三种OLTP缓存设计的比较
电脑杂谈 发布时间:2020-05-07 11:30:13 来源:网络整理
作者| @赵裕众
针对OLTP场景的Oracle,MySQL,OceanBase三个关系系统,它们的缓存设计之间有何异同,本文将带您了解.
Oracle的内存主要分为SGA(系统全局区域)和PGA(程序全局区域). SGA由所有服务和后台进程共享,而PGA对于每个服务和后台进程都是唯一的. 在Oracle官方文档中附加一个内存.

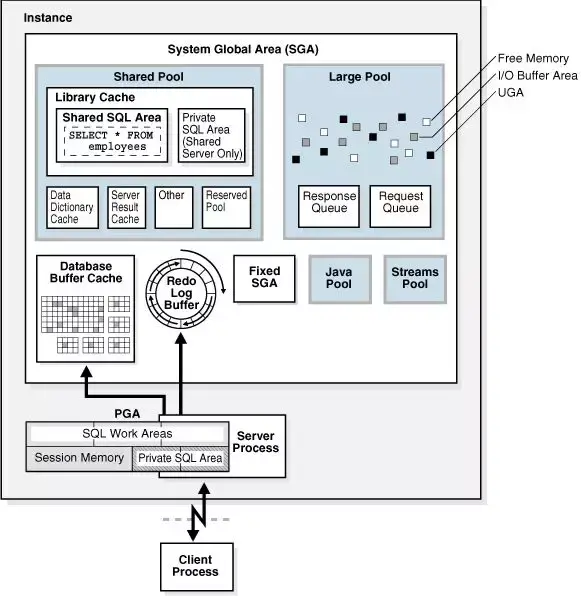
如上图所示,SGA包含许多不同的内存结构,例如缓冲区高速缓存,重做日志缓冲区,共享池,大型池,Java池,Strems池等. 共享池包含库高速缓存,数据字典缓存,结果缓存,保留池和其他数据结构.

从缓存的角度来看,Oracle中有许多不同类型的缓存,例如缓冲区缓存(缓存数据页面),库缓存(缓存sql,存储过程,计划和其他对象),结果缓存(缓存查询结果) ),尽管它们在结构上都是Cache,但是它们的实现却有很大不同. 例如,缓存在缓冲区高速缓存中的数据都是固定长度的存储页面,并且可以修改存储页面. 修改后的页面将变为脏页,并在适当时留给后台进程将其刷新到磁盘. 和结果缓存缓存的结果是变长查询结果,通常是只读的. 当数据更改时,查询结果需要无效. 因此,Oracle将缓冲区高速缓存和其他高速缓存划分为不同的模块进行管理. 在Oracle 10g之前,DBA需要手动设置SGA中每个内存模块的大小,例如缓冲区高速缓存,重做日志缓冲区,共享池,大池等. 在Oracle 10g,DBA中引入了自动共享内存管理(ASMM). 只需设置SGA的总大小,Oracle即可自动调整SGA中每个模块的内存使用情况;此外,Oracle 11g(AMM)中引入了自动内存管理,只要DBA设置总内存占用量,Oracle便可以自动调整SGA和PGA的大小.
通常来说,在Oracle中,缓冲区高速缓存将占据大部分内存. 在结构上,缓冲区高速缓存是由固定长度的内存块(由参数DB_BLOCK_SIZE指定,默认为8KB)组成的链表,由LRU算法消除. 同时,冷脏页由DBW进程定期刷新到磁盘. 在经典的LRU算法中,每次读取数据都需要将记录移至链表的开头,这意味着每次读取都需要向链表添加写锁,这对于高度并发的数据读取而言并不友好,因此Oracle改进了经典的LRU算法. 在Oracle中,逻辑上将LRU列表分为两半,其中一半是热链,一半是冷链. 同时,缓冲区触摸计数将记录在每个数据块上. 固定(通常是读取或写入)数据块后oltp ,它将确定此数据块的触摸计数是否在3s之前增加,如果未增加,则在Touch Counts上增加1. 请注意,数据块不会移到链接列表的开头,因此无需锁定LRU链接列表,从而提高了高并发性下数据读取的性能. 如果对缓冲区高速缓存进行了新的写操作,但是缓冲区高速缓存中没有可用的内存块,则Oracle首先将寻找可从冷链末尾消除的内存块. 如果相应存储块的“触摸计数”较大,则该存储块将移至热链,并且“触摸计数”返回0;否则,“存储计数”返回0. 如果该存储块的相应触摸计数较小,则将其删除以写入新数据,并将新写入的数据放入冷链头中.
Innodb当前是MySQL的默认存储引擎,因此我们仅在下面讨论Innodb的Cache设计. Innodb的存储引擎体系结构与Oracle类似. 还有一个缓冲池来缓存数据页面(对应于Oracle的Buffer Cache,默认页面大小为16KB),还有Query Cache(用于Oracle的Result Cache)来缓存查询结果,但是内存管理不如Oracle优雅,并且缓冲池和查询缓存的大小需要由DBA手动设置. 缓冲池中的数据页是同时读取和写入的. 修改内存页后oltp ,它们将变为脏页. 当脏页数达到一定百分比时,后台线程将负责将脏页刷到磁盘.

