MySQL索引哈希索引和自适应哈希索引(自适应哈希索引
电脑杂谈 发布时间:2020-04-26 12:02:37 来源:网络整理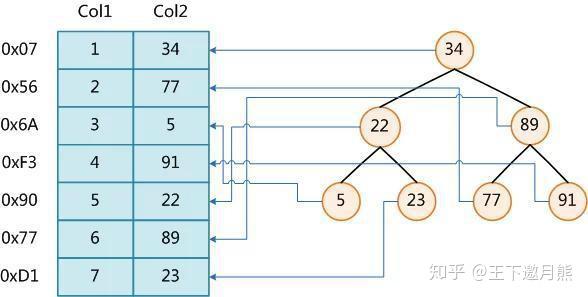
====================================
最近36秒计算的每秒平均值
......
-------------------------------------
插入缓冲区和自适应哈希索引
-------------------------------------
Ibuf: 大小1,空闲列表len 2633,seg大小2635,0合并
合并操作:
插入0,删除标记0,删除0
废弃的操作:
插入0,删除标记0,删除0
哈希表大小为348731,节点堆有2个缓冲区
0.00个哈希/秒,0.00个非哈希/秒
......
从中我们可以看到自适应哈希索引的相关信息: 使用大小,使用情况,每秒使用自适应哈希索引进行搜索等.
MySql存储引擎的特征的详细比较:

我们可以从中看到
您可以使用SHOW ENGINES语句查看MySql Server支持的存储引擎. 例如,作者用于本地测试的5.6.25-log Win版本的结果如下:

可以看出,InnoDB是此版本的MySql的默认存储引擎,只有InnoDB可以支持事务,行级锁定和外键. 支持的MEMORY是基于哈希的,并且数据存储在内存中,适用于临时表. 没有看到同时支持事务和哈希索引的NDB的图.
为确认默认存储引擎,我们创建了一个测试表data_dict_test. 请注意,在表构建语句中未定义存储引擎:
CREATETABLE`data_dict_test`(`data_type`varchar(32)NOTNULLCOMMENT'数据字典类型',`data_code`tinyint(4)NOTNULLCOMMENT'data字典代码',`data_name`varchar(64)NOTNULLCOMMENT'数据字典值', PRIMARYKEY(`data_type`,`data_code`))DEFAULTCHARSET = utf8COMMENT ='数据字典表';
打印结果:
[SQL]创建表`data_dict_test`(
`data_type` varchar(32)NOT NULL COMMENT'数据字典类型',
`data_code` tinyint(4)NOT NULL COMMENT'数据字典代码',
`data_name` varchar(64)NOT NULL COMMENT'数据字典值',
PRIMARY KEY(`data_type`,`data_code`)
)DEFAULT CHARSET = utf8 COMMENT ='数据字典表';
受影响的行: 0
时间: 0.262秒
然后查看已建立表的DDL:

SHOWCREATETABLEdata_dict_test;
打印结果:
创建表`data_dict_test`(
`data_type` varchar(32)NOT NULL COMMENT'数据字典类型',
`data_code` tinyint(4)NOT NULL COMMENT'数据字典代码',
`data_name` varchar(64)NOT NULL COMMENT'数据字典值',
PRIMARY KEY(`data_type`,`data_code`)
)引擎= InnoDB默认字符集= utf8注释='数据字典表'
这次,SHOW CREATE TABLE没有欺骗我们. 尽管在构建表时未指定InnoDB,但已明确给出了InnoDB.
作者建议使用SHOW TABLE STATUS语句查看特定表的存储引擎:
SHOWTABLESTATUSWHERENAME ='data_dict_test';
打印结果:

