[案例共享] Vip.com的实时OLAP分析技术升级之路
电脑杂谈 发布时间:2020-05-10 18:06:12 来源:网络整理
具有大量数据的实时OLAP方案的困境
Vip.com大数据实时OLAP升级过程
Vipshop将在开源计算引擎上进行改进
OLAP计划升级方向
1
具有大量数据的实时OLAP方案的困境

大数据
首先看看我们在前几年遇到的问题. 首先是大数据,听起来很无聊olap分析引擎,但是大数据意味着什么?主要问题是数据很大. Vip.com在过去几年中将快速发展. 用户流量数据已从最初的几百万和几千万增长到目前的数亿,增长了100倍以上.
对我们来说,所谓的大数据就是数据量的迅速扩大. 主要问题是传统的RDBMS无法满足存储需求,进而无法满足计算需求. 我们的挑战是克服这个问题.

查询慢
第二个问题是慢查询,它有两个方面: 一是OLAP查询的速度变慢. 其次是降低了ETL数据处理的效率.
分析这两个问题: 首先,用户在使用OLAP分析系统时会有这种期望. 当我单击查询按钮时,希望所有数据都可以在几秒钟内输出,而不是帮我喝茶,而是回来看看. 数据仅运行了10%,这是不可接受的. 由于数据量很大,我们也可以选择预先计算. 用户查询时,直接从计算结果中找到对应的值并返回,则查询以秒为单位. 大量数据对于预计算也存在相同的问题,即,ETL的性能也会降低. 准备此数据可能只需要40分钟或一个小时. 现在,数据量增加了一倍,需要三个小时. 这时,数据分析师开始工作时,他会抱怨数据还没有准备好. 他必须等到中午进行分析,他才会听到同事不断的抱怨.

长时间迭代
由增加的数据量引起的第三个问题是更长的开发周期. 有两个角度: 首先,新业务上线. 用户会说我是否可以在这个新角度上线之前查看历史数据. 这取决于年份,是时候刷新数据了. 如您所知,数据刷牙每次刷头很大时都需要很长时间. 旧业务也是如此. 没有历史趋势,添加新指标是行不通的. 您还需要刷新数据,开发人员将不断刷新数据. 由于数据量很大,因此需要很长时间来刷新数据,并且需要花费大量时间来验证数据. 慢慢地,开发周期变慢了,业务非常烦躁. 我不认为这只是添加一个字段. 为什么这么慢. 这样,数据迭代时间长且周期变慢,这使业务部门对大数据业务提出了许多问题. 我们需要改进以解决这些问题.
业务部门的想法是,无论您从事何种业务,无论使用何种方法,他们都只关心以下三点: 首先,应迅速满足上述需求;其次,应迅速准备数据;第三,数据准备好后,当我进行分析时可以快速返回数据. 业务需要快速发展,但是现在的能力却很慢,因此我们需要解决业务部门的需求与现状之间的矛盾.
2
Vip.com大数据实时OLAP升级过程

阶段0
