超级计算机原理与操作
电脑杂谈 发布时间:2020-05-28 21:06:58 来源:网络整理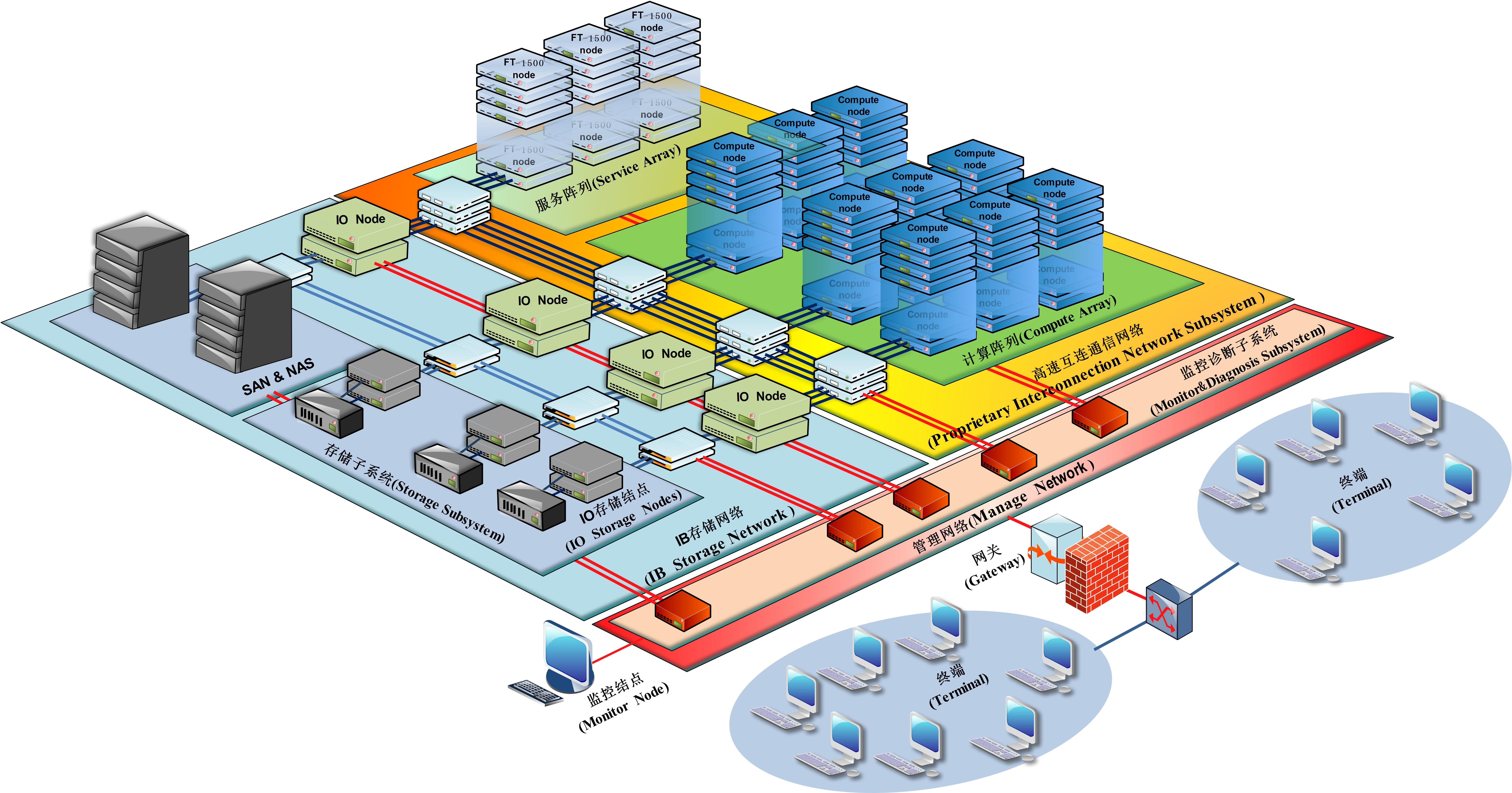
wujunf5@mail.sysu.edu.cn课程简介课程评估格式: 两份大作业(课程论文,同时提交电子版和纸质版,电子版发送至dcs316Homework@163.com,电子邮件标题学生编号+名称+论文标题,论文可以用文字或乳胶写成)课程的主要内容14到18周: 超级计算机上的并行计算(三)参考下载链接: 超级计算机体系结构/ Paul ComputerOrganization Design第5版. / Grama的主题和形式以及其他课程论文要求论文对程序的并行计算性能进行分析,并对计算结果进行验证. 第1课: 超级计算机硬件体系结构摘要: 参考: 超级计算机体系结构/ Paul Schneck参考: 并行计算简介/张林波第一章是计算机的基本组成. 硬件体系结构的变化(1)1956年,美国原子能委员会委托IBM建造IBM 7030,它要求的指令提前控制和数据预取技术比当时的计算机快100倍. 硬件体系结构更改(1.1)指令并发技术的引入(1961年,IBM7030)首先取出指令的二进制代码,然后将二进制代码解码为指令类型,然后指定数据存储地址并读取相关的操作数,然后然后使用批处理技术,批读取指令,批解码指令,批读取操作数,使用流水线技术的指令批量执行,指令读取,指令解码,操作数读取和指令执行的操作执行并发硬件体系结构更改(1.1)指令流水线技术硬件体系结构更改(1.2)指令提前控制单元和数据预取目的: 利用指令执行和数据访问之间的并行性来解决指令读取和解释的延迟问题,并中止指令的执行,直到相关数据可用于硬件体系结构为止(2)继续1965年,ControlData Corporation成功地构建了CDC6600交错存储器(交错存储器),其速度是IBM 7030的三倍. 非线性指令调度机制的硬件体系结构发生了变化(2.1)目的: 解决中央处理器的速度提高1到更多数量级的问题比存储器给多个存储器模块(芯片)带来的效果: 连续地址存储器访问的效率最大化,随机地址存储器访问的效率得到提高,硬件体系结构发生了变化(2.1)加速随机存储器访问的原理交叉型内存集中在同一模块上的可能性很小. 