以KNN为例,使用sklearn进行数据分析和预测
电脑杂谈 发布时间:2020-05-07 15:11:05 来源:网络整理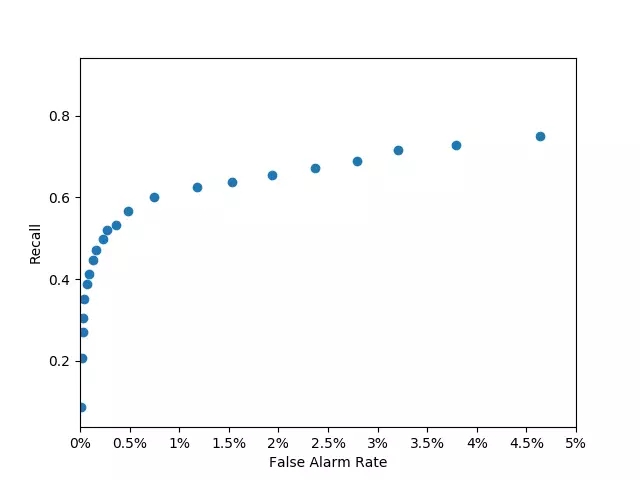
相关的库包括:
导入代码如下:
import pandas as pd
import numpy as np
from sklearn.neiors import KNeiorsClassfier as KNN
数据是sklearn的乳腺癌数据.
from skleanr.datasets import load_breast_cancer
data=load_breast_caner()

数据主要分为两部分: 数据和目标. 导入这两部分并将变量设置到DataFrame中以查看基本形状.
X = data.data
y = data.target
sklearn的数据具有相对固定的形式. 数据的主要属性是:
子数据集和测试集:
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X, y, test_size=0.3)

注意:
clf = KNN(n_neiors = 5)
clf=clf.fit(Xtrain,Ytrain)
clf是训练有素的模型,您可以调用该界面以查看并进行预测和评分. 常用的是预测训练和预测数据的选择,得分和邻居. 这三个用于预测,评分和寻找最近的邻居.
选择训练集和测试集时,可能存在以下问题.
测试集和训练集每次都不同,因此模型的效果每次都不同. 选择测试集和训练集有时会极大地影响模型. -特别是在数据整理时.

因此需要交叉验证以找到最佳参数并再次训练模型.
K折交叉验证方法:
cvresult=CVS(clf,X,y,cv=5)
CVS的第一个参数是训练模型,而参数cv是折叠.
cvresult.mean() # 取得均值
cvresult.var() #取得方差
方差可以用来绘制学习曲线:
score =[]
var_=[]
krange=range(1,21)
for i in krange:
clf=KNN(n_neiors=i)
cvresult=CVS(clf,X,y,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
plt.plot(krange,score,color='k')
plt.plot(krange,np.array(score)+np.array(var_)*2,c='red',linestyle='--')
plt.plot(krange,np.array(score)-np.array(var_)*2,c='red',linestyle='--')
bestindex=score.index(max(score))
print(bestindex+1)
print(score[bestindex])
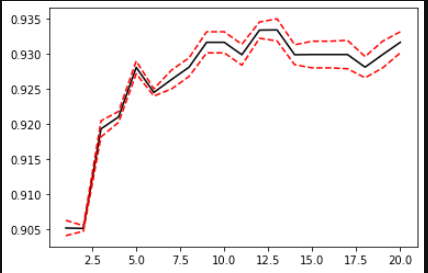
但是,如果数据分为: 训练数据,测试数据. 训练数据分为一部分验证数据,因此用于训练的数据甚至更小.
KNN是距离模型,因此需要归一化. 也就是说,从最差值中减去数据,然后施加最差值:
\ [x ^ * = \ frac {x-min(x)} {max(x)-min(x)} \]
归一化应分为训练集和测试集. (由于归一化中使用的极值可能是测试集的数据,因此该数据将提前向模型公开)
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X_,y,
test_size=0.3,
random_state=420)
MMS=nms().fit(Xtrain) #MMS中,有Xtrain的min,和极差
Xtest_=MMS.transform(Xtest)
Xtrain_=MMS.transform(Xtrain) #分别对训练集、测试集进行归一化
如果您随后运行学习曲线代码训练和预测数据的选择,效果会更好:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-201881-1.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
每日福利
 通用计算系统_通用路由平台vrp下载_图形处理器通用计算
通用计算系统_通用路由平台vrp下载_图形处理器通用计算 logback多线程死锁
logback多线程死锁 预装的win8 / 8.1笔记本将win7安装在GPT分区下,以形成双系统
预装的win8 / 8.1笔记本将win7安装在GPT分区下,以形成双系统 技嘉主板电脑怎么装win7系统|技嘉主板U盘装w7系统步骤
技嘉主板电脑怎么装win7系统|技嘉主板U盘装w7系统步骤热点图片
可口可乐