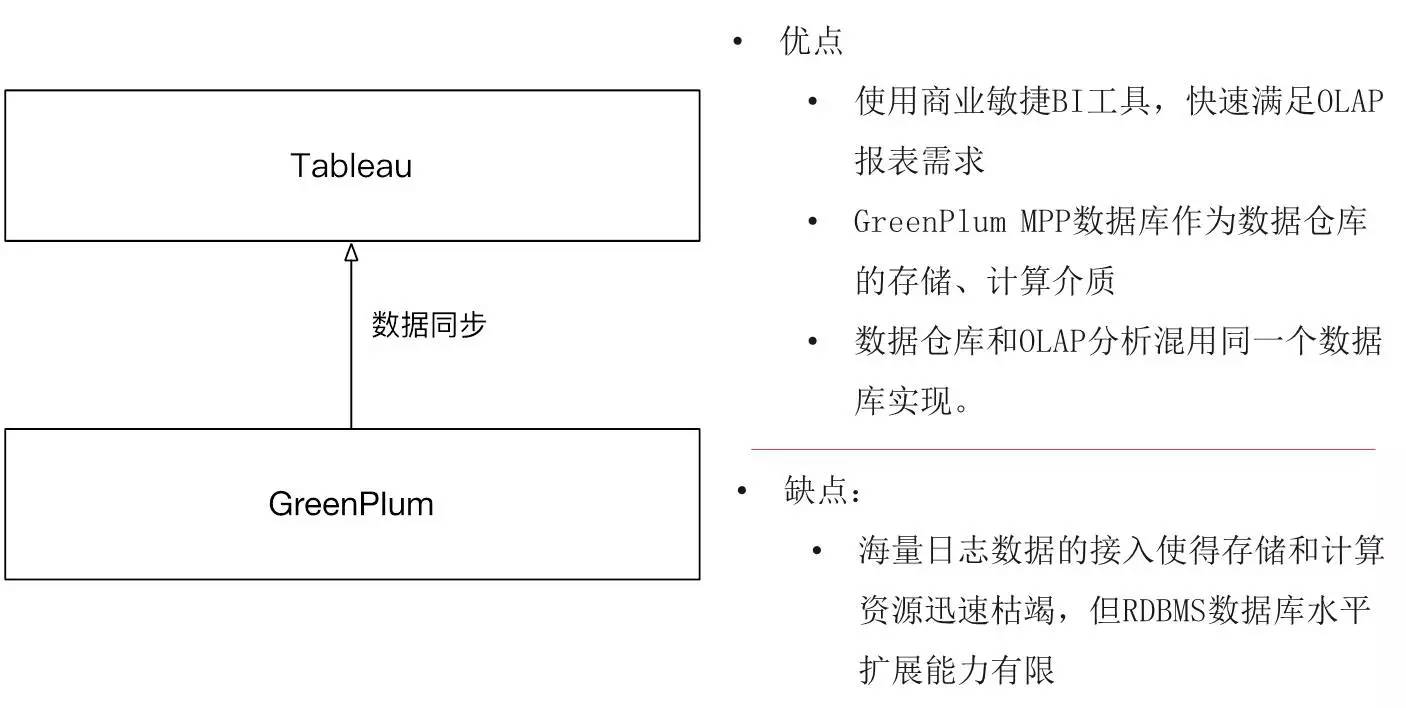

这是我们的初始状态,架构相对简单. 底层的计算,存储和OLAP分析由MDB数据仓库解决. 上层使用Tableau的BI工具. 开发速度相对较快,并且数据可视化效果同时得到了业务部门的高度认可. GreenPlum是MPP解决方案. 它的高并发查询非常适合我们的OLAP查询,并且其性能非常好. 因此,在此阶段,我们将GreenPlum用作数据仓库和OLAP混合使用的实现.
像这样的体系结构实际上是通用体系结构,例如Tableau可以很容易地替换,而GreenPlum也可以用Oracle替换. 等等. 这样一种常用的工具和体系结构实际上可以满足某些需求,但是也有一个问题是像GreenPlum这样的RDBMS. 面对海量数据写入,存储和计算资源迅速耗尽. GreenPlum的水平扩展受到限制,因此也遇到了大数据的问题.

第一阶段

很快,我们进入了第一阶段. 在这个阶段,我们介绍了Hadoop / Hive. 预先计算所有计算结果后,它们将同步到GreenPlum. 如下所示,使用GreenPlum进行分析. OLAP讨论有关聚合的临时问题,并继续由GreenPlum进行. 数据仓库讨论细节,而数据讨论批次. 然后将其移交给为分批创建的Hive. 技术栈不一样. 这种技术解决方案解决了数据量大的问题,并且ETL批处理不会说它们无法运行或无法存储数据.
但是问题是已经添加了新的同步机制,并且需要在两个不同的DB之间同步数据. 同步数据最明显的问题是,除了数据冗余之外,如果数据不同步怎么办?例如,ETL开发是在Hadoop上更新的,但未同步到GreenPlum,用户会发现数据仍然错误. 其次,对于用户而言,当Tabluea进行OLAP分析时,他是一种更适合于报告的工具. 随着业务的扩展和数据驱动力的不断深入,无论是分析师还是业务,运营,市场,业务,越来越多的人希望结合不同的指标和维度来观察自己的数据并找到自己的分析点. 传统的Tabluea报告无法再满足要求.
我们需要一个新的BI解决方案
对于我们来说,数据不同步. 可以解决的. 毕竟,它是偶然发生的. 只是处理它. 但是,BI工具存在很大的问题,无法满足企业不断发展的需求. 因此,我们需要一个新的BI解决方案:
首先,它必须足够灵活,以使用户在不发布后不能执行任何操作,我们只能观看. 我们希望它的尺寸和指标能够快速集成.
第二,阈值较低. 我们不希望像BI工程师这样的企业学习如何完成开发,因此入门非常容易. 其次,为了能够用语言而不是SQL来描述他们的需求,具有这种商业思想的人不可能学习SQL,因此他们必须能够用语言来描述他们想要的东西.