btree索引:
如果没有特定类型基于hash表的索引结构设计与实现,则大多数为btree索引,这些索引使用btree数据结构存储数据. 除存档引擎外,大多数mysql引擎都支持该索引. 此引擎在5.1之前不支持任何索引. 从5.1开始,仅支持单列自增索引. innodb使用b + tree = btree(不再使用btree)
存储引擎以不同的方式使用btree索引,它们具有不同的性能以及优缺点. 例如,myisam使用前缀压缩技术使索引变小(但它也可能降低连接表查询的性能),但是innodb按照原始数据格式存储,例如: myisam索引是指物理索引的行数据的位置,innodb指的是基于主键的索引行.
Btree通常意味着所有值都按顺序存储,并且每个叶子页面到根的距离都是相同的
下图是innodb索引工作的. myisam使用的结构不同,但是基本思想相似:
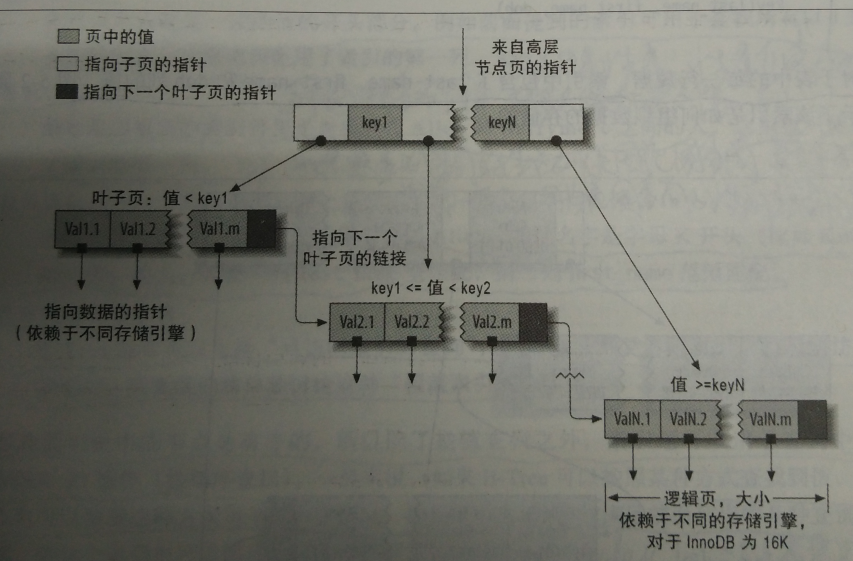
图片来自高性能mysql的第三版
btree索引可以加快访问数据的速度,因为存储引擎不再需要执行全表扫描来获取所需的数据. 相反,它从索引的根节点开始搜索,并且根节点的插槽存储了指向子节点. 根据这些指针,存储引擎将搜索下层. 通过比较节点页面的值和要找到的值,可以找到合适的指针来进入子节点的下一层. 这些指针实际上定义了子节点页面中值的上限和下限. 最后,存储引擎要么找到对应的值,要么记录不存在.
叶节点很特殊. 它们的指针指向索引的数据,而不指向其他节点页面(不同的引擎指针类型不同). 实际上,根节点和叶节点之间可能有多层节点页面. 树的深度与桌子的大小直接相关.
btree树的索引列是按顺序组织和存储的,因此非常适合查找范围数据,例如
有一张桌子:
创建表人员(姓氏varchar(50)不为空,姓氏varchar(50)不为空,dob日期不为空,性别枚举('m','f')不为空,键(姓氏,名字,dob) );
对于表中的每一行数据,索引包含last_name,first_name和dob列的值. 下图显示了索引如何组织数据存储:

图片来自高性能mysql的第三版
注意: 当在create table语句中定义索引时,索引会根据列顺序对多个值进行排序. 在上图中,当最后两个值的名称相同时,它们将根据出生日期进行排序.
可以使用btree索引的查询类型. btree索引用于完整的键值,键值范围或键前缀搜索,其中键前缀搜索仅适合基于最左前缀的搜索. 在上一个示例中创建的多列索引对以下类型的查询有效:
A: 完全匹配值
全值匹配是指匹配索引中的所有列,可用于查找姓名和出生日期
B: 匹配最左边的前缀

