HPC高性能计算架构设计.docx
电脑杂谈 发布时间:2020-05-28 21:03:56 来源:网络整理
HPC高性能计算体系结构的HPC基本设计在过去的15年中,HPC一直是增长最快的IT市场之一,其增长率有时超过游戏和平板电脑的年增长率. HPC高性能计算市场空间有多大? 2016年全年,我们报告HPC服务器市场的全球工厂收入从2015年的107亿美元增长到创纪录的112亿美元. 请参阅“ / s __ biz = MzAxNzU3NjcxOA ==&mid = 2650717317&idx = 1&sn = 6ccbe4c92f482e88ba7b2678a3eeb2e6&chksm = 83e97ae4b49ef3f2ad28e48fadbbf856a8edbcbc856b7856b3c7b3cbdc88d3cbbdcbf856a1e2272b HPC市场达到439亿”),预测,HPC服务器市场将在2021年增长到148亿美元,整个HPC生态系统市场将超过那年的300亿美元市场. 什么是高性能计算,涉及哪些技术和知识?高性能计算是指通常使用许多处理器(作为一台计算机的一部分)或群集中组织的多台计算机(作为单个计算资源运行)的计算系统和环境.
运行在高性能集群上的应用程序通常使用并行算法,根据某些规则将一个大的常见问题分为许多小的子问题,并在集群中的不同节点上执行计算. 结果,在处理之后,可以将其合并为原始问题的最终结果. 由于这些小问题的计算通常可以并行进行,因此可以缩短问题的处理时间. 在高性能群集的计算过程中,节点协同工作. 他们处理了大问题的一部分,并在此过程中根据需要交换数据. 每个节点的处理结果是最终结果的一部分. 高性能群集的处理能力与群集的大小成正比,并且是群集中节点的处理能力的总和,但是此类群集通常不具有高可用性. 高性能计算有许多分类方法. 在这里,我们从并行任务之间的关系的角度对高性能计算进行分类. 一,高吞吐量计算(High-throughput computing)有一类高性能计算,它可以分为几个可以并行的子任务,并且每个子任务都不相关. 因为这种类型的应用程序的一个共同特征是在海量数据上搜索某些模式,所以这种类型的计算称为高通量计算. 所谓的互联网计算属于这一类. 根据Flynn的分类,高吞吐量计算属于SIMDSingle指令/多数据(single指令流-multiple数据流)类别. 二,分布式计算(Distributed Computing)另一种计算类型与高吞吐量计算正好相反,尽管它们可以分为几个并行的子任务,但这些子任务紧密相连,需要大量的数据交换.
根据Flynn的分类,分布式高性能计算属于MIMD(多指令/多数据,多指令流-多数据流)的类别. HPC®系统的类型很多,从大型标准计算机群集到高度专用的硬件. 大多数基于群集的HPC系统使用高性能的网络互连,并且基本的网络拓扑和组织可以使用简单的总线拓扑. HPC系统由四个部分组成: 计算,存储,网络和群集软件. 用于高性能计算的HPC系统的技术特点是什么?目前HPC系统的主流处理器是X86处理器,操作系统是linux?系统(包括Intel,AMD,NEC,Power,PowerPC,Sparc等),构造方法采用刀片系统,而Internet使用IB和10GE. ?高性能计算HPC集群计算节点通常分为三种类型: MPI节点,胖节点,GPU加速节点. 两路节点称为瘦节点(MPI节点),两路或以上节点称为胖节点. 胖节点配置有大容量内存;群集中胖节点的数量取决于实际应用需求. ? GPU英文全名图形处理单元,图形处理器的中文翻译. 在浮点运算,并行计算以及其他计算方面,GPU可以提供CPU数十倍甚至数百倍的性能. 目前,只有三个NVIDIA GPU,AMD GPU和Intel Xeon PHI.