第三个原因是开发周期短,企业希望看到什么,所有数据都需要提及需求,需求分析,计划执行以及提及计划执行的更改. 此时,尽管业务发展不是每天都在变化,但是许多业务的反复试验时间非常快,开发数据时的日常工作也很冷淡. 因此,我希望有一个新的BI解决方案来解决这三个问题.
我们研究了市场上不适合的商业工具,这种灵活的解决方案要求我们拥有更多的控制权,因此我们开始了自我研究的道路.

第二阶段
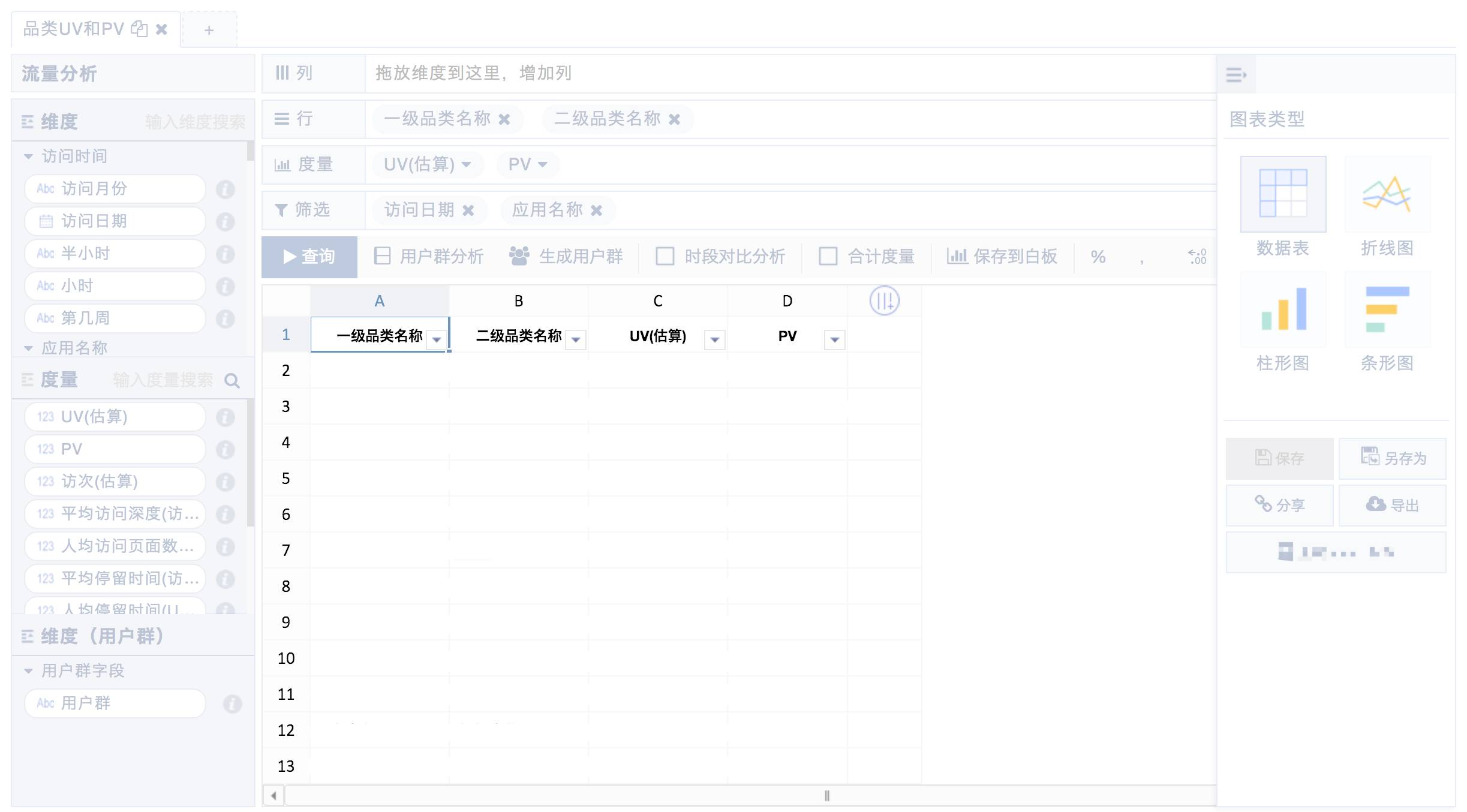
我们进入了OLAP分析的第二阶段. 这时,前端开发了一种称为自助分析平台的产品. 在此平台上,用户可以通过拖动以形成他们想要看到的内容,将左侧尺寸指示器拖放到顶部. 结果. 查询结果后,可以将其显示在表格或图形中,包括折线图,柱形图和条形图. 所有分析结果都可以保存,共享和下载.