例如: 仅查找姓氏,即仅使用索引的第一列
C: 匹配列前缀
您还可以仅匹配列值的开头,例如: 匹配姓氏以J开头的人,这也是索引的第一列,并且是第一列的一部分
D: 匹配范围值
如果您正在寻找姓氏在艾伦和巴里摩尔之间的人,则此处仅使用索引的第一列
E: 完全匹配一列,而范围匹配另一列
如果要查找所有姓氏,并且名字字母以K开头,即第一列last_name完全匹配,第二列first_name匹配范围
F: 仅访问索引的查询
btree通常可以支持仅访问索引的查询,即查询只需要访问索引而无需访问数据行,也就是说,这是覆盖索引的概念. 直接从索引中获取要访问的数据.
因为索引树中的节点是有序的,所以除了按值搜索外,索引还可以按查询中的操作按顺序使用. 一般来说,如果btree可以某种方式找到值,那么它也可以以这种方式用于排序,因此,如果order by子句满足前面列出的查询类型,则该索引也可以满足相应的排序要求
以下是对btree索引的限制:
A: 如果未根据索引的最左列开始搜索,则无法使用索引(请注意,这并不涉及where条件的顺序,即在where条件下,无论条件顺序,只要where中有更多列(在列索引中,您可以从最左边开始连续使用多列索引)
B: 不能跳过索引中的列,例如: 查询条件是姓氏和出生日期,并且名字列被跳过,因此多列索引只能使用姓氏列
C: 如果查询中的某个列存在范围查询,则查询右侧的所有列均不能使用索引优化查询,例如: 其中last_name = xxx和first_name如“ xxx%”和dob ='xxx'; first_name列可以使用索引,此列之后的dob列不能使用索引.
哈希索引:
基于哈希表的实现,只有与索引的所有列完全匹配的查询才有效. 对于数据的每一行,存储引擎都会为索引列的所有值计算一个哈希码. 哈希码是一个较小的值,并且具有不同键值的行的计算哈希码是不同的. 哈希索引将所有哈希码存储在索引中,同时将指针保存到哈希表中的每个数据行.
在mysql中,只有内存引擎显式支持哈希索引. 这也是内存引擎表的默认索引类型. 内存还支持btree. 值得一提的是,内存引擎支持非唯一哈希索引. 在世界中,它是不同的. 如果多列的哈希值相同,则索引将在链接列表的同一哈希条目中存储多个记录指针.
示例:
mysql> createtabletesthash(fnamevarchar(50)notnull,lnamevarchar(50)notnull,keyusinghash(fname))引擎=内存;
QueryOK,0行(0.01秒)
mysql> insertintotesthash值('Arjen','Lentz'),('Baron','Schwartz'),('Peter','Zaitsev'),('Vadim','Tkachenko');
QueryOK,4行(0.00秒)
记录: 4重复: 0警告: 0
mysql>选择* fromtesthash;
+ ------- + ----------- +
| fname | lname |
+ ------- + ----------- +
| Arjen |伦茨|
|男爵Schwartz |
|彼得|扎伊采夫|
|瓦迪姆|特卡琴科|
+ ------- + ----------- +
4行插入(0.00sec)

