我们比较了几种图像识别技术...图像识别到底是什么?
电脑杂谈 发布时间:2020-05-24 10:24:20 来源:网络整理
编辑推荐
丰富的数据源对于图像处理始终是必不可少的. 这周我们将介绍图像识别技术. 我们还自己比较了几种技术〜
从前,图像识别技术似乎是一个奇怪的词,但是现在它越来越接近人们的生活. 近年来最经典的应用程序之一是Google和百度推出的图像识别功能. 我相信每个人都已经经历过; IT行业同事的热脸识别也是图像识别应用程序的经典示例;当然,现在在日常生活中,在网上购物中阅读图片必不可少. 只要您将想要购买的商品带入珍宝应用程序,它就会立即搜索该商品的类型和价格.
但是,这些强大的功能如何实现?将来,图像识别将与我们的生活进行更深入的联系,它与大数据有什么关系?今天让我为您慢慢探索.
数字图像(也称为数字图像或数字图像)是用有限的数字数字像素表示的二维图像. 要完成对数字图像的识别,您需要通过图像获取->图像预处理(例如二值化,反色和其他处理方法)获取信息,以获取特征数据->训练过程(分类器参与和分类决策)->识别步. 由于数字图像图像识别,文本和数字均以像素为基本元素,并且数字图像识别和数字识别的基本过程相似,因此我将简要介绍基于图像识别技术中相对基础的数字识别的识别过程.
首先介绍一些稍后将使用的基本概念:
1. 模式识别: 目前,模式识别具有广泛的应用. 它的观察对象包括人类感官直接或间接接收的外部信息. 使用模式识别的目的是使用计算机模仿人类的识别能力来区分观察到的物体. 模式识别方法大致可分为结构方法和决策理论方法两类,其中决策理论方法也称为统计方法. 字符模式识别的方法大致可分为统计模式识别,结构模式识别和人工神经网络. 以上图像识别步骤是模式识别的基本步骤.

模板识别是常用的模式识别方法之一. 顾名思义,它是在输入图像上连续剪切出临时图像并将它们与模板图像进行匹配. 如果相似度足够高,我们认为已经找到了适当的目标. 最常见的匹配方法包括方差匹配,相关匹配和相关系数匹配. 下面我们以模板匹配为例来说明模型识别的概念.
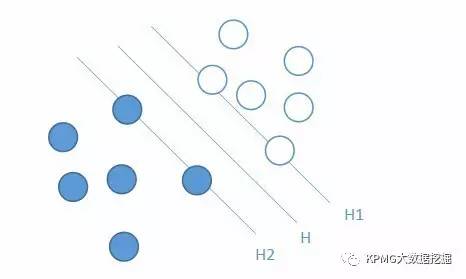
2. 支持向量机(SVM): 支持向量机是一种可训练的,基于结构风险最小化原理的通用机器学习方法,它只是一个分类器. SVM方法的原理只是线性化和维数增加的过程. 性可分离性的情况下,SVM是根据最佳分类超平面开发的. 如下图所示,空心点和实心点分别代表两种类型的样本,H是H维分类超平面,H1和H2是通过各种类型的点并且最接近分类超平面示例的超平面最优分类超平面理论要求分类超平面在正确区分两种类型的基础上最大化分类间隔.
3. OpenCV: 是一个基于BSD许可授权发型的跨平台计算机视觉库. 与其他函数库相比,它专用于现实世界中的实时应用程序. 同时,通过编写优化的C代码,客观地提高了其执行速度.
4. LIBSVM: 一个简单易用的SVM模式识别和回归软件包. 该软件包包含python,svmtoy和SVM-predict,svm-scale,svm-train等文件夹.
我首先使用OpenCV函数库读取原始图像库中的图像数据并将特征值存储到外部.txt文件中. 然后对数据进行预处理,形成要训练的数据;然后对通过预处理的数据进行参数优化和模型训练. 提取测试图像的数据特征后,将特征数据放入模型进行预测,得到识别率的预测值. 最后,分析识别率.
以下是我的实际战斗步骤:

1. 图像采集
我从0-9手绘了10个数字,每个数字有10个样本,总共有100个样本. 样本均为5 * 5模板. 通过代码实现,获得手写数字图像的特征信息.
2. 预处理
获取特征数据后,需要对特征数据进行一定的预处理,以保证后续工作的正常进行. 这次,我们选择了标准化处理,并使用svm-scale实现了它. 归一化的目的是确保提取的数据在一定范围内,避免出现过大或过小的情况,从而为模型的训练提供了保证.
此外,该过程还使用参数优化,目的是为模型训练提供良好的参数,从而获得更高精度的模型. 下图是数据优化操作的屏幕截图.
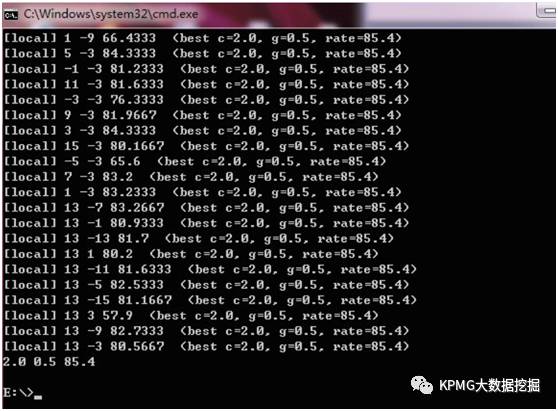
上图中的最后一行是最佳参数. 总的来说,我们将使用几个正确的模型来提取特征值作为参数优化的结果;然后在预测工作中,我们必须使用作为基准的最佳值进行预测. 已成功识别.

3. 模型训练
模型训练基于之前提取的样本特征数据,并将其放入LIBSVM分类器中进行分类. 分类基于每组特征值的标签. SVM机器学习方法是基于统计理论的,因此大量数据将获得更准确的模型文件.
实际结果:
我进行了一些简单的实验.
1. 分别使用基于模板匹配方法和基于SVM的识别方法的相同训练集和测试样本来观察数据维度对识别准确性的影响.
模板匹配方法
原因分析: 由于模板匹配方法使用网络特征提取方法,因此计算了每个区域中黑色像素的数量,并计算了每个区域在整个区域中所占的百分比; SVM是对每个像素的坐标进行统计分析,再加上高纬度,可以使坐标定位更加准确,因此SVM方法具有更大的优势.
结论: 在相同的测试样本和相同的纬度的前提下,分别通过SVM方法训练的模型在16维和25维上进行了预测,并且SVM方法获得的精度高于模板匹配的精度. 方法.
2. 使用支持向量机方法,使用相同的训练样本和测试样本来比较不同维度的准确性. 500个训练样本和100个测试样本.
结论: 对于相同的样本,使用SVM方法预测模型. 尺寸的高低对精度有积极影响,但是精度不会随尺寸的增加而无限增加.
3. 对于相同的测试样本,在相同的维度上图像识别,测试训练样本数对准确性的影响.
原因分析: 由于SVM方法的图像识别基于统计理论,因此大量训练样本有助于获得更准确的训练模型,这对模型训练预测的准确性有积极影响.
图像识别和大数据有着千丝万缕的联系. 一些前辈指出,数据挖掘=大数据+机器学习;一些专家认为模式识别=数据+机器学习. 大数据是一个时代概念,是社会发展的必然产物. 我们使用大数据技术来实现我们的最终目标-数据挖掘. 毫无疑问,“图像”也是一种数据,图像识别是构造非结构化数据的必要过程.
图像识别技术变得越来越普及,并且每年以火箭般的速度更新新技术和成就. 当然,它不限于图像处理和购物. 如今,图像识别技术已经从图像和知识的搜索发展到视频领域,这使我们不断感到惊讶. 例如,新兴的交互式视频技术视频++已经可以捕获视频中要识别的面孔和相同的衣服. 技术是第一生产力. 在21世纪,最热门的技术之一就是人工智能. 但是,图像识别技术是人工智能的核心. 它是未来智能AI的“眼睛”. 它的发展将不可避免地驱动人工智能. 快速发展. 未来就在这里,你准备好了吗?
参考文献: 曾志强,支持向量分类的训练和简化算法研究[D]浙江: 浙江大学2007.6,29.
关于我们
我们是毕马威(KPMG)数据挖掘团队. 在微信公众号(kpmgbigdata)中,我们将在每个星期六晚上8点准时推送原始文章. 这些文章是由项目的经验丰富的医生和高级顾问精心准备的,其内容也与实际业务的理论应用和经验以及其他干货结合在一起. 欢迎大家关注我们的微信公众号,并关注原创数据挖掘的优秀文章. 如果您想与我们联系,您也可以直接在公共帐户中向我们发送您想说的话.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-220389-1.html
-

-
户松遥
年利率1
-
郭会林
但你怎么会知道
 通用计算系统_通用路由平台vrp下载_图形处理器通用计算
通用计算系统_通用路由平台vrp下载_图形处理器通用计算 logback多线程死锁
logback多线程死锁 预装的win8 / 8.1笔记本将win7安装在GPT分区下,以形成双系统
预装的win8 / 8.1笔记本将win7安装在GPT分区下,以形成双系统 技嘉主板电脑怎么装win7系统|技嘉主板U盘装w7系统步骤
技嘉主板电脑怎么装win7系统|技嘉主板U盘装w7系统步骤
现在见俄打击有效抢风头