使用这样的工具可以帮助分析师或业务人员更好地结合我们刚才所说的一切,而灵活性和低门槛的问题实际上得到了解决. 这样的拖放操作非常容易学习,只要您学习如何将业务逻辑转换为数据的逻辑描述,了解如何转换为哪种形式,行中显示的内容,列中显示的内容即可. ,什么是度量. 尽管学习曲线很少,但是该门槛比学习完整的BI工具的门槛低得多.
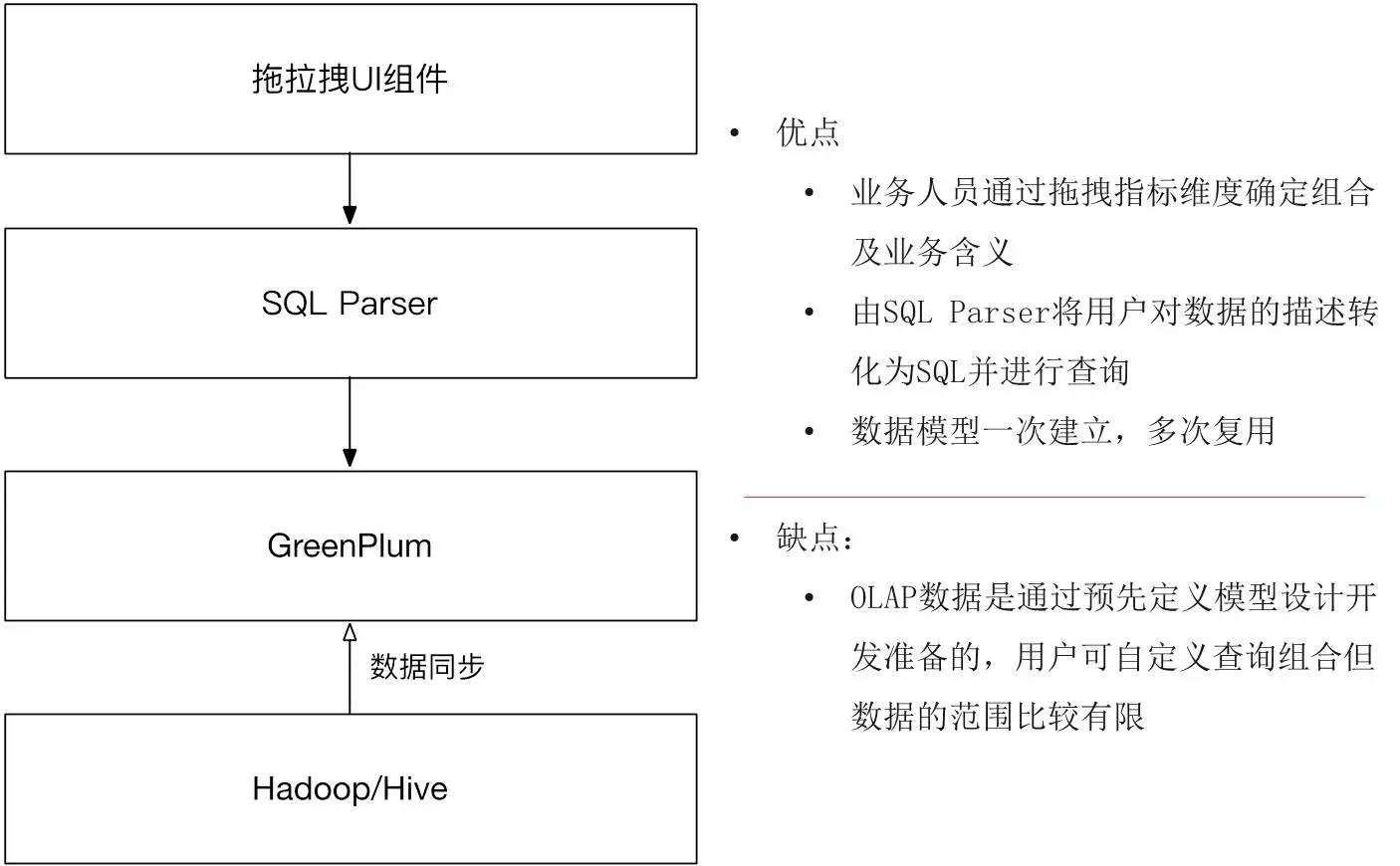
前端是这样的产品,后端也必须随之变化. 首先,前端是一个拖放式UI组件. 此组件意味着选择SQL和直接形成报告的传统方式不再可行. 由于所有维度和指标都是用户组合的,因此我们需要一个SQL Parser帮助用户将其数据描述转换为SQL,并执行性能调整以确保获得相对较高性能的反馈数据.