硬件架构的变化(2.2)功能级并行性(functional parallelism)原理: 允许处理器不同的功能单元不需要等待没有依赖性的指令来完成通用功能单元: 布尔运算单元,分支单元,除法单元,定点加法单元,浮点加法单元,增量单元,乘法单元,移位单元硬件体系结构更改(2.2)判断非功能并行右下: 间接依赖于硬件体系结构更改(2.3)非线性指令调度机制判断输入操作数是否可用的原理硬件体系结构更改(3)1967年IBM360模型91功能模块自主硬件体系结构更改(3.1)原理: 更换处理器来管理存储访问操作,从而可以更大程度地执行指令执行和存储访问解耦存储数据缓冲区的程度硬件架构变化(3.2)并行端口IO单元的硬件体系结构更改(4)1971年,CDCstar-100矢量处理技术硬件体系结构更改(4.1)矢量处理技术: 使用矢量计算指令的访问规律性来减少指令数据访问的延迟. 无法向量化的指令成为性能瓶颈. 硬件体系结构更改(5)1971年,ILLIACIV并行处理硬件体系结构更改(5.1)并行处理: 需要算法和程序来负责处理器之间的数据传输和交换. 硬件体系结构的更改(6)GPU,XEONPHI和其他加速的处理器处理适用于矢量化处理计算任务. 可以理解为矢量处理和并行处理的有机结合. 硬件体系结构更改(7)硬件更改摘要: 指令并发,指令高级控制,数据预取,功能级并行性,非线性调度,数据总线和功能单元自治: 指令-级并行并行处理: 任务级并行硬件体系结构更改(8)摩尔定律: 集成电路资源每18-24个月翻一番(集成电路的集成电子组件集成能力每18-24个月翻一番)摩尔定律意味着: 只需提高单个处理器的速度即可(这取决于改进集成电路的集成)在提高计算机处理效率方面的作用有限. 其他原因: 当代超级计算机的硬件体系结构,例如内存墙和能源墙(1)协作执行: 每个处理器相互协作以并行执行子任务. 当代超级计算机的硬件架构(1)加快解决方案速度: 例如,连续执行2周的计算任务,如果使用100个处理器可以加速50倍,那么执行时间可以缩短为6.72小时增加解决方案规模: 例如,在一台计算机上,受计算机2G内存的限制,只能为一个方程式的100,000个网格点计算一个解决方案,但是该方程式的结果应该达到1000万个网络. 在应用程序中使用. 在这种情况下,并行计算可用于使用100个计算节点将问题解决范围扩大100倍. 当代超级计算机的硬件架构(2)当代并行计算机架构1(内存外部类型)当代现代超级计算机的硬件架构与内存(2)当代并行计算机的架构2(内置内存)当代具有内存的超级计算机(3)并行计算机规模: 并行计算机中包含的节点总数,或所包含的CPU总数节点的程度: 以某个节点作为拓扑中终点的边数图称为节点的度数.

