二叉搜索树-算法简介(14)
电脑杂谈 发布时间:2020-05-26 23:13:13 来源:网络整理
1. 什么是二叉搜索树
顾名思义,二进制搜索树被组织为二进制树. 如下所示,可以使用链表数据结构表示这种树,其中每个节点都是一个对象. 除了关键和卫星数据外,每个节点还包含left(左子级),right(右子级)和p(父级)属性(如果不存在,则值为NIL).

二进制搜索树中的关键字始终以满足二进制搜索树性质的方式存储:
让x成为二分搜索树的节点. 如果y是x的左子树中的节点,则y.key≤x.key. 如果y是x右子树中的一个节点,则y.key≥x.key.
二进制搜索树的性质使我们能够使用简单的递归算法以一定顺序输出二进制搜索树中的所有关键字. 我们通常使用一阶遍历(输出子树根的关键字位置在左右子树关键字之间),中阶遍历和后阶遍历.
以下是用于预遍历的递归算法:

我们可以证明遍历具有n个节点的二叉搜索树需要θ(n)时间(省略证明).
2. 查询二叉搜索树
在本节中,我们将讨论诸如SEARCH,MINIMUM,MAXIMUN,SUCCESSOR和PERDECESSOR之类的二进制搜索树操作.
我们使用以下算法查询二进制搜索树. 此方法需要输入指向根节点的指针x和关键字k;输出是指向关键字为k的节点的指针(如果存在). 否则输出NIL.

很容易知道查询算法的时间是O(h),其中h是树的高度.
更好的是,我们可以使用以下迭代来替换递归,因为递归可能会导致堆栈内存溢出. 在大多数计算机上,迭代版本效率更高.
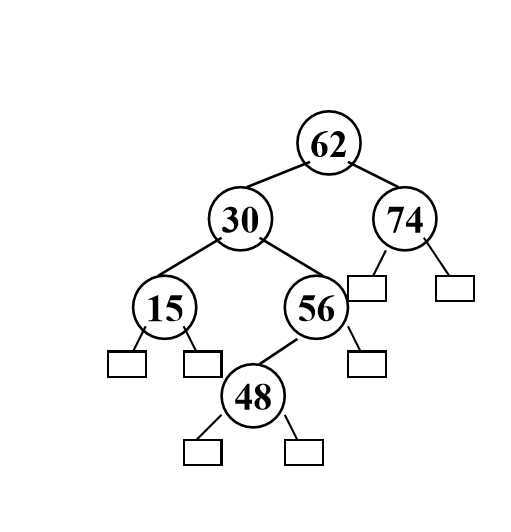

(3)最小和最大
由于二叉搜索树的性质,我们可以轻松地在树中找到最大和最小的关键字元素.


同样,以上两种方法都可以在O(h)时间内完成.
(4)继任者和前任者
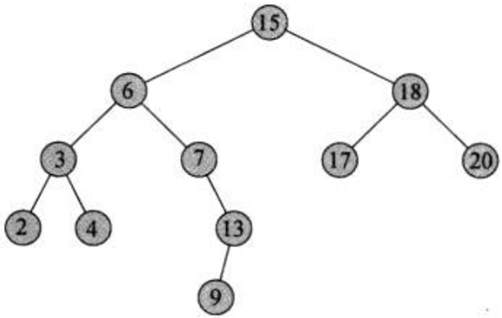
给定二叉搜索树的某个节点,有时我们需要以遍历的顺序以中间顺序查找该节点的前驱和后驱. 如下图所示,我们可以很容易地看到,具有键4的节点的前驱体是具有键3的节点,后驱动器是具有键6的节点;具有键7的节点的前驱体是具有键6的节点,后驱动器是具有键9的节点.
以下是用于查找特定节点的驱动程序的算法:

解释以上寻找后驱动程序的过程. 我们讨论两种情况:
①如果x的右子树不是NIL,则x的后继者是右子树中具有最小键的元素.
②如果x的右子树为NIL,则x的后继节点将在其祖先节点(包括父节点)中生成. 并且祖先节点必须是从下到上,这是第一次使其自身成为其父节点的右节点.
类似地,我们可以找到x的前任节点,此处未给出算法.

很容易看出它们都需要O(h)时间.
由此得出的结论是,在高度为h的二叉搜索树上,设置操作SEARCH,MINIMUM,MAXIMUN,SUCCESSOR和PERDECESSOR都可以在O(h)时间内完成.
3. 插入和删除
与删除操作相比二叉排序树查找 算法,插入操作相对简单. 插入算法如下. 该算法的作用是将新节点z插入二叉搜索树T.
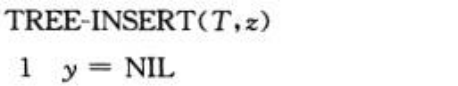

