[数据结构]二进制排序树,AVL树,B,B +树的摘要
电脑杂谈 发布时间:2020-04-26 16:17:47 来源:网络整理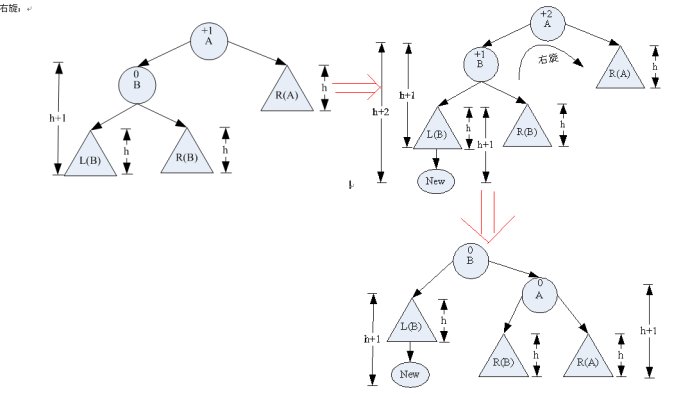
简介:
二分类树基于公共二叉树,它限制了根节点,左节点和右节点的关键字大小.
好处
搜索时,可以使用左右子节点与根节点之间的大小关系来减少顺序搜索的时间复杂度.
缺点:
由于将排序序列转换为二进制排序树,因此存在多种形式. 因此,在某些情况下,二进制排序树的搜索时间复杂度是无法估计的,而在最坏的情况下,它会退化为顺序搜索.
简介:

AVL树在二进制排序树的基础上增加了平衡因子的概念,并限制了每个节点左右子树的高度.
好处:
在构建树的过程中,将树的高度保持得尽可能低,从而提高了搜索效率.
缺点:
添加和删除节点时,必须考虑树的平衡. 当某个节点不平衡时,有必要调整并旋转第一个不平衡节点. 因此,增加了维护树的开销.
适用方案:
与一般的二进制排序树相比,搜索速度更快. 但是,添加和删除节点的成本相对较高. 有时,它比节省的速度贵. 因此,它适用于节点数相对固定并且查询速度需要更快的情况.
简介:
红黑树也是二叉排序树. 与AVL树相比二叉排序树算法,红黑树是弱平衡树(在相同数量的节点下,AVL树的高度不高于红黑树). 将颜色属性添加到树中的每个节点
好处:
与严格的AVL树相比,在插入和删除节点元素时,转数变少,因此对于搜索,插入和删除操作,应用红黑树
应用程序:
B树是B树. B树和B +树是为磁盘或其他存储设备设计的平衡多路搜索树(多路,平衡). 与红黑树相比,在相同节点的情况下,B / B +树的高度比红黑树的高度小
B / B +树上的操作时间通常由访问磁盘的时间和CPU计算时间组成,并且CPU速度非常快,因此B树的操作效率取决于磁盘访问次数,关键字总数在相同情况下,B树的高度越小,磁盘I / O花费的时间越少.

自然:
B +树是一种由文件系统生成的B树的变形树(文件目录为第一级索引,仅底部叶节点(文件)保存数据. ),非叶节点仅保存索引不保存实际数据,数据存储在叶节点中.
例如: 有3个文件夹a,b,c. a包含b,b包含c,文件yang.c在c中,a,b,c是索引(存储在非叶节点中). a,b,c只是要找到的yang.c的关键字,实际数据yang.c存储在叶节点上.
所有非叶子节点都可以视为索引部分
自然:
应用程序:
B / B +树主要使用文件系统和进行索引

B / B +树性能分析
n个节点的平衡二叉树的高度为H(即logn),n个节点的B / B +树的高度为logt((n + 1)/ 2)+1
B / B +树性能分析
n个节点的平衡二叉树的高度为H(即logn),n个节点的B / B +树的高度为logt((n + 1)/ 2)+1
如果要将其用作内存中的查找表,则B树不一定比平衡二叉树好,尤其是当m大时. 因为搜索操作的CPU时间为B树上的O(mlogtn)= O(lgn(m / lgt)),并且m / lgt> 1;因此,当m较大时,O(mlogtn)的运行时间比平衡二叉树更长. 因此,在内存中使用B树必须占用较小的m. 通常最小值m = 3,这时B树中的每个内部节点可以有2个或3个子节点,此3阶B树称为2-3树)
为什么在实际应用中,对于操作系统的文件索引和数据索引,B +树比B树更好?
B +树的内部节点没有指向关键字特定信息的指针,因此它们的内部节点小于B树. 如果同一内部节点的所有关键字都存储在同一磁盘块中,则该磁盘块可以容纳的关键字数量越多,一次需要在内存中搜索的关键字越多,以及IO的相对数量读写次数减少.
因为非终结点不是最终指向文件内容的节点,而是仅叶子节点中关键字的索引. 因此,任何关键字搜索都必须采用从根节点到叶节点的路径. 所有关键字查询的路径长度都相同,从而导致每个数据的查询效率相同.
要知道的事:
B树提高了IO性能,并且没有解决元素遍历效率低的问题. 正是为了解决这个问题二叉排序树算法,B +树的应用诞生了. B +树仅需要遍历叶节点即可实现整个树的遍历. 而且中基于范围的查询非常频繁,并且B树不支持此类操作(或者效率太低).
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-189726-1.html
-

-
息夫牧
首要的是加快在成型岛礁上部署空
 ddos僵尸网络_僵尸网络_熊猫烧香
ddos僵尸网络_僵尸网络_熊猫烧香 iPhone / iPad和iOS上最好,最安全的照片加密软件是什么?
iPhone / iPad和iOS上最好,最安全的照片加密软件是什么? 服务器安全防护软件 天融信虚拟化防火墙系统获2017年优秀创新产品
服务器安全防护软件 天融信虚拟化防火墙系统获2017年优秀创新产品 如何在Win10系统中关闭管理共享
如何在Win10系统中关闭管理共享
老美武器强大了用脑少了