Innodb的缓冲池也基于LRU,这也改进了经典的LRU算法. Innodb的缓存消除算法与Oracle非常相似. 它还在逻辑上将LRU列表分为两部分. Innodb的一部分称为Young Buffer,一部分称为Old Buffer. Young Buffer存储热数据,默认为整个Buffer的5/8. 旧缓冲区存储冷数据,默认为整个缓冲区的3/8. 当从磁盘将新页面读入缓冲池时,它将被放置在旧缓冲区的头部(即,整个LRU列表的中间5/8位置);当再次访问旧缓冲区中的页面时,将其抬高至年轻缓冲区的头部. 请注意,频繁访问Young Buffer中的元素不会锁定链接列表,从而提高了对热数据的高并发访问性能.
OceanBase的Cache设计与Oracle和MySQL完全不同. 由于OceanBase存储引擎基于LSM-tree架构,因此所有修改都只会写入memtable,而sstable是只读的,这意味着OceanBase Cache是只读的Cache,因此没有与肮脏相关的逻辑页面,这相对于传统会更简单;但是同时,我们将对存储在sstable中的数据进行编码和压缩,这意味着与传统Cache相比,我们需要存储的数据是可变的,而不是固定的长度. 内存管理要复杂得多. 另外,OceanBase是面向多租户的分布式系统. 除了消除像传统这样的缓存内存之外,缓存内部还需要多租户内存隔离.
类似于Oracle和MySQL,在OceanBase中,将有许多不同类型的Cache,除了用于缓存稳定数据的块缓存(类似于Oracle和MySQL的缓存),还有行缓存(缓存数据行,日志缓存(用于缓存重做日志),位置缓存(用于缓存数据副本的位置),架构缓存(用于缓存表架构信息),布隆过滤器缓存(用于缓存数据的静态布隆过滤器) ,快速过滤以进行空气检查等),类似于Oracle的AMM,我们设计了一个统一的Cache框架,该框架管理着针对不同租户的所有不同类型的Cache,对于不同类型的Cache,将配置不同的优先级,并且不同类型的缓存会根据各自的优先级和数据访问热度相互挤占;对于不同的租户,将为相应的租户配置内存使用量的上限和下限,并根据uppe相互挤压r和每个租户的内存下限以及整个服务器的内存上限.