因此,我们开发了一个SQL Parser来承担组件生成的数据结构,并使用SQL Parser直接转到OLAP数据. 仍然通过预计算,我们需要将所需的索引维度同步到SQL Parser. 一旦建立了这样的模型,就可以多次重用.
但是我们知道这种计算方案有几个明显的缺点: 首先,必须计算所有数据,并且不能合并计算范围之外的数据;第二,存在数据同步问题,第三是什么?实际上,在进行预先计算时,您经常会发现我们认为这些组合是有效的,用户可能不会检查,但是如果不检查此计算,则是浪费. 有没有更好的方法来解决这种情况?
我们需要一个新的OLAP计算引擎

从这个角度来看,GreenPlum不能再满足我们了. 即使预先计算,也无法满足. 需要一个新的OLAP计算引擎. 这种新引擎需要满足三个条件:
没有预先计算的模型. 因为预计算的缺点是传统意义上没有数据摘要层,所以直接从DW层的详细数据进行计算. 而且我们所有的业务场景都只要DW层具有此数据,因此无需开发它,只需直接使用它即可. 前面我们讨论了数据摘要,需要缓慢地更改数据以刷新数据,这种头痛非常痛苦,我们必须解决它.
足够快. 数据平均返回10秒钟,看起来很慢,而不是几秒钟. 为什么当时设定了这样的目标?因为我刚刚提到过,需要安排以前的开发方法业务,等等. 这个周期很长. 如果您现在可以通过随意组合的方式满足其90%以上的需求,那么实际上,它在实际完成时就没有性能要求. 好苛刻在这里等待数据时,我们也不想弄乱我们的分析思路或时间表. 10秒可能更合适. 然后,由于我们的数据仓库DW层是按尺寸建模的,因此该OLAP引擎必须支持Join.
最后,它支持水平扩展,并且可以通过扩展计算节点来提高计算能力,并且没有同步的问题. 里面还有很多东西,如何解决这个问题?我们分解了需求.
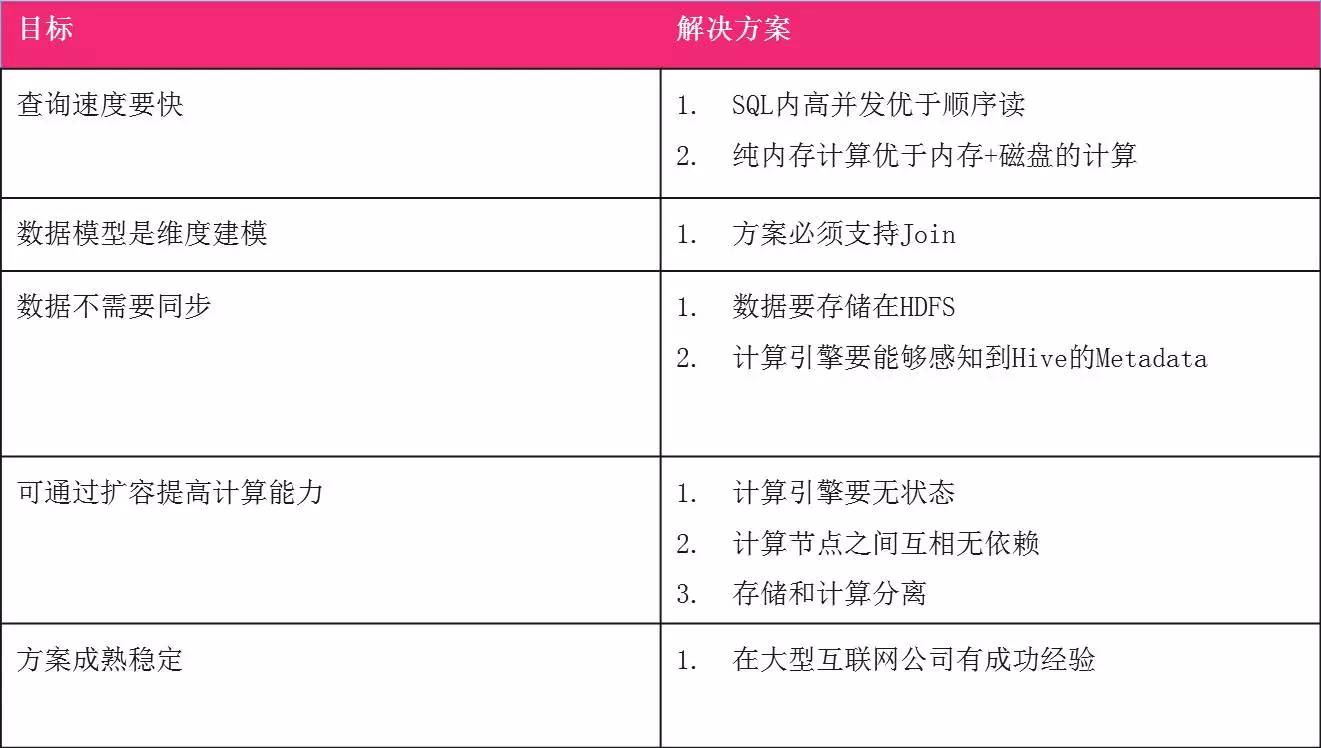
