03:27:59 来源:网络整理
在“混合建模”系列的上一篇文章中,我们讨论了共享内存计算的基础知识: 什么是共享内存,为什么使用共享内存以及COMSOL软件如何在计算中使用共享内存. 今天,我们将讨论混合并行计算的另一个组件: 分布式内存计算.
在阅读上一篇博客后,我们了解到共享内存计算是指将程序的任务划分为多个较小的工作单元,这些工作单元可以在节点(即线程)中并行运行. 这些线程共享对内存的特定部分的访问,因此称为共享内存计算. 相反,分布式内存计算的并行进程是由多个进程(执行多个线程)完成的. 每个进程都有自己的内存空间,其他进程无法访问它. 在分布式内存方法中,这些进程分布在多台计算机,多个处理器和/或多个内核之间,以形成并行程序.
简而言之,内存不再共享,而是分配给每个进程(请参阅本系列第一个博客中的图表).
要了解分布式计算的设计意图,让我们首先了解集群计算的基本概念. 计算机的内存和计算能力受到限制. 为了提高性能并增加可用内存量,科学家开始将多台计算机连接在一起以形成所谓的计算机集群.
物理过程是通过计算机集群分布的. 这种方法将并行问题的复杂性提高到一个新的水平. 每个问题都必须划分为较小的单元-不仅需要划分数据,而且还必须将相应的任务分配给每台计算机. 以矩阵问题为例,当执行巨大的数组操作时,该数组可以分为多个块(可能是不连续的或重叠的),并且每个私有块专门负责一个过程. 当然,每个块上的操作和数据可以与其他块上的操作和数据耦合,因此有必要在进程之间引入一种通信机制.

为了实现通信,将其他进程所需的数据或信息收集到数据块中,然后通过发送消息与其他进程交换数据. 此方法称为消息传递,并且该模式可以是全局交换(多对多,多对一,一对多)或点对点交换(一个点发送过程,一个点接收过程) . 根据整个问题的耦合程度,消息交换可能需要大量的沟通.
人们希望尽可能地在本地处理数据并执行计算,以最大程度地减少流量.
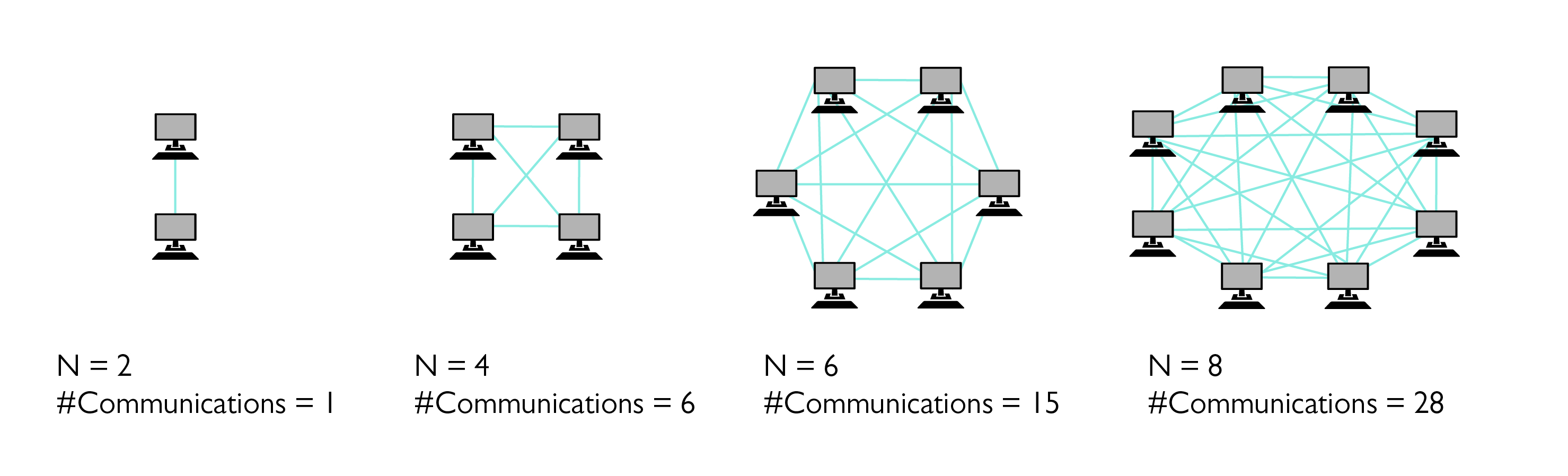
完整图片描述了需要多对多发送的消息数. 消息数和使用的计算节点数具有二次函数关系.