该算法非常简单,这里不再赘述.
还可以看到插入时间为O(h).
我们将根据已删除节点的子节点数讨论以下三种情况:
①删除的节点没有子节点. 只需修改其父节点并将其替换为NIL.
②删除的节点有一个孩子. 您只需要修改父节点即可用该子节点替换自己.
③删除的节点有两个孩子. 然后找到z的后继者y(必须在z的右子树中),然后让y占据z在树中的位置. z的原始右子树的一部分称为y的新右子树,z的左子树成为y的左子树.
前两种情况相对简单. 至于第三种情况,我们也可以细分为:
①如果z的后继y是z的右子(即y没有左子),则直接用y替换z并保留y的右子树,如下图所示:

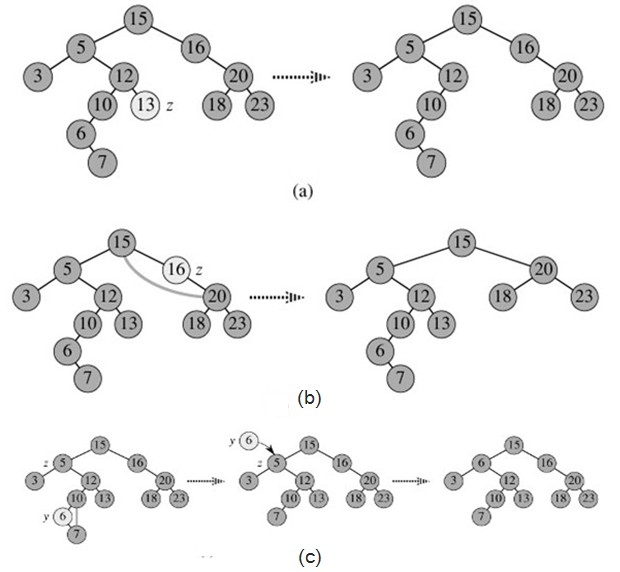
②如果z的后继者y不是z的正确子代,则用y的正确子代替换y,然后用y替换z. 如下图所示:

为了实现上述过程,我们首先实现移植过程. 此过程使子树v可以替换子树μ. 实现算法如下:

使用移植,我们根据上面的讨论执行删除操作:

请注意,以上删除过程并未提供z在上述讨论中没有子代的情况. 实际上,上述讨论中的情况①已包括在情况②中,即z没有孩子的情况等同于z的左孩子的关键字为NIL或右孩子的关键字为NIL.
分析算法后,我们发现除移植外,其他操作都需要固定的时间. 因此,删除操作将花费O(h)时间.
结合以上所有分析,我们可以看到二叉搜索树上的每个基本操作都可以在O(h)时间(其中h是树的高度)内完成.
4. 随机建立二叉搜索树
我们首先给出随机构建二叉搜索树的定义: 通过将n个关键字随机插入到空树中而获得的树. 这里的随机表示n! n个关键字的N种排列都是可能的.
我们要证明以下定理:
具有n个不同关键字的随机构建的二叉搜索树的期望高度为O(lgn).
首先定义三个随机变量Xn,Yn,Rn,其中Xn代表具有n个不同关键字的随机构造的二叉搜索树的高度; Yn = 2 ^ Xn表示二叉搜索树的指数高度(指数高度). Rn表示当选择n个不同的关键字之一作为树的根时,该关键字在n个关键字的集合中的排名(即Rn表示此关键字应在关键字排名之后占据. )这样,如果Rn = i,则根的左侧子树具有i-1个元素,而右侧子树具有n-i个元素.
Yn = 2·最大(Yi-1,Yn-i)
我们定义了另一个指标随机变量Zn二叉排序树查找 算法,i,Zn,i = I {Rn = i}. 由于Rn对于集合{1,2,...,n}中的任何元素同样可能,因此有:
p {Rn = i} = 1 / n,(i = 1,2,...,n)
E(Zn,i)= 1 / n
由于Zn,i仅等于1或0,因此Yn = 2·max(Yi-1,Yn-i)=
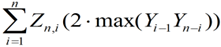
所以有:

在上式的最后一个和中,Y [0],Y [1],...,Y [n-1]将出现两次(E [Yi-1]和E [Yn-i]都出现),因此:

上面的公式是一个递归公式,我们可以猜测

,并且可以通过数学归纳法证明(此处省略).
有了詹森的不等式,我们可以获得更多的机会

所以

双方记录对数,最后:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-223359-1.html
-

-
盛立日
台湾人应该明白了
-
李晓刚
而且当初也是他求你
 split-bregman迭代_线性bregman迭代_matlab splitmerge
split-bregman迭代_线性bregman迭代_matlab splitmerge 联邦快递海关申报价值 宁波拼图代理报关公司10年操作经验
联邦快递海关申报价值 宁波拼图代理报关公司10年操作经验 如何在C ++中实现Trim函数,删除字符串前后的所有空格
如何在C ++中实现Trim函数,删除字符串前后的所有空格 慧学云智能提分王小学版v2.1.8
慧学云智能提分王小学版v2.1.8
不过美国所谓亚太盟国对此并不买帐