首先,查询速度更快. 我们需要SQL固有的高并发性. 其次olap分析引擎,将内存+硬盘的计算替换为纯内存计算. 内存+硬盘的计算大约是Hive. Hive启动一个SQL,包括实际的计算过程非常缓慢. 第二个是数据模型. 如前所述,数据仓库是维建模. 它必须支持Join. 外部流行的Druid或ES解决方案不适用. 第三是数据不需要同步,这意味着数据需要存储在HDFS上,并且计算引擎必须能够感知Hive元数据. 第四是通过容量扩展来增加计算能力. 如果要在不降低服务质量的情况下实现容量扩展,则最好使计算引擎没有状态,同时,计算节点彼此独立. 最后一点是该解决方案成熟且稳定,因为它正在尝试一种新的OLAP解决方案. 如果此OLAP解决方案不稳定,则会直接影响用户体验. 我们希望当出现问题时,我们不会忙于迅速解决问题.
Presto: Facebook贡献的开源MPP OLAP引擎

这时候Presto进入了我们的视野,它是Facebook贡献的开源MPP OLAP引擎. 这是一个红酒名称,因为开发团队中的每个人都喜欢喝这种品牌的红酒,因此将其命名为. 作为MPP引擎,其处理方法是扫描出所有数据,并使用哈希方法将数据转换为较小的块,以允许不同的节点并发. 处理完结果后,它将迅速返回给用户. 我们看到它的逻辑体系结构是相同的. 它启动一个SQL,然后查找这些数据在哪个HDFS节点上,然后将它们分配给特定的处理,最后返回该数据.
为什么是Presto
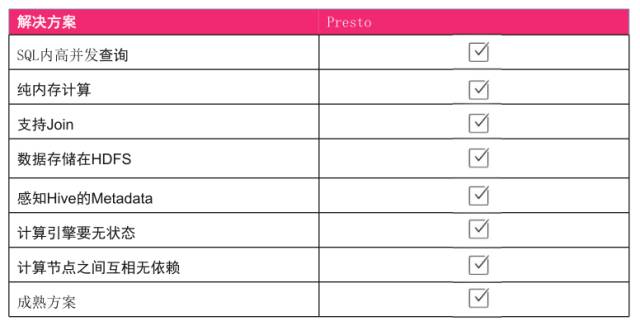
原则上,MPP引擎支持高并发查询. 纯内存计算,它是纯内存,无需与硬盘进行任何交互. 第三,因为它是一个SQL引擎,所以它支持Join. 另外,不存储数据,而是将数据直接存储在HDFS上. 计算引擎没有状态,并且可以满足计算节点彼此不依赖的情况. 另外,它也是一个成熟的解决方案,Facebook本身是一个大型制造商,Google在国外使用,而JD.com有其自己的版本,因此这件事实际上可以满足我们的需求.
Presto性能测试
在使用POC之前,我们先进行了POC. 我们尝试将常用的SQL放在同一台计算机上的两个计算引擎GP和Presto上(我们不使用TPCH的原因是我们的平台SQL更适合我们的情况). 同时配置和节点号完成基准性能测试后,您可以看到结果非常令人满意.