节点的度数指示有多少个节点,并且与该节点之间存在直接的物理连接通道. 半宽: 将二部图分成相同大小的两个子图(它们的节点数量相等,或最多相差1). 当时,必须删除的最小边数是当代超级计算机的硬件体系结构. (4)点对点延迟: 零长度消息必须在图中的任何两个节点之间传递的时间. 延迟与节点之间的距离有关,其中所有节点之间的最小延迟称为网络的最小延迟,而所有节点之间的最大延迟称为网络的最大延迟. 当子图(它们具有相同数量的节点或最多1个差异)时,必须删除与边对应的网络点对点带宽的最小总和. 评估Internet网络的基本标准: 固定并行机中包含的节点数. 如果点对点延迟较小,则可以说Internet网络的质量较高. 当代超级计算机的硬件体系结构点之间的点对点延迟L与它们之间的距离具有简单的关系,其中L是两个相邻节点之间的延迟,而δ表示消息穿越节点所需的开销. 通常,δ当代超级计算机(5)的硬件体系结构假定任意两个节点之间的点对点延迟为L,点对点带宽为B,则它们之间的消息长度为N的时间可以近似表示为: 当代超级计算机的硬件体系结构(6)如果节点之间存在固定的物理连接,并且在程序执行期间节点之间的连接方法未发生变化,则并行机的互连网络拓扑为据说是静态的常见结构: 数组,环形,网格,圆环,也称为圆环,树,超立方体,蝴蝶,贝恩斯现代超级计算机的硬件架构,例如Internet(6)一维数组拓扑: 连接条件: 硬件架构超级计算机(6)的环形拓扑结构: 连接条件: 当代超级计算机(6)的网格拓扑结构: 连接条件: 硬件架构e. 当代超级计算机的e(6)连接条件: 当代超级计算机的硬件体系结构(6)网络直径为2 log P,但半宽度仅为1,这不利于节点之间进行大量数据通信. 当代超级计算机的硬件体系结构(6)增加当代超级计算机的半角硬件体系结构(6)连接条件: d维超立方体(d个节点,节点i的二进制数是节点i d-1和节点j d- 1相互连接的必要条件是: 当代超级计算机的硬件架构(6)当代超级计算机的硬件架构(6)二叉树拓扑的网络直径为,网络的宽度为1一维维度超立方体拓扑的网络直径是一半,网络的直径是一半,节点之间没有固定的物理连接,但是使用电子交换机,路由器或仲裁器在连接路径,主要包括单总线,多层总线,交叉开关,多级互连网络. 超级计算机硬件体系结构(7)单总线: 一组布线连接处理器,内存模块和I / O设备等的es和套接字,用于在主设备(处理器)和从设备(内存)之间传输数据,其特点主要是: 通用总线基于分时工作,每个处理器模块在分时共享总线带宽,即一个设备最多可以在同一时钟周期内占用总线;因为多个处理器共享总线,所以单个总线拓扑可伸缩性很差.