使用计算机集群时,科学家可以通过两种方式从其他资源中受益:
首先,由于内存增加和计算能力增强,科学家可以解决更大的问题. 具体而言,一方面,添加了附加的处理,另一方面,使每个处理的工作量(子问题的大小和操作数)保持恒定,从而解决了处理中的较大问题. 同时. 这称为弱扩展.
第二,科学家可以将原始问题划分为更多和较小的子问题,并将其分配给更多的过程,同时保持整体问题的大小不变. 这样,可以减少每个进程的工作量,并可以更快地完成任务. 在最佳情况下,如果将固定比例的问题分配给P个过程,则计算速度将增加P倍. 与每单位时间(一小时,一天等)运行一次仿真相比,第二种方法允许每单位时间运行P个仿真. 这种方法称为强扩展.
简而言之,分布式内存计算可以帮助您同时解决较大的问题,或者缩短解决同一问题的时间.
接下来,我们将讨论消息传递的详细信息. 流程如何知道程序的其他部分正在执行哪些任务?如上所述,该过程必须发送和接收其他处理器或自身需要的信息和变量. 此过程反过来给系统带来一些缺陷. 突出的问题是,通过网络发送消息必须消耗大量的额外时间.
举个比喻,我们可以回想一下简介: 与会者围绕一个圆桌会议进行了协作. 所有信息均免费提供给桌上的每个参与者. 他们可以自由获取和编辑文件,甚至可以并行工作. 在本文中,会议室和桌子被单个办公室代替,员工坐在办公室里处理他们面前的文件.

在新方案中,名为Alice的一名员工修改了报表A. 她想提醒同事Bob并将更改传达给他. 现在她需要停止工作,离开办公室,步行到Bob的办公室,将新信息交给他,然后返回办公桌继续工作. 这比将一张纸直接传递给同一会议室中的另一方要麻烦得多. 最糟糕的部分是,爱丽丝必须花比修改本身更长的时间来提醒同事她已经进行了修改.
在新的类比中,通信过程可能会成为系统的瓶颈,从而减慢总体工作进度. 如果我们计划减少必要的通信量(或加快通信速度,例如在办公室中安装电话或更有效的通信网络)分布式计算原理是什么,则可以缩短消息传递的等待时间,并留出更多时间来计算数值模拟. 对于分布式内存计算,瓶颈通常是在流程之间传输电子数据的技术. 您也可以直接将其理解为节点之间的联系. 目前,可以实现高吞吐量和低延迟的行业标准是Infiniband,并且使用Infiniband技术传输消息的效率远远高于以太网.
分布式内存计算具有许多优点. 优点之一与共享内存相同. 那就是增强系统的计算能力. 无论我们在集群中添加内核,套接字还是节点,我们都可以启动更多进程并充分利用新添加的资源. 使用更强大的计算能力,我们可以更快地获得仿真结果.
使用分布式内存的另一个好处是,每当我们向集群添加一个计算节点时,我们将获得更多的可用内存. 这意味着我们不再局限于主板分配的内存空间,因此从理论上讲我们可以计算任意大的模型. 在大多数情况下,分布式内存计算比共享内存计算更具可伸缩性,这意味着在加速比达到饱和之前,可以使用的进程数(与可以使用的线程数相比)要大得多.