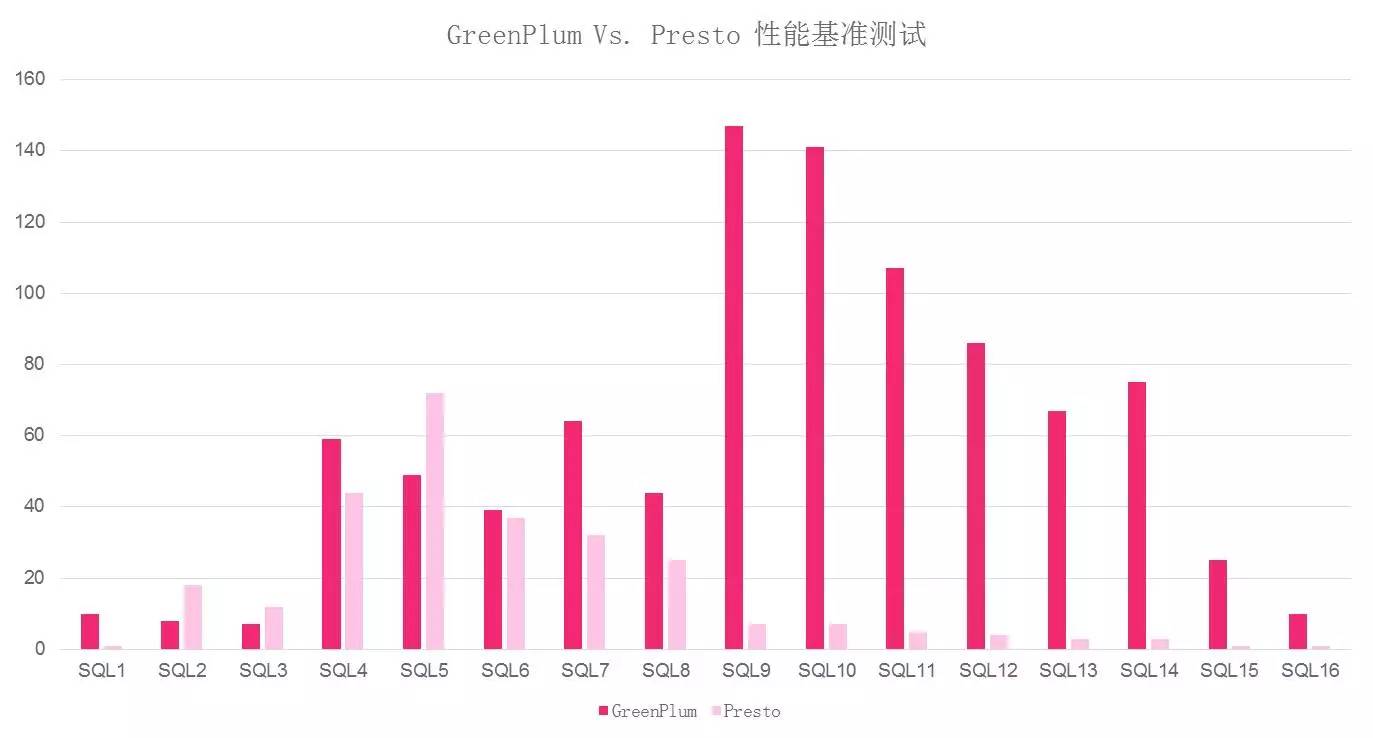
总的来说,同一节点的Presto的性能比GreenPlum高70%,并且SQL9到SQL16的时间从100多秒下降到10秒,这表明它的改进非常明显.
当我们完成性能测试时,我们一位专门从事发动机开发的同学喊道,对您说,用Presto代替GreenPlum.

