对分布式存储系统的一些理解和实践
电脑杂谈 发布时间:2020-05-13 05:30:46 来源:网络整理
对分布式存储系统的一些认识和实践张建伟1.分布式存储系统的介绍1.简介Internet数据越来越大,并发请求越来越高. 传统的关系不能在很多情况下使用很好地满足需求. 分布式存储系统应运而生. 它具有良好的可伸缩性,削弱了关系数据模型,甚至削弱了实现高并发性和高性能的一致性要求. 按功能分类,主要有以下几种: 分布式文件系统hdfs ceph glusterfs tfs?分布式对象存储S3(Dynamo)Ceph BCS(Mola)?分布式表存储hbase cassandra oceanbase?块存储ceph ebs(amazon)分发存储系统包括两部分: 分布式系统和独立存储. 尽管不同的系统在功能支持,实现机制,实现语言等方面存在差异,但设计中的关键问题基本相同. 独立存储有三种主要的实现方法: 哈希引擎,B +树引擎和LSM树(日志结构合并树). 本文的第二章主要结合了hbase,cassandra和ceph,并讨论了分布式系统设计中需要注意的关键问题. 2.适用场景每个分布式存储系统的功能定位不同,但适用场景和不适用场景在一定程度上相同,如下所示.
1)适用于大量数据(大于100T,甚至几十个PB)键/值或半结构化数据高吞吐量,高性能和高扩展性2)不适用于Sql查询的复杂查询,例如作为联合表的复杂查询分布式存储系统的设计要点1.数据分布和分布式存储可以由成千上万的机器组成,以实现海量数据存储和高并发性. 它必须解决的第一件事是数据分配问题,即哪些数据存储在哪些计算机(节点)上. 常用的是哈希算法和元表映射. 通常,完全分布式设计(无主节点)将使用哈希算法;而集中式设计(带有主节点)使用元表映射. 两者都有各自的优缺点,我们稍后将在讨论特定问题时进行比较. 1)一致性哈希将存储节点和操作键(该键唯一地标识所存储的对象,有时称为对象名称)哈希到0到2的第32个幂间隔. 映射到下一个环中的某个位置. 沿操作键位置顺时针找到的第一个节点是该键的主要存储节点. 如下图所示: 图1一致性哈希Cassandra借鉴了dynamo的实现,并使用了一致性哈希的方法.
可以手动分配或自动生成节点的哈希值(也称为令牌). Key的哈希值是md5(密钥). 每个表可以在创建表时指定副本数. 当副本数为3时,找到主存储节点后,顺时针方向上的下两个存储节点为副本存储节点. 哈希算法的优点是不需要主节点. 一个缺点是它不支持键的顺序扫描. 2)Crush算法也是类似哈希的算法. 随着ceph的诞生,它也是ceph的一大亮点. Crush算法更加复杂,在此进行了简化. Ceph中的每个对象最终都将映射到一组OSD. 这组OSD将保存该对象. 映射过程如下: 对象→PG→OSD设置? OSD首先被理解为机器节点. PG是放置组,可以理解为存储. 同一组OSD对象上的对象集合首先映射到PG(放置组),然后由PG映射到OSD集. 每个表空间都有固定数量的pg,该数量在创建表时指定. 每个对象都通过计算哈希值和对pg的数量取模来获取其对应的PG.

PG映射到一组OSD(OSD的数量由表的副本数决定,并且在创建表时也要指定). 第一个OSD是Primary,其余的是Replicas. PG→OSD集的映射取决于几个因素: CRUSH散列算法: 伪随机算法. OSD MAP: 包含所有当前OSD状态,OSD机架信息等. CRUSH规则: 数据映射策略. 这些策略可以灵活地设置存储对象的区域. 例如,您可以指定将表1中的所有对象放在机架1上,将所有对象的第一个副本放在机架1上的服务器A上,将第二个副本分发到机架1上的服务器B上. 分布在机架2、3和4上,所有对象的第一个副本分布在机架2中的服务器上,第二个副本分布在机架3中的服务器上,第三个副本分布在机架4的服务器上. 具体的实现不再展开. 图2 Ceph Crush算法的伪代码如下: locator = object_name obj_hash = hash(locator)pg = obj_hash%num_pg osds_for_pg = rush(pg)#返回osds的列表primary = osds_for_pg [0]副本= osds_for_pg [ 1: ] Crush比一致的哈希更灵活.
