chouxi9547的博客
电脑杂谈 发布时间:2020-05-06 20:00:48 来源:网络整理
AWK是出色的文本处理工具. 它不仅是Linux中功能最强大的数据处理引擎之一,而且在任何环境中均如此. 这种编程和数据处理语言的最大功能(名称来源于其创始人Alfred Aho,Peter Weinberger和Brian Kernighan的姓氏的首字母)取决于一个人的知识. AWK提供了非常强大的功能: 它可以执行样式加载,流控制,数学运算符,过程控制语句,甚至内置变量和函数. 它几乎具有完整语言应具有的所有精美功能. 实际上,AWK确实有其自己的语言: AWK编程语言,由三位创建者正式定义为“样式扫描和处理语言”. 它使您可以创建简短的程序来读取输入文件,排序数据,处理数据,对输入进行计算,生成报告以及无数其他功能.
awk'{pattern + action}'{文件名}
尽管操作可能很复杂,但语法始终是相同的,其中pattern表示AWK在数据中查找的内容,而action是在找到匹配内容时执行的一系列命令. 花括号({})不一定总是出现在程序中,而是用于根据特定的模式对一系列指令进行分组. pattern是要表示的正则表达式,用斜杠括起来. awk语言的最基本功能是根据文件或字符串中的指定规则浏览和提取信息. 在awk提取信息之后,可以执行其他文本操作. 完整的awk脚本通常用于格式化文本文件中的信息. 通常,awk作为文件单位处理. Awk接收文件的每一行,然后执行相应的命令来处理文本.
awk [-F字段分隔符]'commands'输入文件,其中命令是真实的awk命令,[-F字段分隔符]是可选的. 输入文件是要处理的文件. 在awk中,在文件的每一行中,由域分隔符分隔的每个项目都称为域. 通常,在不命名-F域分隔符的情况下,默认域分隔符为空格.
将所有awk命令插入文件,并使awk程序可执行. 然后,awk命令解释器将用作脚本的第一行,通过再次键入脚本名称来调用它. 等效于shell脚本的第一行: #! / bin / sh可以替换为: #! / Bin / awk
awk -f awk脚本文件输入文件其中awk数组初始化,-f选项将awk脚本加载到awk脚本文件中,输入文件与上面相同.
入门示例(删除Linux上最近登录的五个用户的用户名)
# 下面是取出最近登录的五个用户的信息
[root@localhost ~]# last -n 5
root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
test pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
root tty1 120.239.75.53 Fri Sep 5 14:09 - 14:10 (00:01)
# 如果只是显示最近登录的5个帐号的用户名
$ last -n 5 | awk '{print $1}'
root
test
root
dmtsai
root
# awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
入门示例(仅显示/ etc / passwd帐户)
$ cat /etc/passwd | awk -F ':' '{print $1}'
root
daemon
bin
sys
# 这种是awk+action的示例,每行都会执行action{print $1}。
# -F指定域分隔符为':'。
# 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
$ cat /etc/passwd | awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
# 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
$ cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/nosh
# awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
# 搜索/etc/passwd有root关键字的所有行
$ awk -F: '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
# 这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
# 搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
# 搜索/etc/passwd有root关键字的所有行,并显示对应的shell
$ awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
# 这里指定了action{print $7}
Awk具有许多用于设置环境信息的内置变量. 这些变量可以更改. 这是一些最常用的变量.