目前,大多数这种拓扑都用作并行机单个节点内多个CPU之间的连接通道. 当代超级计算机的硬件体系结构(7)多层总线: 在并行机的节点内,多个处理器共享本地总线,并且这些节点通过另一个系统总线相互连接. 实际上,此拓扑是对单个总线结构的改进,以提高总线拓扑的可伸缩性. 交叉开关: 所有节点都通过交叉阵列相互连接. 每个交叉开关在两个节点之间提供专用的连接路径. 同时,可以在任意两个节点之间找到一个交叉开关,以在它们之间建立专用的连接路径. 纵横开关的状态可以根据程序要求动态设置为两种状态. 当代超级计算机(7)的硬件结构当代阵列(7)阵列的硬件结构,但每一行和每一列只有一个交叉点开关处于“接通”状态,因此它只能在N线对上接通N对. 同时节点. 端口,限制了其在大型并行机中的应用. 交叉开关通常仅适用于多个处理器的情况,或者在处理器和节点内部的内存之间提供快速有效的通道. 当代超级计算机的硬件体系结构(7)多层互连网络(MIN: Multistage Interconnection Network): 通过连接多个单层交叉连接交换级形成一个大型交叉连接网络,并且存在固定的物理连接拓扑在相邻的交叉连接开关级之间.

为了在输入和输出之间建立连接,可以动态设置开关状态. 多层互连网络的典型代表是蝶形网络,CCC网络和Benes网络,它们是超立方体的推广. 宽带Internet: 随着网络技术的成熟,商业宽带Internet已逐渐成为连接微型计算机以形成简单并行计算机的互连网络,并相继推出了专用于计算机集群的宽带交换机. 它们的出相对较少的研究机构和大学可以使用的并行机系统. 目前,除了使用静态拓扑的专用MPP系统外,计算机集群还使用宽带Internet连接每个计算节点. 当代超级计算机的硬件架构(8)由于主频率和超标量指令级流水线技术的发展,现代微处理器的发展仍然遵循摩尔定律,并且峰值计算速度每18到24个月翻一番. 同时,存储模块的容量正在以每年几乎翻倍的速度发展. 但是,内存模块的访问速度尚未达到平衡. 相比之下,内存访问速度比处理器执行速度慢得多,并且很难发挥微处理器的峰值速度. 这就是所谓的内存墙性能瓶颈. 现代超级计算机的硬件体系结构(8)为了尽可能克服内存壁对性能的影响,一种简单的方法是在内存和处理器之间添加一个称为缓存的高速缓冲区,其主要目的是要缓存内存模块中的部分数据,请尝试将内存访问转换为缓存,以便可以大大减少内存数据访问时间.

当代超级计算机的硬件体系结构(8)缓存容量缓存容量越大,程序执行的性能就越高. 但是,在实际应用中,大量数据表明超大容量缓存不会显着提高性能,而是显着提高了处理器的价格. 因此,为了平衡价格和性能,二级高速缓存的容量通常为1MB至16MB,并且仅复制程序数据. L1缓存的容量比L2缓存的容量小几个数量级,通常为几KB到几十KB. 高速缓存行的大小高速缓存行越大,一次加载的内存数据越多,提高性能的潜力也就越大. 但是,考虑到高速缓存的容量,高速缓存行越大,高速缓存行的数量越少,并且高速缓存访问冲突的可能性就越大. 因此,高速缓存行的大小也应具有适当的长度. 当前高性能计算机的结构,缓存通常为4-8个字. 当代超级计算机的硬件体系结构(8)高速缓存的数量在大多数当前的微处理器中,高速缓存通常可以分为两级,其中第一级高速缓存也称为片上高速缓存,第二级高速缓存称为关闭. 芯片缓存. 一级缓存通常分为两部分,一个用于存储指令,另一个用于存储数据. 二级缓存需要同时存储指令和数据.