假设索引使用虚拟哈希函数f(),它将返回以下值:
f('Arjen')= 2323
f('男爵')= 7437
f('彼得')= 8784
f('Vadim')= 2458
哈希索引的数据结构如下:
广告位: 值:
2323指向第1行的指针
指向第4行的2458指针
7437指向第2行的指针
8784指向第3行的指针
每个插槽的编号是连续的,但是数据行不是连续的. 让我们看一下查询:
从testhash中选择lname,其中fname ='Peter';
mysql首先计算Peter的哈希值,并使用该值查找相应的记录指针,因为f('Peter')= 8784,所以mysql在索引中查找8784,您可以找到指向第三行的指针,最后一步是比较第三行的值是否为Peter,以确保它是要找到的行. 由于索引本身只需要存储相应的哈希值,因此索引的结构非常紧凑,这也使哈希索引的搜索速度非常快. 但是,哈希索引也有局限性,如下所示:
A: 哈希索引仅包含哈希值和行指针,并且不存储字段值,因此您不能使用索引中的值来避免读取行(即您不能使用哈希索引来执行覆盖索引扫描),但是,访问内存中行的速度非常快(因为内存引擎数据存储在内存中),因此在大多数情况下,这对性能没有明显影响.
B: 哈希索引数据未按索引列值的顺序存储,因此无法用于排序
C: 哈希索引也不支持部分索引列匹配搜索,因为哈希索引始终使用索引的所有内容来计算哈希值. 例如,在数据列(a,b)上建立一个哈希索引. 如果仅查询数据列a,则无法使用索引.
D: 哈希索引仅支持等效的比较查询,例如: =,(),<=>(请注意<>和<=>是不同的操作),不支持任何范围查询(必须给定具体说明条件值用于计算哈希值的位置,因此不支持范围查询.
E: 除非存在许多哈希冲突,否则访问哈希索引的数据非常快,当存在哈希冲突时,存储引擎必须遍历链接列表中的所有行指针并逐行比较它们,直到在该行中找到所有匹配的条件.
F: 如果存在许多哈希冲突,则某些索引维护操作的成本也非常高. 例如: 如果您在选择性低的列(即具有许多重复值的列)上创建哈希索引,则当从表中删除行时,存储引擎需要遍历链接列表中的每一行对应于哈希值,查找并删除对应的引用,冲突越多,代价也越大.
从以上描述可以看出,哈希索引仅适用于特定的特定场景,一旦适合哈希索引,其带来的性能提升就非常明显. 除了内存引擎之外,NDB引擎还支持唯一的哈希索引. NDB存储引擎的作用非常特殊,这里不再讨论.
innodb引擎具有一个称为自适应哈希索引的特殊功能. 当innodb注意到某些索引值被非常频繁地使用时,它将基于内存中的btree索引创建一个哈希索引. 让btree索引还具有哈希索引的一些优点,例如: 快速哈希搜索,这是一种全自动的内部行为,用户无法控制或配置,但是如果需要,可以选择关闭此功能(innodb_adaptive_hash_index = OFF,默认为ON.
MySQL中的自适应哈希索引
自适应哈希索引是使用前面讨论的哈希表实现的. 区别在于,此操作仅由本身创建和使用基于hash表的索引结构设计与实现,而DBA本身无法干预. 自适应哈希索引映射到哈希表,因此字典类型的查找非常快,例如SELECT * FROM TABLE WHERE index_col ='xxx',但是它对于范围查找是无能为力的. 通过SHOW ENGINE INNODB STATUS,您可以看到自适应哈希索引的当前用法
-------------------------------------
插入缓冲区和自适应哈希索引
-------------------------------------
ibuf: 大小1,空闲列表len 0,段大小2,94个合并
合并操作:
插入280,删除标记0,删除0
废弃的操作:
插入0,删除标记0,删除0
哈希表大小为4425293,节点堆具有1337个缓冲区