$n # 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 # 这个变量包含执行过程中当前行的文本内容。
ARGC # 命令行参数的数目。
ARGIND # 命令行中当前文件的位置(从0开始算)。
ARGV # 包含命令行参数的数组。
CONVFMT # 数字转换格式(默认值为%.6g)。
ENVIRON # 环境变量关联数组。
ERRNO # 最后一个系统错误的描述。
FIELDWIDTHS # 字段宽度列表(用空格键分隔)。
FILENAME # 当前输入文件的名。
NR # 表示记录数,在执行过程中对应于当前的行号
FNR # 同NR,但相对于当前文件。
FS # 字段分隔符(默认是任何空格)。
IGNORECASE # 如果为真,则进行忽略大小写的匹配。
NF # 表示字段数,在执行过程中对应于当前的字段数。 print $NF答应一行中最后一个字段
OFMT # 数字的输出格式(默认值是%.6g)。
OFS # 输出字段分隔符(默认值是一个空格)。
ORS # 输出记录分隔符(默认值是一个换行符)。
RS # 记录分隔符(默认是一个换行符)。
RSTART # 由match函数所匹配的字符串的第一个位置。
RLENGTH # 由match函数所匹配的字符串的长度。
SUBSEP # 数组下标分隔符(默认值是34)。
此外,$ 0变量引用整个记录. $ 1表示当前行的第一个字段,$ 2表示当前行的第二个字段,...依此类推.
$ awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf代替print可以使代码更简洁易读
awk -F': ''{printf(“文件名: %s,行号: %s,列: %s,行内容: %s \ n”,文件名,NR,NF,$ 0)}'/等/ passwd
Awk同时提供打印和printf功能. 打印功能的参数可以是变量,值或字符串. 字符串必须用双引号引起来,并且参数用逗号分隔. 如果没有逗号,则将参数串联起来并且无法区分. 在这里,逗号的作用与输出文件的定界符相同,只是后者是一个空格. printf函数的用法基本上与C语言中的printf相似awk数组初始化,可以格式化字符串. 当输出复杂时,printf易于使用,代码也易于理解.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%% %%%%%%%%%%%%%%%%%
除了awk的内置变量外,awk还可以自定义变量.
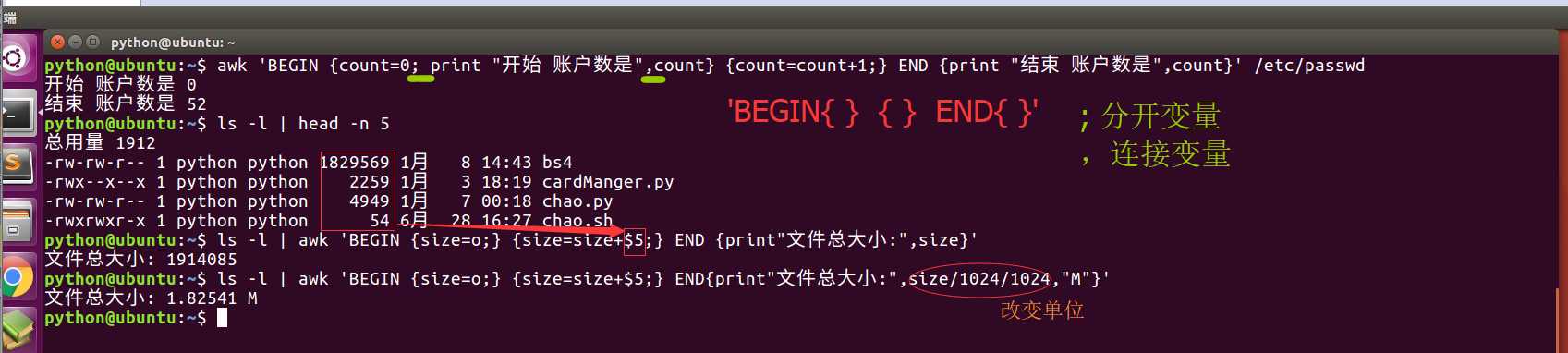
以下计算/ etc / passwd中的帐户数量

awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
......
user count is 40
count是一个自定义变量. 上一个操作{}中只有一个打印,实际上,打印只是一个语句,而操作{}可以有多个语句,以a;分隔.
这里没有初始计数,尽管默认值为0,但是将其初始化为0是适当的:
awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd
[start]user count is 0
root:x:0:0:root:/root:/bin/bash
...
[end]user count is 40
计算文件夹中文件占用的字节数
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size}'
[end]size is 8657198
如果以M为单位显示:
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.25889 M
请注意,统计信息不包括文件夹的子目录.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-200912-1.html
-
 任亚苹
任亚苹 -
李保江
有什么好奇怪的