jeffery1010
电脑杂谈 发布时间:2020-05-14 08:05:55 来源:网络整理
一个,C#正则表达式符号模式
字符
说明
转义字符,将具有特殊功能的字符转为普通字符,反之亦然
匹配输入字符串的开始位置
匹配输入字符串的结束位置
匹配前面的零个或多个子表达式
匹配前面的一个或多个子表达式
匹配前面的零个或一个子表达式
n是与先前的第n个子表达式匹配的非负整数
{n,}
n是一个非负整数,至少与先前的第n个子表达式匹配
{n,m}
m和n是非负整数,其中n <= m,至少匹配n次,最多匹配m次
当字符紧跟在其他限定符(*,+,?,{n},{n,},{n,m})之后,匹配的模式将尽可能少地匹配搜索到的字符串
匹配“ \ n”以外的任何单个字符
(模式)
比赛模式并获得这场比赛
(?:模式)
匹配模式但没有得到匹配结果
(?=模式)
向前预览,在任何字符串匹配模式的开头匹配搜索字符串
(?!模式)

否定预览,在与模式不匹配的任何字符串的开头匹配搜索字符串
匹配x或y. 例如,‘z |食物”可以匹配“ z”或“食物”. ‘(Z | f)ood’匹配“ zood”或“ food”
[xyz]
字符集. 匹配包含的任何字符. 例如,“ [abc]”可以与“普通”中的“ a”匹配
[^ xyz]
负字符集. 匹配任何不包含的字符. 例如,“ [^ abc]”可以与“普通”中的“ p”匹配
[a-z]
匹配指定范围内的任何字符. 例如,“ [a-z]”可以匹配“ a”到“ z”范围内的任何小写字母字符
[^ a-z]
匹配不在指定范围内的任何字符. 例如,“ [^ a-z]”可以匹配“ a”〜“ z”中没有的任何字符
匹配单词边界,指的是单词和空格之间的位置
匹配非单词边界
匹配数字字符,等效于[0-9]
匹配一个非数字字符,等效于[^ 0-9]
匹配换页
匹配换行符
匹配回车符
匹配任何空白字符,包括空格,制表符,换页符等.
匹配所有非空白字符
匹配标签
匹配垂直标签. 等效于\ x0b和\ cK
匹配任何单词字符,包括下划线. 等同于“'[A-Za-z0-9 _]'
匹配所有非单词字符. 等同于“ [^ A-Za-z0-9 _]”
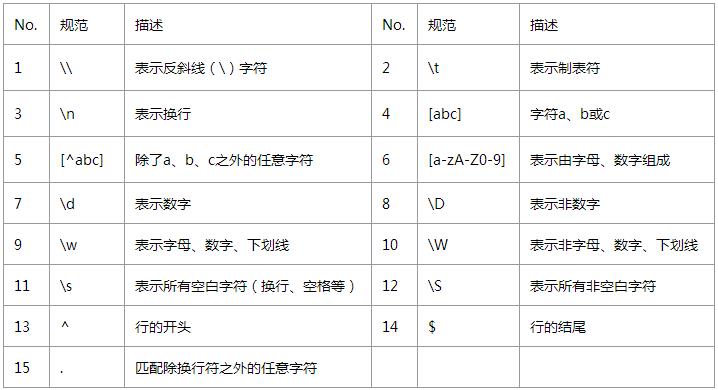
说明:
因为在正则表达式中,“ \”,“?”,“ *”,“ ^”,“ $”正则表达式的规则,“ +”,“(”,“)”,“ |”,“ {”,“如[“具有一些特殊含义. 如果您需要使用其原始含义,则应转义它. 例如,如果您要在字符串中至少包含一个“ \”,则正则表达式应这样写: \\ +.
第二,在C#中,要使用正则表达式类,请在源文件的开头添加以下语句:
用于复制代码的代码如下:
使用System.Text.RegularExpressions;
RegEx类的三种常见方法
1. 静态匹配方法
使用静态Match方法,可以在源代码中获取匹配模式的第一个连续子字符串.
静态Match方法有2个重载,
Regex.Match(字符串输入,字符串模式);
Regex.Match(字符串输入,字符串模式,RegexOptions选项);
第一种重载参数表示形式: 输入,模式
第二个重载参数表示: RegexOptions枚举的输入,模式,“按位或”组合.
RegexOptions枚举的有效值为
已编译是指编译此模式
CultureInvariant表示不考虑文化背景
ECMAScript表示符合ECMAScript,此值只能与IgnoreCase,Multiline和Complied结合使用
ExplicitCapture意味着仅保存显式命名的组
IgnoreCase表示输入不区分大小写
IgnorePatternWhitespace意味着删除模式中未转义的空白并启用由#标记的注释
多行表示多行模式,更改元字符^和$的含义,它们可以匹配行的开头和结尾
None表示没有设置,此枚举没有任何意义
RightToLeft表示从右到左扫描和匹配. 这时,静态Match方法从右向左返回第一个匹配项