可供选择的GPU类型较少. NVIDIA? GPU卡分为图形卡和计算卡,图形卡有NVIDA K2000和K4000,计算卡K20X / K40M /K80®. 英特尔? GPU是Intel Xeon Phi吗?系列,属于计算卡,主要产品有Phi 5110P?,Phi 3210P,Phi 7120P,Phi 31S1P. AMD? GPU是图形和计算的结合,主要产品是W5000,W9100,S7000,S9000,S10000. ?如何衡量高性能计算的性能指标? CPU性能计算公式: 单节点性能=处理器主频*内核数*单节点CPU数*单周期指令号. 每个周期的指令数= 8(E5-2600 / E5-2600 v2 / E7-4800 v2)或16(E5-2600 v3);节点数=峰值浮点性能要求/单节点性能. 延迟(内存和磁盘访问延迟)是计算的另一性能指标. 在HPC系统中,一般的延迟要求如下: 一个MFlop等于每秒一百万(= 10 ^ 6)个浮点操作;一GFlop等于每秒十亿(= 10 ^ 9)个浮点运算; 1 TFlops等于每秒1万亿(= 10 ^ 12)浮点运算,(1 tera); 1个PFlop等于每秒1万亿(= 10 ^ 15)个浮点运算;一EFlops等于每秒一百(= 10 ^ 18)个浮点运算.
?测试工具-什么是Linpack HPC? Linpack HPC?是一种性能测试工具. LINPACK是Linear System Package的缩写,它主要始于1974年4月,在4月,美国阿贡国家实验室的应用数学研究所所长Jim Pool在一系列非正式会议中评估建立一套专门解决线性系统问题的数学软件的可能性. 行业中还有许多其他测试基准,其中一些基准基于诸如TPC-C之类的实际应用程序类型,而另一些则用于测试系统特定部分的性能,例如用于测试硬盘吞吐量的IOmeter以及流以测试内存带宽. 到目前为止,Linpack已被广泛用于解决各种数学和工程问题. 由于其高效的计算能力高性能计算机的结构,因此还引用了IMSL和MatLab等其他数学软件来处理矩阵问题,因此很明显,它在科学计算中具有举足轻重的地位. Linpack已成为国际上测试高性能计算机系统浮点性能的最受欢迎基准. 通过使用高性能计算机,使用高斯消元法求解N元密集线性代数方程的检验,并评估了高性能计算机的浮点性能. ?双列直插式内存(DIMM)有几种类型?双列直插式内存(DIMM)包括UDIMM内存,RDIMM内存和LRDIMM内存. 可以使用三种类型的DIMM内存.
在处理较大的工作负载时,无缓冲DIMM(UDIMM)快速,便宜但不稳定. 已注册的DIMM(RDIMM)内存稳定,可扩展且昂贵,并且对内存控制器的压力很小. 它们还用于许多传统服务器上. 甩负荷? DIMM(LRDIMM)内存是已注册内存(RDIMM)的替代,后者可提供较高的内存速度,减少服务器内存总线上的负载并消耗较少的电量. LRDIMM内存的成本比RDIMM内存高得多,但是在高性能计算体系结构中非常常见. 什么是用于非易失性双列直插式内存的NVDIMM? NVDIMM是从BBU(电池备份)演变而来的吗? DIMM. BBU使用备用电池将普通易失性存储器的内容保持几个小时. 但是,电池中含有重金属,废物处理和环境污染不符合绿色能源的要求. 以超级电容器为电源的NVDIMM应运而生. 而且NVDIMM使用非易失性闪存存储介质来保存数据,该数据可以存储更长的时间. 高性能计算网络的主要类型是什么? ? InfiniBand体系结构是一种“转换电缆”技术,支持多个并发链接. InfiniBand技术不用于一般网络连接,其主要设计目标是解决服务器端连接问题. 因此高性能计算机的结构,InfiniBand技术将应用于服务器和服务器(例如复制,分布式工作等),服务器和存储设备(例如SAN和直接存储附件)之间以及服务器和网络(例如LAN, WAN和Internet).
