[搜索算法]二进制排序树搜索方法
电脑杂谈 发布时间:2020-04-27 18:24:42 来源:网络整理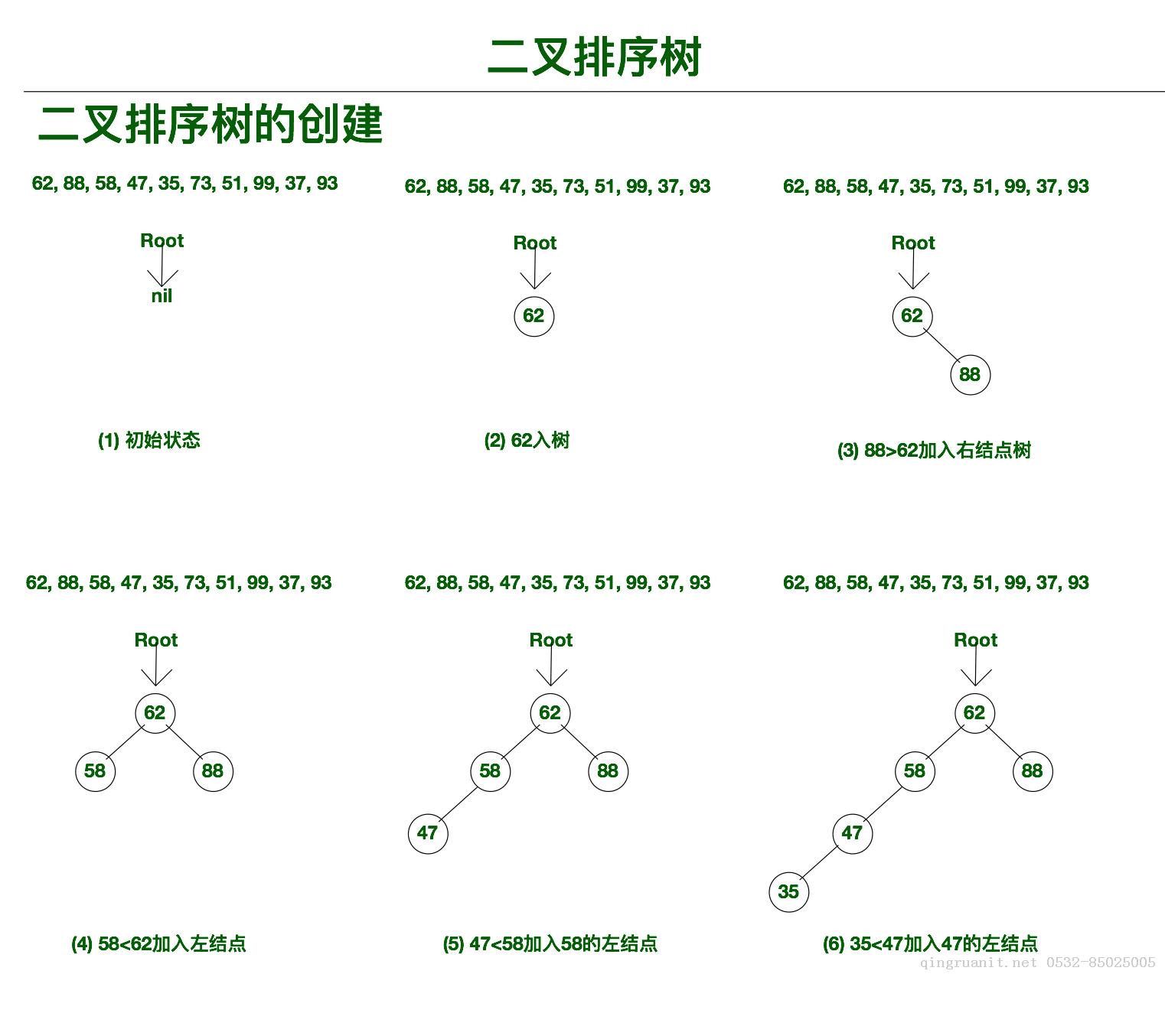
本文将介绍二叉排序树的搜索算法.
在上一篇文章中,我们学习了两半搜索. 尽管二分之一搜索算法提高了搜索效率,但二分之一搜索需要序列排序. 需要移动大量元素,并且使用半查找搜索显然无效.
有没有办法使搜索效率仍然很高,并且可以轻松地插入和删除?基于此,我们可以使用动态查找表,该表是在查找过程中动态生成的. 根据不同的用途,动态查找表可以分为:
二元排序树平衡二叉树红黑树B-树B +树关键树
本文重点介绍二进制排序树.
二叉排序树也称为二叉搜索树和二叉搜索树,其定义如下:
二进制排序树是满足以下属性的空树或二进制树:
如果左子树不为空,则左子树上所有节点的值小于根节点的值. 如果右子树不为空,则右子树上所有节点的值都大于或等于根. 该节点的值以及左右子树本身都是二进制排序树
下图显示了二进制排序树:

中间顺序遍历,遍历顺序为: 3 12 24 37 45 53 61 78 90 100,
您会发现序列遍历结果是一个递增的序列.
二进制排序树的性质是从中得出的:
通过依次遍历非空二进制排序树获得的数据元素序列是按关键字排列的递增有序序列.
首先让我们分析一下二进制排序树(例如以下二进制排序树)的搜索过程:

如果要查找的元素的值为105,如何查找?

首先将其与根节点105 <122进行比较,这意味着要找到的元素的值在其左子树上;
然后将其与左侧子树的根节点进行比较,即105> 99,这意味着要找到的元素的值在当前根节点的右侧子树上;
让它与右子树的根节点105 <110进行比较,这意味着要找到的元素的值在当前根节点的左子树上;
最后,将其与左子树的根节点进行比较,即105 = 105,搜索成功.
例如,如果在排序树中找不到要查找的元素,则我要查找的元素的值为103,然后与105进行比较后,发现要查找的元素应位于元素值为105的节点的左子树. 左子树为空,表示搜索失败.
掌握了二进制排序树的搜索原理后,可以详细实现该算法. 在此之前,请定义二进制排序树的存储结构:
typedef struct{
int key;
//还可定义其它数据信息
}ElemType;
typedef struct BSTNode{
ElemType data; //数据域
struct BSTNode *lchild,*rchild;
}BSTNode,*BSTree;
结合刚才对搜索过程的分析,我们可以总结出以下内容:
经过分析,该算法实现起来非常简单,代码如下:
BSTree SearchBST(BSTree t,int key){
if(t == NULL || key == t->data.key){
return t;
}else if(key < t->data.key){
return SearchBST(t->lchild,key); //在左子树上继续查找
}else{
return SearchBST(t->rchild,key); //在右子树上继续查找
}
}
如下所示:

这是一个二进制排序树. 如果要查找的元素的值为50,则只需比较一次;
如果要查找的元素的值为30,则需要比较两次;
如果要查找的元素的值为40,则需要比较三遍;
因此,用于查找元素值的比较次数与排序树中的层数有关. 需要比较n次节点元素值才能找到.
二叉排序树的搜索效率还受树的形状的影响,例如序列: 45、24、53、12、37、93.

最好的情况是以下分布:

根据二叉树的性质,树的深度为: “ log2n” +1.
其算法的时间复杂度为: O(log2n).
但是如果分布如下:

搜索效率与顺序搜索效率相同,时间复杂度为: O(n).
这时,我们面临一个问题,如何提高不平衡二进制排序树的搜索效率?
我们需要做的是“平衡”那些不平衡的二叉树排序二叉排序树查找,并尝试使二叉树形式保持平衡.
在学习如何“平衡”二进制排序树之前,我们必须学习二进制排序树的其他一些操作,例如: 插入,删除,生成.
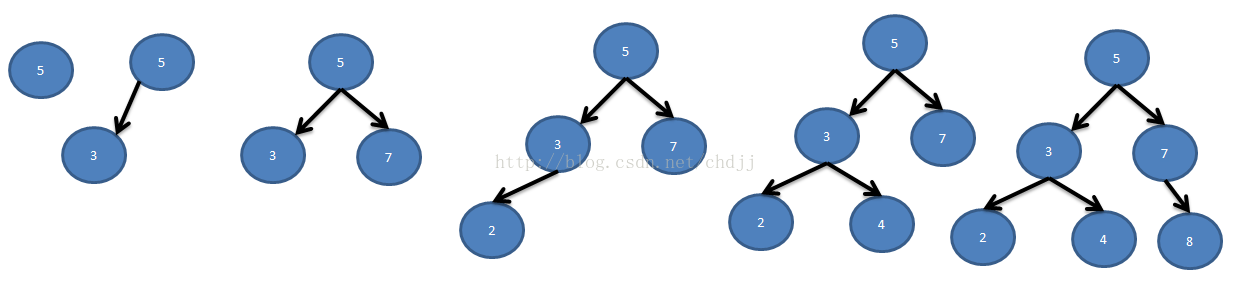
让我们看一下如何首先插入,例如下图中的二进制排序树:

如果要将元素值40插入排序树,则前提是必须在插入后仍然保持二进制排序树的性质. 如何实现?
首先将其与根节点40 <45进行比较,因此应将元素插入到根节点的左侧子树中;
然后将其与左子树的根节点40> 12进行比较,因此应将元素插入到根节点的右子树中;
将其与右子树的根节点进行比较,40> 37,因此应将元素插入到根节点的右子树中;
由于根节点没有右子树,因此可以将元素值40直接插入到该位置.

因此,插入算法的思想总结如下:
如果树中已经存在,则不会再次插入. 如果不在树上
查找直到叶节点的左或右子树为空,然后插入
该节点应为叶节点的左或右子节点
掌握算法思想后,算法实现非常简单,代码如下:
int SearchBST(BiTree T,int key,BiTree f,BiTree p){
//如果 T 指针为空,说明查找失败,令 p 指针指向查找过程中最后一个叶子结点
if (!T){
p = f;
return 0;
}
//如果相等,令 p 指针指向该关键字
else if(key == T->data){
p = T;
return 1;
}
//如果 key 值比 T 根结点的值小,则查找其左子树;反之,查找其右子树
else if(key < T->data){
return SearchBST(T->lchild,key,T,p);
}else{
return SearchBST(T->rchild,key,T,p);
}
}
//插入函数
int InsertBST(BiTree T,ElemType e){
BiTree p = NULL;
//如果查找不成功,需做插入操作
if (!SearchBST(T, e,NULL,p)) {
//初始化插入结点
BiTree s = (BiTree) malloc(sizeof(BSTNode));
s->data = e;
s->lchild = s->rchild = NULL;
//如果 p 为NULL,说明该二叉排序树为空树,此时插入的结点为整棵树的根结点
if (!p) {
T = s;
}
//如果 p 不为 NULL,则 p 指向的为查找失败的最后一个叶子结点,只需要通过比较 p 和 e 的值确定 s 到底是 p 的左孩子还是右孩子
else if(e < p->data){
p->lchild = s;
}else{
p->rchild = s;
}
return 1;
}
//如果查找成功,插入失败
return 0;
}
此算法实际上非常简单. 如果您仔细品尝,便可以理解. 如果您不了解,那就没关系. 让我粗略地分析一下.
首先二叉排序树查找,在插入之前,我们必须确定要插入的元素的值是否存在于原始二进制排序树中,因此我们必须改进搜索算法.
改进的搜索算法需要传递四个参数. 没有介绍前两个. 它们是最初需要的参数. 我们添加了两个参数: BiTree类型的变量f; BiTree类型的变量p.
这两个变量用于协助搜索. 首先,我们需要确定当前二进制排序树的根节点是否为空. 如果为空,则搜索结束. 变量p指向搜索过程中的最后一个节点. 指向,现在让它指向变量f,因为变量f指向搜索过程中的最后一个节点,稍后您将了解.
如果根节点不为空,则需要确定要插入的元素的值是否等于当前节点的元素值. 如果它们相等,则搜索成功并且搜索结束.
如果它们不相等,则有两种情况:
要插入的元素的值小于当前节点元素的值,您应继续在当前节点的左子树中搜索并递归调用自身. 注意这里传递的参数,第一个参数当然是当前节点的左子节点;第二个参数是要插入的元素的值;第三个参数应该是搜索过程中的最后一个节点,因为当前节点不为空,我们需要找到它的左子树,因此此搜索过程中的最后一个节点应该是当前节点,因此传入t;第四个参数直接传递p来插入要插入的元素的值,该值要大于当前节点元素的值,您应继续在当前节点的右子树中搜索并递归调用自身
这时,递归继续进行,直到搜索结束,我们将实现插入算法.
插入算法也分为几种情况. 通过搜索算法,如果要插入的元素的值已经存在,则不执行if语句块,并且可以直接返回插入失败.
如果插入的元素的值不存在,则还需要执行搜索. 搜索算法必须在叶节点处结束. 此时的叶节点是搜索过程中的最后一个节点.
然后初始化一个新节点,为其数据域和子域分配值,并继续分类讨论. 如果变量p为空,则表示二进制排序树为空,而新节点将直接用作根节点.
如果变量p不为空,则需要将要插入的节点与搜索过程中的最后一个节点进行比较,即: 比较节点p的元素值(如果小于元素值)在节点p中,它被视为其左子节点;否则,作为他们的合适孩子.
不懂得认真思考的学生并不难.
掌握插入操作,生成操作非常简单,只需调用插入算法即可插入序列.
如果要从二进制排序树中删除节点,则不能删除以该节点为根的所有子树,而只能删除该节点,还必须确保删除节点后的二进制树. 仍然满足二进制排序树的性质.
删除节点分为几种情况,例如以下二进制排序树:

如果我们要删除的节点是叶节点,则非常简单,只需直接删除该节点,并将其父节点对应的子字段设置为NULL.
如果要删除的节点只有左子树或只有右子树,则这种情况相对简单,只需将其替换为左子树或右子树即可.
例如,如果要删除元素值40,则直接删除该节点并让其左子节点替换它,如图所示:

如果要删除的节点既有左子树又有右子树,则这种情况比较麻烦,我们需要在中间序列遍历中找到要删除的元素的前驱,让其前驱节点替换它,然后删除前驱节点就足够了.
例如,如果要删除的元素的值为50,则其前体为40,我们将让节点40替换它,然后删除该节点,如图所示:

当然,我们也可以用要删除的节点的后继节点替换,然后删除后继节点.
算法实现如下:
//删除函数
int DeleteBST(BiTree *p)
{
BiTree q, s;
//结点p为叶子结点,直接删除即可
if(!(*p)->lchild && !(*p)->rchild){
*p = NULL;
}
//结点p左子树为空,用其右孩子代替自身
else if(!(*p)->lchild){
q = *p;
*p = (*p)->rchild;
free(q);
}
//结点p右子树为空,用其左孩子代替自身
else if(!(*p)->rchild){
q = *p;
//这里不是指针 *p 指向左子树,而是将左子树存储的结点的地址赋值给指针变量 p
*p = (*p)->lchild;
free(q);
}
//结点p左右孩子均不为空
else{
q = *p;
s = (*p)->lchild;
//遍历,找到结点 p 的直接前驱
while(s->rchild)
{
q = s;
s = s->rchild;
}
//改变结点 p 的值
(*p)->data = s->data;
//判断结点 p 的左子树 s 是否有右子树,分为两种情况讨论
if( q != *p ){
q->rchild = s->lchild;//若有,则在删除直接前驱结点的同时,令前驱的左孩子结点改为 q 指向结点的孩子结点
}else{
q->lchild = s->lchild;//否则,直接将左子树上移即可
}
free(s);
}
return 1;
}
该算法有一定难度,每个人都可以理解删除节点的想法,如果感兴趣的话可以自己研究.
转载:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-191028-1.html
-

-
西楼公
钻进那条缝
-
 如何解决无法识别的USB设备? Win7的完美解决方案无法识别USB设备
如何解决无法识别的USB设备? Win7的完美解决方案无法识别USB设备 tcls core.exe卡硬盘_tgpbrowser.exe_tclscore进程可以关闭
tcls core.exe卡硬盘_tgpbrowser.exe_tclscore进程可以关闭 java多线程(二)多线程同步与死锁
java多线程(二)多线程同步与死锁 将自己开发的Android应用程序编译到系统Image中是否很好
将自己开发的Android应用程序编译到系统Image中是否很好
只是认得崇洋媚外的心理在作怪