为了处理可变长度数据的问题,OceanBase的基础缓存框架将内存划分为多个2MB大小的内存块,并且内存的应用程序和释放单位为2MB. 可变长度数据仅打包在2MB的存储块中. 为了支持数据的快速定位,在Hashmap中存储了指向相应数据的指针,其总体结构如下图所示:
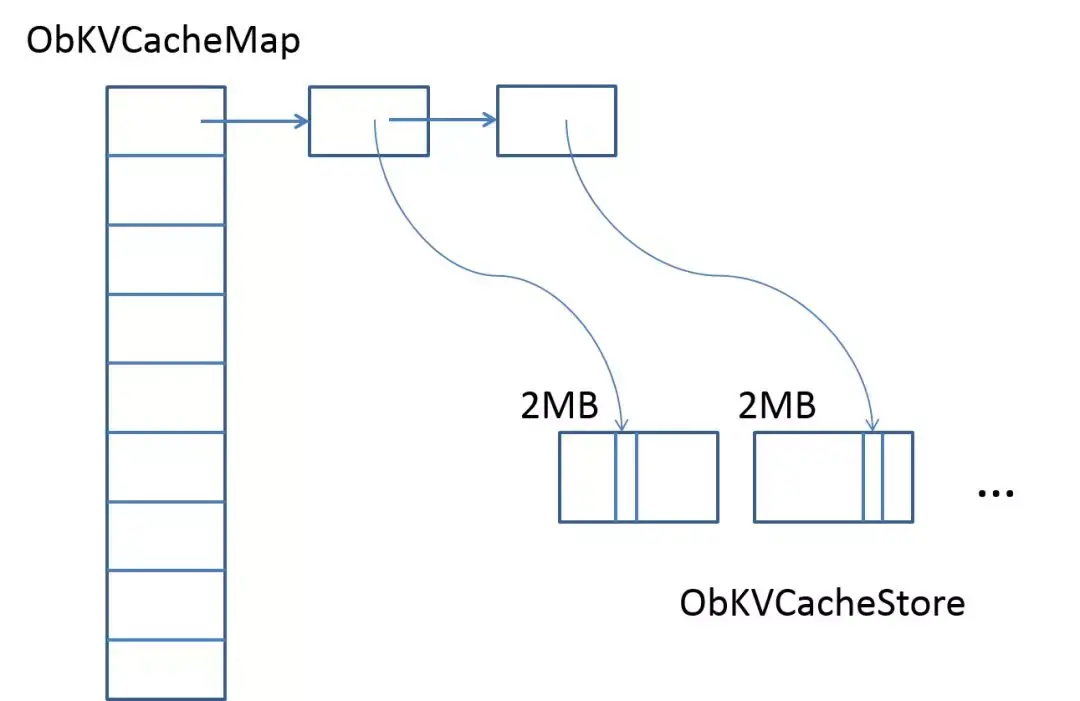
整体上以2MB为单位消除了高速缓存. 我们将根据访问热量计算每个2MB内存块上每个元素的得分. 访问频率越高的内存块得分越高,后台线程也会定期对所有2M内存块的得分进行排序,并消除得分较低的内存块. 对于总体分数较低但具有热点数据的2MB内存块,我们会将热点数据从“冷块”移至“热点”,以避免消除热点数据. 在数据结构方面,我们没有维护类似于Oracle和MySQL的LRU链表,因此对于数据读取,OceanBase的Cache访问几乎是无锁的(HashMap上的Bucket锁除外),并且对热数据的高并发访问更加友好. 在消除时,我们将考虑租户的内存上限和下限,并控制每个租户使用的缓存内存量.

如上所示,在测试的前75 s中,我们将tenant1的内存上限设置为3G,将下限设置为2G,将tenant2的内存上限设置为4G,将下限设置为3G. 75年代后,我们设置了tenant1和tenant2的内存配置互换,可以看出,可以更好地隔离租户之间的内存使用情况.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-201700-1.html
-

-
刘昶
说别人幼稚的你真幼稚
-
李凯
让美猪死他个上千
 【上海校区】(一):Hadoop概述及MapReduce程序工作原理
【上海校区】(一):Hadoop概述及MapReduce程序工作原理 中国计算机产业发展大事记
中国计算机产业发展大事记 长输管线3层结构聚烯烃防腐蚀涂层阴极剥离的研究进展_二烯烃的加聚_荣聚诈骗案进展
长输管线3层结构聚烯烃防腐蚀涂层阴极剥离的研究进展_二烯烃的加聚_荣聚诈骗案进展 重新安装系统后,我不小心重新分区了,如何获取其他分区的数据
重新安装系统后,我不小心重新分区了,如何获取其他分区的数据
让我们知道你一直记得海浪的好