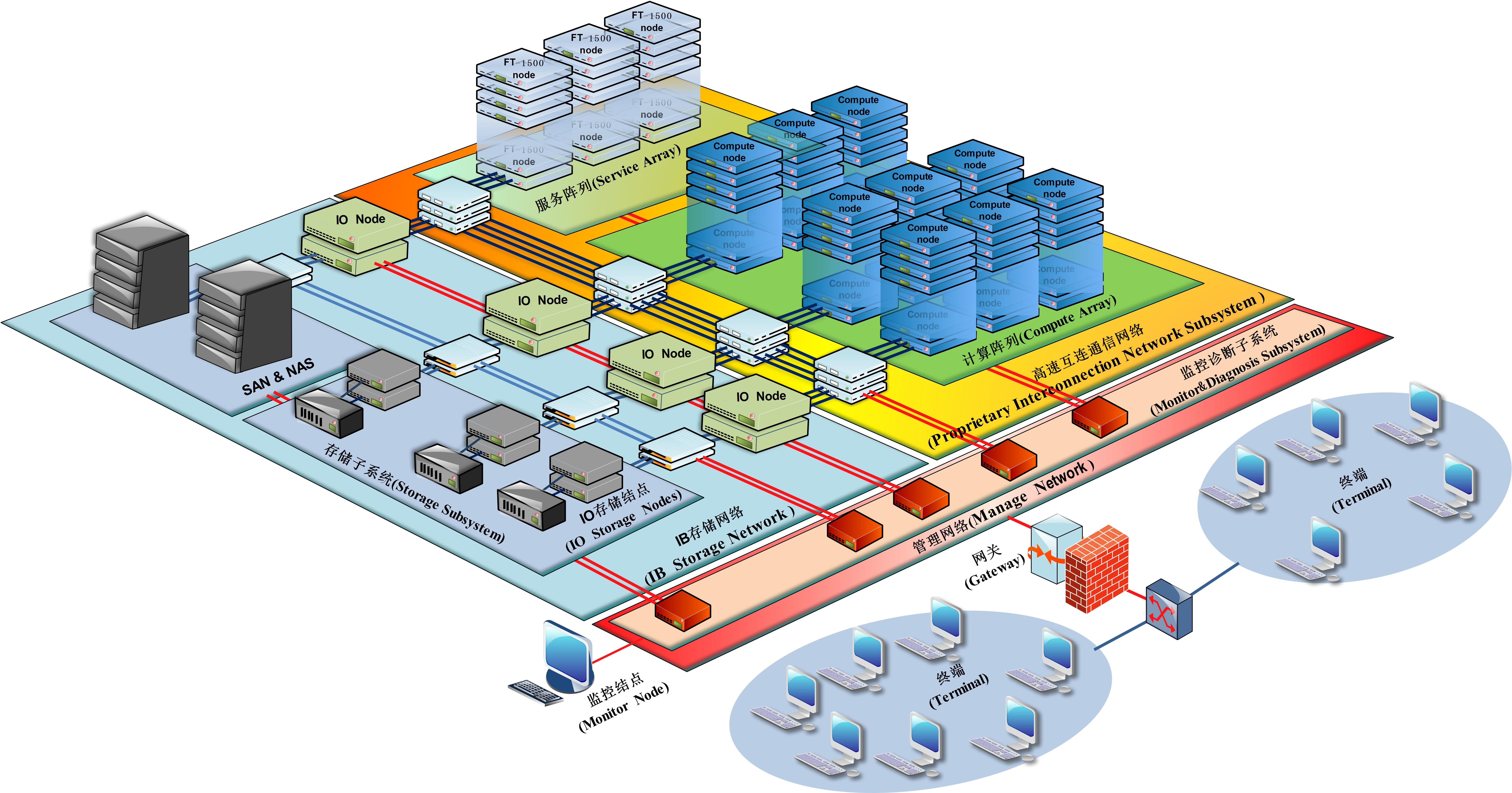
为什么将IB互连用于HPC HPC系统?主要原因是简单的IB协议栈,高处理效率,简单的管理,对RDMA的良好支持,低功耗和低延迟. ?目前只有Mexllaon,Intel,Qlogic提供IB产品,Mexllaon是主要参与者,处于主导地位,IB目前支持FDR和QDR,EDR. 主机通道适配器(HCA)是IB连接设备的端点,提供传输功能和Verb接口. 目标通道适配器(TCA)是HCA的子集,基本上用于存储. ? RDMA(远程直接内存访问)技术,远程直接数据访问的全称,是为了解决服务器端数据处理在网络传输中的延迟. RDMA通过网络将数据直接传输到计算机的存储区域,然后将数据从系统快速移至远程系统内存以实现零复制. 高性能计算并行文件系统的灵魂TOP500 HPC系统存储主要使用分布式文件系统,分布式文件系统(Distributed File System)可以有效地解决数据存储和管理问题: 在特定位置固定文件扩展到任意数量的位置/多个文件系统,并且许多节点构成了文件系统网络.