174.24哈希搜索/秒,169.49非哈希搜索/秒
您现在可以看到自适应哈希索引的使用信息. 包括自适应哈希索引的大小和用法,以及每秒使用自适应哈希索引进行搜索的情况. 应该注意的是,哈希索引只能用于搜索等价查询,例如
SELECT * FROM table WHERE index_col='xxx'
对于其他搜索类型,例如范围搜索,不能使用哈希索引. 因此,没有哈希搜索,您可以通过哈希搜索大致了解使用哈希索引的效率: 非哈希搜索
由于自适应哈希索引由InnoDB存储引擎本身控制,因此此处的信息仅供参考. 但是,可以通过参数innodb_adaptive_hash_index禁用或启用此功能,该参数默认情况下启用
Hash索引结构的特殊性,其检索效率非常高,可以一次定位索引检索,这与B-Tree索引不同,后者需要从根节点到分支节点的多个IO访问,最后是页面节点,因此Hash索引的查询效率远远高于B-Tree索引.
也许很再次怀疑. 由于Hash索引的效率比B-Tree的效率高得多,为什么不使用Hash索引代替B-Tree索引呢?一切都有两个方面. 哈希索引是相同的. 尽管Hash索引非常高效,但Hash索引本身也由于其特殊性而带来了很多局限和缺点. 主要内容如下.
(1)哈希索引只能满足“ =”,“ IN”和“ <=>”查询,而不能满足范围查询.
因为哈希值比较哈希操作后的哈希值,所以它只能用于等效过滤,不能用于基于范围的过滤,因为使用相应哈希算法处理后的哈希值的大小关系不是确保与哈希操作之前完全相同.
(2)哈希索引不能用于避免数据排序操作.
由于Hash索引存储Hash计算后的Hash值,并且Hash值的大小关系不必与Hash操作之前的键值相同,因此无法使用索引数据来避免任何排序操作;
(3)哈希索引无法使用某些索引键进行查询.
对于组合索引,在计算哈希索引的哈希值时,将组合索引键进行组合,然后一起计算哈希值,而不是分别计算哈希值,因此在通过前一个索引键或组合索引的键,不能使用哈希索引.
(4)哈希索引无法随时避免进行表扫描.
我们已经知道,哈希索引是在索引键通过哈希操作之后,将哈希操作结果的哈希值和相应的行指针信息存储在哈希表中. 不能直接从哈希索引中查询满足某个哈希键值的数据的记录数,或者必须访问表中的实际数据进行相应的比较并获得相应的结果.
(5)遇到大量哈希值后,哈希索引性能不一定高于B树索引.
对于选择性低的索引键,如果创建哈希索引,则在相同的哈希值中将存储许多记录指针信息. 这样,查找特定记录非常麻烦,并且将浪费对表数据的多次访问,从而导致整体性能不佳
2. B树索引
B树索引是MySQL中最常用的索引类型. 除存档存储引擎外,所有存储引擎均支持B树索引. 实际上,不仅在MySQL中,在许多其他管理系统中,B-Tree索引也是最重要的索引类型. 这主要是因为B-Tree索引的存储结构包含在的数据检索中. 很好的表现.
通常,MySQL中B-Tree索引的物理文件主要存储在Balance Tree的结构中,也就是说,所有实际需要的数据都存储在Tree的Leaf Node中,并且存储到任何Leaf节点最短路径的长度完全相同,因此我们都将其称为B树索引. 当然,可能有各种(或MySQL的各种存储引擎)在存储B树索引时会存储它. 结构略有修改. 例如,Innodb存储引擎的B-Tree索引实际使用的存储结构实际上是B + Tree,也就是说,已经基于B-Tree数据结构进行了少量修改. 在每个
叶子节点不仅存储索引关键字的相关信息,还存储指向与该叶子节点相邻的下一个叶子节点的指针信息. 这主要是为了加快检索多个相邻叶节点的效率.
在Innodb存储引擎中,有两种不同形式的索引,一种是集群形式的主键索引(Primary Key),另一种与其他存储引擎(例如MyISAM)基本相同. 存储引擎)普通B树索引,此索引在Innodb存储引擎中称为“二级索引”. 下面我们使用图标来存储这两个索引
进行比较的表格.
在图中,左侧是存储为簇的形式的主键,右侧是普通的B树索引. 两个根节点和分支节点仍然相同. 叶子节点是不同的. 在Prim中,叶节点存储表的实际数据,不仅包括主键字段的数据,而且还根据主键值的顺序包括其他字段的数据. 次要索引与其他普通B树索引没有太大区别. 叶子节点不仅存储索引键的相关信息,还存储Innodb的主键值.
因此,在Innodb中,通过主键访问数据非常有效,如果通过二级索引访问数据,则Innodb首先通过二级索引的相关信息通过相关的索引键检索Leaf Node. ,您需要通过存储在Leaf Node中的主键值然后通过主键索引获取对应的数据行. MyISAM存储引擎的主键索引和非主键索引有很大的不同,但是主键索引的索引键是唯一且非空的键. 此外,MyISAM存储引擎索引和Innodb的Secondary Index存储结构基本相同. 主要区别在于MyISAM存储引擎将索引关键字信息存储在叶节点上,然后将其直接存储到相应的MyISAM数据文件中. 数据行信息(例如行号),但不存储主键的键值信息
关于我
............................................... ................................................................ ... ..............................................
●作者: 小麦草,部分内容来自网络讨论,如果侵权请联系小麦苗删除
●本文已在itpub(),博客园()和个人微信公众号()上进行了更新
●本文的itpub地址:
●该博客园的地址:
●本文的pdf版本,小麦苗云盘的和地址:
●书面面试问答:
●DBA Collection今天的标题地址:
............................................... ................................................................ ... ..............................................
●QQ组号: 230161599(完整),618766405
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-189495-1.html
-

-
周瑜公瑾
麦地路
-
-
王长帅
哈哈哈
 1可以看出,Android系统框架由5部分组成. 从下到上是Linux K
1可以看出,Android系统框架由5部分组成. 从下到上是Linux K 更改Android手机的文件系统
更改Android手机的文件系统 ipa au accountant_accountant duty_accountants
ipa au accountant_accountant duty_accountants win10 系统还原 这 9 款优秀的 Windows 国产应用,让你的 PC 更
win10 系统还原 这 9 款优秀的 Windows 国产应用,让你的 PC 更
······总之