第3阶段
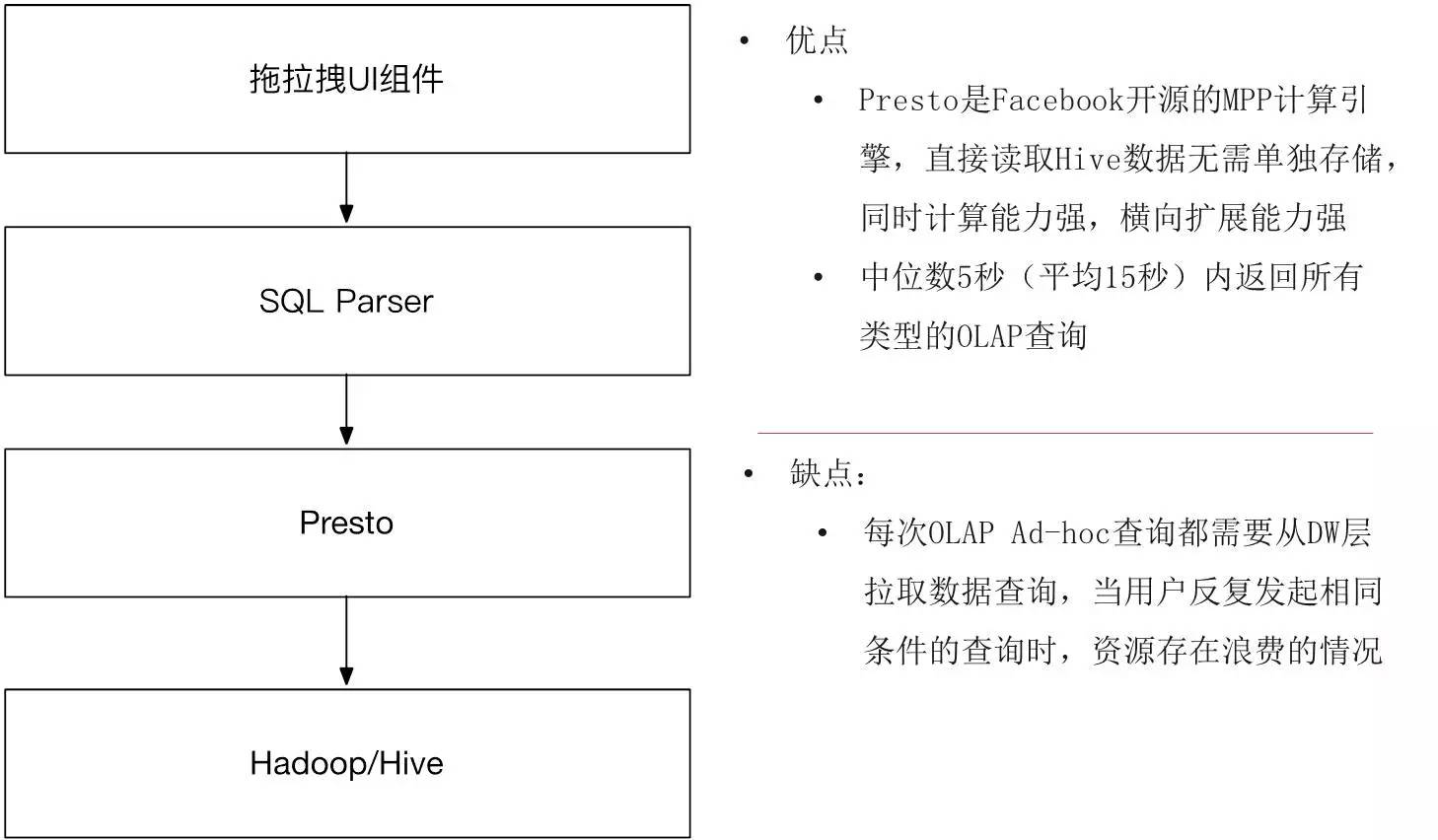
在引入Presto之后,我们发现整个数据结构变得非常平滑. 上层使用拖放式UI组件生成SQL,并将其发送给Parser,然后将其传递给Presto进行执行. 无论是流量数据,掩埋点还是暴露数据,返回都非常快. 同时,我们还扩展了方案,以包括诸如订单和销售之类的事务分析. 使用后,平均返回时间为5秒,平均返回时间为15秒. 基本上,这次可以返回所有OLAP查询. 由于使用了DW数据,因此维度更加丰富,并且解决了大多数需求问题.
使用Presto后,用户的第一反应是其为何如此之快以及使用了哪种黑色技术. 但是运行一段时间后,我们观察到用户的行为是什么,正在查询哪种SQL,维度和指标的组合是什么,并希望进行一些优化.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-205407-1.html
-

-
任江鹏
家里利息为0
 Excel日期格式转换摘要
Excel日期格式转换摘要 有效件照 资讯●海关保安服务项目招标公告
有效件照 资讯●海关保安服务项目招标公告 正版操作系统多少钱最近,网上出现了PS4破解机,淘宝上一些卖
正版操作系统多少钱最近,网上出现了PS4破解机,淘宝上一些卖 推荐我一个软件来测试计算机的性能,鲁大师或其他. 拜托上帝,最好要更详细
推荐我一个软件来测试计算机的性能,鲁大师或其他. 拜托上帝,最好要更详细
南方黑芝麻那个小孩舔碗的广告不错