每个节点可以分布在不同的位置,并且节点之间的通信和数据传输是通过网络进行的. 当人们使用分布式文件系统时,他们不必关心数据存储在哪个节点上或从哪个节点存储,他们只需要像在使用本地文件系统一样在文件系统中管理和存储数据. 分布式文件系统的设计基于客户端/服务器模型. 典型的网络可能包括多个服务器,供多个用户访问. 当前的主流分布式文件系统包括: Lustre,Hadoop,MogileFS,FreeNAS,FastDFS,NFS,OpenAFS,MooseFS,pNFS和GoogleFS,其中Lustre,GPFS是HPC最主流的行业发展趋势. HPC计算体系结构的演变HPC系统实际上是一个并行计算系统. 许多初学者在遇到并行计算时都会对MPI,OpenMPI和OpenMP产生极大的怀疑. 主要原因是对这些概念本身的理解不清楚,而且这些缩写字母确实是如此相似. 下图让我们看一下MPI,OpenMPI和OpenMP之间的区别. MPI(消息传递接口)是消息传递接口,独立于语言的通信协议(标准)和库. MPI的实现包括MPICH,MPI-1,MPI-2,OpenMPI,IntelMPI,platformMPI等. OpenMPI(开放消息传递接口)是MPI的实现和一个库项目.
OpenMP(开放多处理)是应用程序接口(即应用程序接口),并行实现和方法,也可以被视为共享存储结构上的编程模型. 在当前的并行计算系统中,都需要OpenMP和OpenMPI(从上面的相应概念可以看出),OpenMP用于本地并行计算(共享内存存储体系结构),并支持所有平台上程序的共享内存类型目前. 并行计算等效于提供一个使并行编程更易于实现的模型,并且OpenMPI用于机器之间的通信(分布式内存体系结构). 从系统架构的角度来看,当前的商用服务器大致可以分为三类,即对称多处理器结构SMP? (SymmetricMulti-Processor),非均匀的存储访问结构? NUMA(非统一MemoryAccess)?和并行处理结构MPP(Massive ParallelProcessing). 它们的特点是共享存储多处理器的两种模型,即统一内存访问(UMA)模型和非统一内存访问(NUMA)模型.

COMA和ccNUMA都是NUMA结构的改进. SMP(SymmetricMulti-Processor)SMP对称多处理系统具有许多紧密耦合的多处理器. 在这样的系统中,所有CPU共享所有资源,例如总线,内存和I / O系统. 操作系统或管理只有一个副本,该系统的最大功能是共享所有资源. 多个CPU,对内存,设备和操作系统的平等访问之间没有区别. 操作系统管理一个队列,每个处理器依次处理该队列. 如果两个处理器同时请求访问资源(例如,相同的内存地址),则硬件和软件锁定机制将解决资源争用问题. SMP服务器的CPU利用率状态如下. 所谓的对称多处理器结构意味着服务器中的多个CPU对称地工作,没有主要或次要或从属关系. 每个CPU共享相同的物理内存,并且每个CPU访问该内存中任何地址所需的时间是相同的,所以? SMP?也称为统一内存访问结构吗? (UMA: 统一内存访问)?扩展SMP服务器的方法包括增加内存,使用更快的CPU,增加CPU,扩展I / O(插槽和总线的数量)以及添加更多外部设备? (通常是磁盘存储)? SMP服务器的主要功能是共享,并且系统中的所有资源(CPU,内存,I / O等)都是共享的.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-225641-1.html
-

-
赵蒙
那也是后期包装运输保存的问题
-
曹亦纯
放弃那些陈旧的
 在原始的Taotao U盘启动盘上安装原始Win8系统的详细教程
在原始的Taotao U盘启动盘上安装原始Win8系统的详细教程 centos php memcached
centos php memcached 崇明东滩 崇明低密度纯墅区 东滩花园少量房源
崇明东滩 崇明低密度纯墅区 东滩花园少量房源 为什么C语言结构的内存大小为24?
为什么C语言结构的内存大小为24?
重置網絡設置