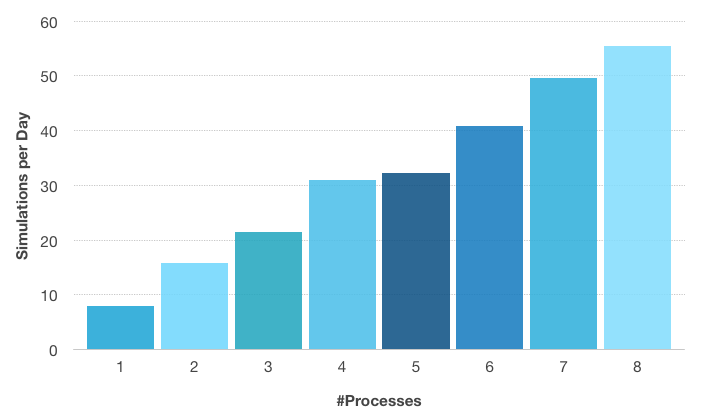

垂直轴: 下图中穿孔模型每天的模拟次数. 水平轴: 使用的进程数. 通信网络使用千兆以太网. 前四个进程在计算节点上执行,直到第四个进程才使用以太网. 在仿真中,第四和第五过程之间的差异很小,这表明即使对于参数设置问题,慢速的通信网络仍然会产生重大影响. 使用的计算节点配备了Intel®Xeon®E5-2609和1600 MHz @ 1600 MHz的DDR3.
但是,我们还必须认识到分布式内存的局限性. 与共享内存的情况一样,某些问题非常适合使用分布式内存进行计算,而某些问题则不合适. 另外,除了问题是否易于并行化之外,我们还需要考虑问题解决过程所需的沟通量.
我们以瞬态问题为例. 在这个问题中,大量的粒子相互作用. 当系统完成操作步骤时,所有粒子都需要获取有关其他粒子的信息. 假设每个粒子是通过其自己的排他过程计算的,则本示例生成的流量可以用完整的图来描述(请参见第一张图片),并且每次迭代的消息数将随粒子数和流程迅速增加. 相比之下,参数化扫描中的参数值可以独立计算分布式计算原理是什么,几乎不需要通信,因此通信瓶颈将其限制为相对较小.
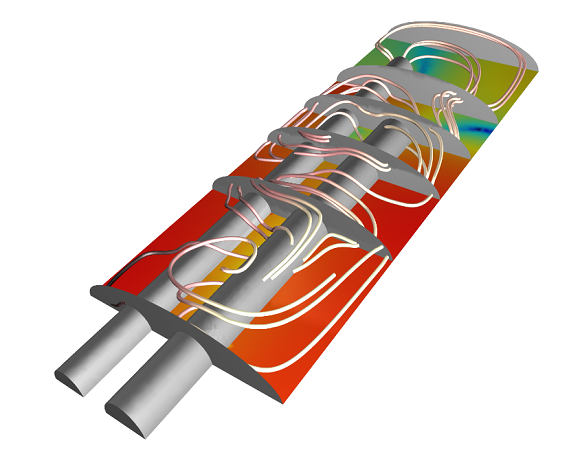
用于测试加速比的模型. 这是一个小的参数模型(自由度为750,000),可以使用PARDISO直接求解器进行求解. 可以在“案例下载”中获得该模型.
有权访问网络浮动许可证(FNL)的用户可以在单个多处理器单机,集群甚至是云中使用COMSOL软件的分布式处理功能. 默认情况下,COMSOL软件的求解器以分布式模式运行,不需要其他设置. 因此,您可以同时运行较大的仿真,也可以更快地完成相同大小的仿真. 无论哪种方式,COMSOL Multiphysics都可以帮助您提高生产率.
COMSOL的分布式处理功能在计算参数扫描时也可以发挥重要作用. 您可以为打开COMSOL Multiphysics时启动的每个过程自动分配使用不同参数值的解决方案过程. 因为在这些参数化扫描中,这些求解过程可以彼此独立地计算,所以它们被称为“令人尴尬的并行问题”. 在一个好的Internet网络中,加速比基本上等于进程数.
如果您想了解有关分布式内存计算的更多信息,建议您阅读《 COMSOL参考手册》. 该手册列出了如何以分布式模式启动COMSOL的几个示例. 如果您想了解有关如何提交计算任务的更多信息,还可以参考高性能计算(HPC)群集的用户指南.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-225985-1.html
-

-
赵雨萌
方便面是人家日本人发明的
-
郑庶
有勇有茅
 什么是python转义字符?看看人士如何理解它.
什么是python转义字符?看看人士如何理解它. 各种类型的网络的清单和三种常见的攻击方法
各种类型的网络的清单和三种常见的攻击方法 excel2003打开2007打开excel2007的表格打开很慢的解决方法
excel2003打开2007打开excel2007的表格打开很慢的解决方法 微型计算机杂志是核心期刊吗?
微型计算机杂志是核心期刊吗?
但是你也要说的和做的一样