在某些微处理器中,高速缓存可以分为三个级别. 缓存映射策略如何在内存块和缓存行之间建立相互映射关系是专门实现缓存读取内存操作的必要链接. 根据映射策略,存储块的数据可以并且只能被复制到映射的缓存,并且缓存行中的数据可以并且只能被映射到相应的存储块. 当前,缓存映射策略可以分为三种类型: 直接映射策略,K-way组关联映射策略和完全关联映射策略. 当代超级计算机的硬件体系结构(8)K-路集关联映射策略(K-路集关联映射策略)Cache被分解为V个缓存行,并且根据直接映射策略将内存块映射到特定组. 该组中的存储块可以映射到任何高速缓存行,也就是说,每个存储块都可以映射到任何高速缓存行. 具体算法是: 当代超级计算机的硬件架构(8). 缓存抖动,也就是说,连续访问的数据单元位于不同的内存块中,并且这些块映射到同一缓存,连续的数据访问将导致频繁的缓存行替换. K路组关联映射策略可以减少缓存冲突的可能性. 当代超级计算机的硬件体系结构(8)完全关联映射策略(full association mapping strategy)存储块可以映射到缓存中的任何缓存行,这种映射策略的实现比较复杂,通常只有理论上的价值,在在实践中很少见.
当代超级计算机的硬件体系结构(8)高速缓存行替换策略LRU(最近最少使用)算法: 替换最长时间未引用的高速缓存FIFO(第一输入优先输出)算法: 替换最先放置的高速缓存LFU (最不常用)算法: 最不常用的缓存随机算法: 随机选择要替换的缓存行. 当代超级计算机的硬件体系结构(8)缓存数据一致性策略直写策略: 修改缓存行中的数据后,立即将其写入内存块. 其缺点是增加了许多不必要的内存访问. 回写策略: 当且仅当需要替换高速缓存行或外部请求访问存储块时,才将高速缓存行的数据写入内存. 当代超级计算机的硬件体系结构(9)单指令多数据流(SIMD): 根据同一指令高性能计算机的结构,并行机的不同功能组件同时处理不同数据的方式也不同,例如: 传统矢量机,1980年代初始阵列机CM-2. 目前,这种并行机已退出历史舞台. 多指令多数据流(MIMD): 不同的处理器可以同时对不同的数据执行不同的指令,当前所有并行计算机都属于此类.
多指令单数据流(MISD): 到目前为止尚未出现. 当代超级计算机的硬件架构(9)该系统由商业节点组成,每个节点包含2-4个商业微处理器,并且这些节点共享内部存储. 采用商用集换机连接节点,并在节点之间分配存储. 该系统由节点组成,每个节点是一个共享存储或分布式共享存储的并行机子系统,包括数十个,数百个甚至数千个具有强大计算功能的微处理器. 采用商用集换机连接节点,并在节点之间分配存储. 并行机系统(MPP: Massively Parallel Processing)系统由节点组成,每个节点包含大约10个处理器,共享存储. 该处理器使用专用或商用CPU. 专用的高性能网络用于互连,并且存储在节点之间分布.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-225649-1.html
-

-
钟欣桐
这个学生心术不正
-
赵谦光
俺们那的人大部分谈生意都很实诚
-
 高性能计算机课_高性能计算机tc6000_曙光高性能计算机
高性能计算机课_高性能计算机tc6000_曙光高性能计算机 不属于计算机高级语言 转帖:《广西博白金圭塘王氏后裔王缉志》
不属于计算机高级语言 转帖:《广西博白金圭塘王氏后裔王缉志》 计算机黑屏一半,显示器一半正常,如何处理?估计要修理多少?
计算机黑屏一半,显示器一半正常,如何处理?估计要修理多少? 离散图形更好还是集成图形更好?离散图形和集成图形之间的区别
离散图形更好还是集成图形更好?离散图形和集成图形之间的区别
)这讲的是人话