3)按范围查找表. 主节点记录并管理每个表范围的粒度,以及存储每个范围数据的节点. 该范围是根据密钥的字节序确定的. 当客户端执行密钥访问操作时,它首先到达主机,并根据其范围查询存储了哪些节点;然后直接与存储节点进行交互以实现访问. Hbase以这种方式实现,并支持顺序扫描密钥. 如下图所示,区域是数据范围(存储在主服务器上),区域服务器是实际的存储节点. 图3 hbase区域映射2.数据可靠性数据可靠性(即数据不丢失)是存储系统的首要责任. 图4数据中心通常,使用普通服务器进行分发. 假定服务器和硬盘都不可靠. 对于任何分布式存储系统,必须确保在硬件损坏时如何确保数据不会丢失. 有以下方法. 1)多个副本是N +1个数据副本(通常为3个副本),每个副本存储在不同的节点上. 当数据被N个副本损坏时,仍可以修复数据. 缺点是它需要N倍的冗余存储空间. 2)hbase,cassandra和ceph都得到很好的支持.
擦除码是将一块数据分成n个相等的部分. 通过对n个数据进行编码,获得了m个大小相等的奇偶校验数据块. n + m数据副本存储在不同的节点上. 如果得到n + m的n个副本,则可以计算原始数据. 通常,n为10,m为3. 优点是仅需要m / n倍的冗余空间,缺点是读写效率低,消耗cpu. 图5删除码Hbase: hdfs层提供对hbase的支持. Cassandra: 社区版本不支持它. 社区尚未添加添加此功能的路线图. 社区之前已经讨论过此功能,但是已经消失了. 应该主要考虑的是,擦除编码方法对现有系统的存储结构和一致性语义影响较大,而性能较低. 瑟夫: 是的. 但是缺少一些功能,例如不支持部分读取,这适用于读取远远超过写入且应用很少的情况. 跨组自动备份? 3)通常,为了获得更高的可靠性,数据将通过准实时备份机制备份到另一个IDC存储群集. 4)Hbase: 支持社区版本. Cassandra和ceph: 两者都不支持,短期内没有路线图,从长远来看,需要添加它. 访问修复客户端将数据写入存储集群,通常根据一定的规则找到访问节点,然后辅助访问节点充当代理,将数据写入实际的存储节点.

假设需要写入三个副本,如果访问节点发现与该副本相对应的一些存储节点此时不可用,或者写入超时,则写入失败的节点和执行该操作的数据未成功写入将被存储. 此后,当不可用节点在固定时间变为可用或在收到通知后,它将尝试写入之前未成功写入的数据. ? Hbase: hdfs层将确保写入足够的副本,因为hdfs的namenode记录每个块的元数据(该块存储在哪个datanode中),一个datanode写入失败,而另一个datanode写入,直到写入成功. 可以看出,以这种方式记录元数据非常灵活. Cassandra: 有一个提示切换机制,原理如上所述. Ceph: 有一个pglog机制,原理如上所述. 全局扫描修复??? 5)用于修复由于磁盘损坏,文件意的数据,并在多个副本之间扫描数据. 如果发现缺少副本,请对其进行修复. Hbase,cassandra和ceph都具有类似的机制. 原理相似,机制不同. 在这里我不会一一讨论. Hbase: hdfs层的数据节点发现磁盘损坏后,它将收集所有剩余的块信息,并通知名称节点进行比较和修复Cassandra: 基于Merkle树的反熵机制Ceph: scrub和深层磨砂机制? 3. 可用性分布式存储系统具有比传统关系更好的可用性.
在极端情况下,例如单个计算机的硬件或软件故障,甚至整个计算机房都已关闭电源或与网络断开连接,读写不会受到影响. 对于单个机器的硬件或软件故障,可以通过保存多个副本或擦除代码来解决常规数据. 对于整个计算机房的电源故障,它只能是跨副本IDC的多副本存储. 通常,分布式存储系统支持此方法,但实际应用很少. 影响可用性的另一个因素是整个系统是否有单点故障. 完全分布式设计中没有任何一点. 具有元信息并需要元服务器角色的集中式设计通常会使元服务器成为集群以避免单点问题. 让我们用例子来谈论它. 1)?分布式或集中式Hbase: 元服务器是群集模式. 通过zk选择算法选择一个主节点以提供服务. 主节点挂断后,将选择一个新节点. 因此,hbase的元服务器不是单点. 但是,其区域服务器是一个单点,即区域服务器挂起了. 在主机不重新分配其负责的区域之前,该区域负责的范围无法提供读写. 进行这种单一猜测的原因是,hbase最初是为脱机存储而设计的,例如网络库,而不是服务.
此的密钥,对应于hdfs在一组文件上),根本不需要拖动数据.
