lucene_基于lucene的搜索引擎_lucene是搜索引擎么
电脑杂谈 发布时间:2016-11-21 15:02:45 来源:网络整理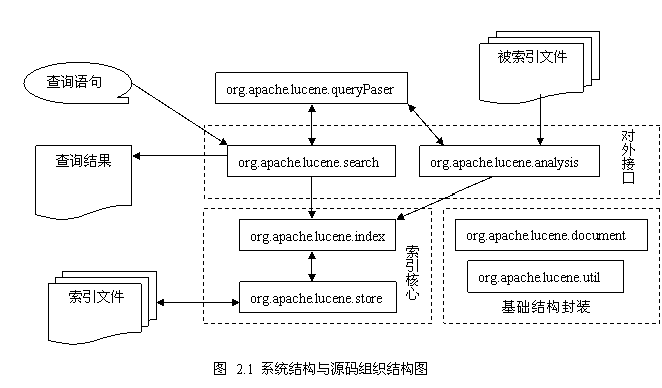
信息检索流程如下:
1、将即将检索的资源集合放到本地,并使用某种特定的结构存储,称为索引,这个索引的集合称为索引库。由于索引库的结构按照专门为快速查询设计的,所以查询的速度非常的快;
2、搜索操作时都是在本地的索引库中进行查找;
所以对于全文检索功能的开发,要做两方面:索引库管理(维护索引库中的数据)、在索引库中进行搜索。而Lucene就是操作索引库的工具;
索引库是什么样子?
索引库是一个目录,里面是一些二级制文件,就如同,所有的数据也是以文件的形式存放在文件系统中的。我们不能直接操作这些二级制文件,而是使用Lucene提供的API完成相应的操作,就像使用SQL语句一样。
对索引库的操作可以分为两种:管理与查询。
1、管理索引库使用的IndexWriter;
2、从索引库中查询使用IndexSearcher。
Lucene的数据结构为 Document与Field。
Document代表是一条数据,Field代表数据中的一个属性。一个Document中有多个Field,Field的值为String型,因为Lucene只处理文本;
我们只需要把我们的程序中的对象转换为Doucemnt,就可以交给Lucene管理了,搜索的结果中的数据列表也是Document的集合;
OK,我们来做一个实例,还原一下整个流程
1、创建一个用户类,用于实例化用户数据
public class User {
private Long id;
private String name;
private int age;
private String ;
private Date birthday;
public User(Long id, String name, int age, String , Date birthday) {
super();
this.id = id;
this.name = name;
this.age = age;
this. = ;
this.birthday = birthday;
}
//get/set方法,这里省略
}
2、生成即将检索的资源数据
public class DataUtil {
/**
* 检索资源数据的准备;
* 这里的数据可以来源、文件系统等
* @return
*/
public static List<User> getUsers(){
List<User> list =new ArrayList<User>();
User user =new User(1L,"张三1",20,"man",new Date());
list.add(user);
user =new User(2L,"张三2",20,"man",new Date());
list.add(user);
user =new User(3L,"张三3",20,"woman",new Date());
list.add(user);
user =new User(4L,"张三4",20,"man",new Date());
list.add(user);
user =new User(5L,"张三5",20,"man",new Date());
list.add(user);
user =new User(6L,"张三6",20,"woman",new Date());
list.add(user);
return list;
}
}
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-21386-1.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
每日福利
 xp序列号sp3,xp sp3安装序列号
xp序列号sp3,xp sp3安装序列号 丸九饵料你知道多少?史上最全丸九饵料性能介绍!
丸九饵料你知道多少?史上最全丸九饵料性能介绍! 现在以前的计算机病毒生产商在哪里,是什么使得网络病毒不再猖
现在以前的计算机病毒生产商在哪里,是什么使得网络病毒不再猖 磁盘重新分区重装系统 简单易上手 固态硬盘SSD安装WIN7系统的3种办法
磁盘重新分区重装系统 简单易上手 固态硬盘SSD安装WIN7系统的3种办法热点图片
老美武器强大了用脑少了