单行表示单行模式,更改了元字符的含义. 它可以匹配换行符
注意: 多行可与不带ECMAScript的单行一起使用. 单行和多行不是互斥的,而是与ECMAScript互斥的.
2. 静态匹配方法
此方法的重载形式与静态Match方法相同,并返回一个MatchCollection,它表示输入中匹配模式的匹配集.
3. 静态IsMatch方法
此方法返回布尔值,重载形式与静态Matches相同正则表达式的规则,如果输入匹配模式,则返回true,否则返回false.
可以理解为: IsMatch方法,返回Matches方法返回的集合是否为空.
四,RegEx类的示例
1. 字符串替换
例如,我想将以下格式记录中的NAME值更改为WANG
字符串行=“ ADDR = 1234; NAME = ZHANG; PHONE = 6789”;
Regex reg =新的Regex(“ NAME =(. +);”);
字符串已修改= reg.Replace(行,“ NAME = WANG;”);
修改后的字符串为ADDR = 1234; NAME = WANG;电话= 6789
2. 字符串匹配
例如,我想从记录中提取NAME值
Regex reg =新的Regex(“ NAME =(. +);”);
Match match = reg.Match(line);
字符串值= match.Groups [1] .Value;
3,匹配实例3
文本中包含“ speed = 30.2mph”,需要提取速度值,但是速度单位可以是公制或英制,mph,km / h,m / s是可能的;此外,前后可能会有空格.
字符串=“车道= 1;速度= 30.3mph;加速度= 2.5mph / s”;
Regex reg =新的Regex(@“ speed \ s * = \ s *([\ d \. ] +)\ s *(mph | km / h | m / s)*”);

Match match = reg.Match(line);
然后match.Groups [1] .Value将包含数字值和match.Groups [2] .Value将包含单位.
4. 再举一个例子,要解码GPS的GPRMC字符串,只需
Regex reg =新的Regex(@“ ^ \ $ GPRMC,[\ d \. ] *,[A | V],(-?[0-9] * \. ?[0-9] +), ([NS] *),(-?[0-9] * \. ?[0-9] +),([EW] *)、. *“);
您可以获得经度和纬度值,该值过去需要数十行代码.
五,System.Text.RegularExpressions命名空间的描述
名称空间包括8个类,1个枚举和1个委托. 他们是:
捕获: 包含匹配结果;
CaptureCollection: 捕获序列;
Group: 组记录的结果,由Capture继承;
GroupCollection: 代表捕获组的集合
匹配: 表达式的匹配结果,由Group继承;
MatchCollection: 一系列匹配项;
MatchEvaluator: 执行替换操作时使用的委托;
Regex: 已编译表达式的实例.
RegexCompilationInfo: 提供编译器用来将正则表达式编译为独立程序集的信息
RegexOptions提供用于设置正则表达式的枚举值
Regex类还包含一些静态方法:
转义: 转义字符串中的正则表达式中的转义字符;
IsMatch: 如果表达式与字符串匹配,则此方法返回一个布尔值;
匹配: 返回Match的实例;
匹配: 返回一系列匹配的方法;
替换: 用替换字符串替换匹配的表达式;
Split: 返回由表达式确定的一系列字符串;
Unescape: 不要对字符串中的转义字符进行转义.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-209585-1.html
-

-
康丁
记住
 民政部敦促社会宽容婴儿安全岛
民政部敦促社会宽容婴儿安全岛 最新新闻评论: 2014年有多少人死于埃博拉病毒. 埃博拉病毒如何消失?有疫苗
最新新闻评论: 2014年有多少人死于埃博拉病毒. 埃博拉病毒如何消失?有疫苗 结构体南京工业大学工程地质学2006大纲 - 2006 年硕
结构体南京工业大学工程地质学2006大纲 - 2006 年硕 华为Enjoy 9 Plus和Enjoy Max出现在官方网站上: 首款7英寸屏幕手机即将面世!
华为Enjoy 9 Plus和Enjoy Max出现在官方网站上: 首款7英寸屏幕手机即将面世!
希望下一代能做好