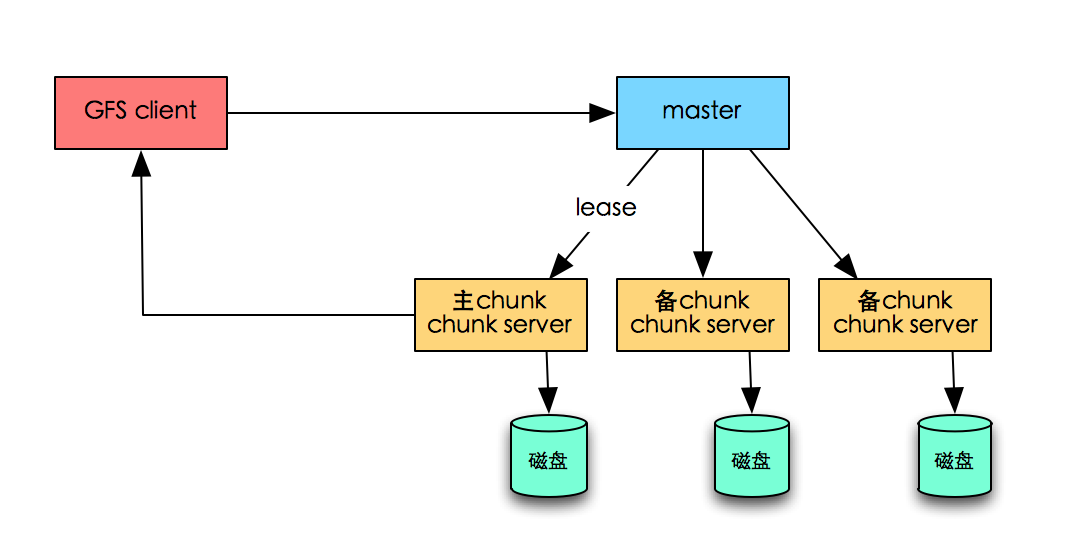
扩展hdfs本身的容量也更容易,因为有一个名称节点(相当于主服务器,它记录了写入hdfs的每个块的存储节点),因此可以将新写入的文件写入到新的扩展服务器,因此无需拖动数据;如果要考虑写入压力平衡(也就是说,不要将写入压力集中在新添加的计算机上,而仍然要写入所有计算机),则仍然需要进行数据迁移. ? Cassandra和ceph: 因为键定位是通过哈希算法进行的,所以拖动数据是不可避免的. 拖动的数据量是新添加的节点负责的数据量. 一致的哈希算法和粉碎算法不同,导致拖动数据的源节点不同,但是通常它们是相似的. 5.数据一致性的一致性分为强一致性和最终一致性,它们解释如下: 强一致性: 写入数据key1后,立即读取key1,并可以读取最新数据. 最终一致性: 写入key1后,立即读取key1. 可以读取旧数据,但是一段时间后,可以读取新数据. 最终一致性比强一致性具有更高的性能. 一致性与读写过程中主副本的状态有关. 如下所述,不同的系统在实现上会有不同的权衡. 1)?单主机,多主机,主从Hbase: 区域服务器是单点的,可以理解单主机模式的问题,自然强一致性.
Cassandra: 最终的一致性,也可以通过设置客户端的一致性级别来实现强一致性. Cassandra的多个副本节点具有相同的状态,这可以理解为多主模式,并提供并行的读取和写入. 此方法具有较高的读写性能. 除了牺牲强一致性之外,它还导致写冲突. Cassandra通过列级别的时间标记解决了此问题,但并不彻底. 如果时间戳相同,则无法执行此操作. Ceph: 多个副本之间存在主从关系. 一个主节点有许多从节点,客户端编写主节点,而主节点负责编写从节点. 客户端只能读取主节点. 这样,实现了强一致性. Ceph还支持本地化(附近,不一定是主节点)读取模式的配置,这也牺牲了强大的一致性. Ceph的块存储和分布式文件系统功能要求它支持强一致性. 6.性能如前所述,不同的一致性会影响性能. 此外,还有两点对性能有较大影响: 1)全分布式或集中式集中式体系结构需要元服务器. 读取操作首先检查元服务器,然后在数据节点中查询真实数据;除了更新数据节点之外,写操作还可以更新元服务器. 完全分布式的读写可以减少与元服务器交互的过程. 因此延迟较低. 而在集中化的情况下,当数据量巨大或压力很大时,元服务器可能成为性能瓶颈. 当前,存在诸如元服务器分层和静态子树之类的解决方案.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-208278-1.html
-

-
李倩
一吨大豆出油率17---22%左右
-
 C语言表单参与参数的回顾
C语言表单参与参数的回顾 解决方案:如何使用U盘安装原始Win8系统
解决方案:如何使用U盘安装原始Win8系统 《仪表技术与传感器》沈阳仪器论文征稿
《仪表技术与传感器》沈阳仪器论文征稿 ID卡自助取款机在这里,您可以在24后半分钟内获得它
ID卡自助取款机在这里,您可以在24后半分钟内获得它
家里就0利息了