分布式一致哈希算法
电脑杂谈 发布时间:2020-04-23 04:02:43 来源:网络整理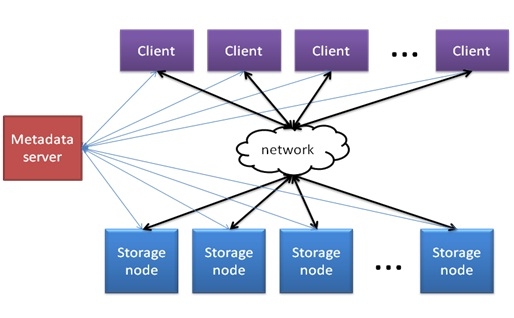
alan.wu@aliyun.com
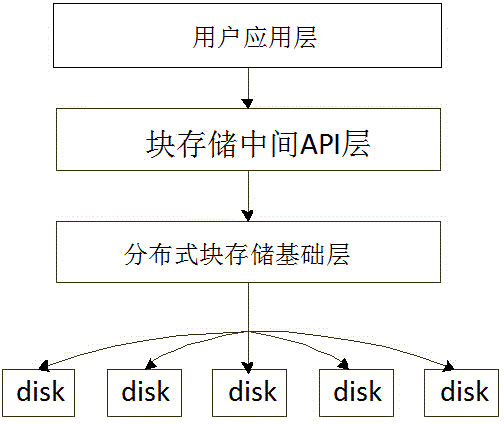
分布式存储中的一个重要问题是如何在多个存储节点之间分配数据. 了解文件系统(例如GFS)的学生知道,元数据服务器(MS)可用于确定存储节点上数据块的分布和映射. 元数据服务器方法可以很好地用于分离数据和元数据. 当访问文件系统命令空间时,可以直接从元数据服务器获取文件的映射信息. 下图显示了基于MS的分布式存储体系结构:

基于元数据服务器的方法是分布式存储的经典体系结构. 尽管看起来很完美,但仍然存在两个主要问题:
1,可伸缩性受到元数据服务器功能的限制. 所有元数据信息都集中在元数据服务器上,因此,当客户端想要获取元数据时,它需要访问服务器. 因此,总的加载容量(客户端数量)受元数据服务器的容量限制. 元数据服务器是整个分布式系统的潜在瓶颈. 尤其是当客户端访问较小的文件时,会生成大量的元数据信息,而元数据服务器成为系统性能的瓶颈.
2. 元数据服务器是分布式系统中的单点故障. 一旦元数据服务器发生故障,整个分布式存储系统将无法正常工作. 因此,元数据服务器的可靠性尤为重要.
总而言之,基于元数据服务器的分布式存储架构的最大问题是可伸缩性和可靠性. 这些问题的核心在于元数据服务器. 为此,还有许多系统优化方法. 例如,对于元数据服务器影响系统可伸缩性的问题,可以使用分布式元数据服务器来缓解该问题. 同步和锁定互斥的问题. 对于元数据服务器的单点故障,可以使用HA来增强系统的可靠性. 许多制造商对Hadoop分布式文件系统中的元数据服务器HA进行了许多尝试.
但是,无论如何优化,使用元数据服务器方法的分布式存储都无法实现线性可伸缩性. 基本上,扩展能力呈现对数LOG曲线. 为了实现线性可伸缩性,业界开始考虑如何删除元数据服务器分布式存储算法,即分散化. 开发的算法包括HASH算法,一致HASH算法,弹性HASH算法和CRUSH算法. 在这里,我们重点介绍一致的HASH算法.
当涉及到一致的HASH时,您首先需要考虑HASH算法. 应用于分布式存储的HASH算法非常简单,可以描述如下:

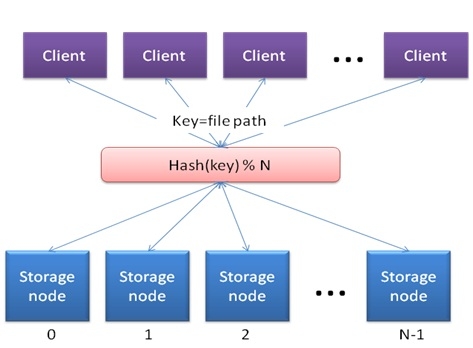
当客户端需要将文件写入Storage时,文件路径可以用作计算HASH值的Key值. 该HASH算法需要具有良好的分布特性. 获取HASH值后,其余操作以存储节点数N执行,结果在0到N-1之间. 结果是要访问的存储节点的编号. 通过这种方法,存储节点中文件的布局不需要元数据服务器的干预. 文件和存储节点之间的映射关系由HASH函数确定,并且是可计算的.
HASH算法看起来很完美,但是问题在于,如果动态添加节点,则该数据映射关系将被破坏,因为HASH算法中的N已更改. 为了建立新的映射关系,有必要引入大量的数据迁移操作,这在分布式存储中是不允许发生的. 为了解决这个问题,引入了一致的HASH算法.
一致性HASH的核心思想是将HASH结果字段放入一个空格,并为所有存储节点分配标签值. 这些标签值属于此HASH值空间. 通常,这种关系可以描述为哈希环,该空间构成此HASH环,并且所有存储节点都是该环上的一个点. 可以描述如下:
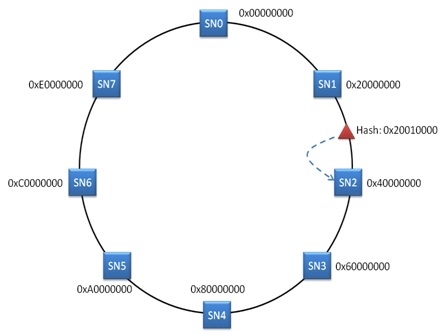
当客户端需要将文件写入存储时分布式存储算法,它也可以使用文件路径作为HASH函数的参数,然后获取HASH值. 所获得的HASH值一定会属于HASH值空间,也就是说,在HASH环上肯定可以找到一个对应点. 例如,此点位于SN1和SN2之间. 根据协议,可以选择顺时针方向最接近HASH值的节点作为数据存储点. 也就是说,新写入的文件可以存储在SN2中.
一致的HASH算法的最大优点是避免在添加存储节点后进行数据迁移. 例如,在前面的示例中,如果在SN1和SN2之间添加了SN8,则最初存储在SN2中的部分数据需要迁移到SN8,但是其余节点不需要执行任何数据迁移操作.
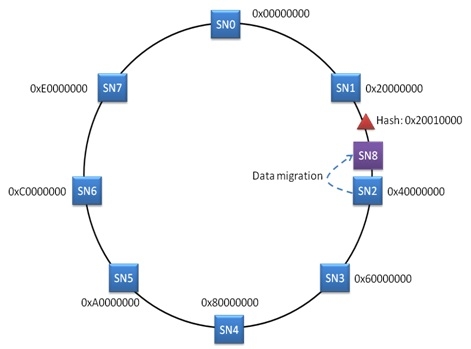
显然,此方法大大减少了数据迁移量,并可以很好地避免由元数据服务器引起的问题. 因此,一致的HASH算法被广泛用于CDN系统,SWIFT对象存储系统和Amazon的发电机存储系统中.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-185509-1.html
-

-
何立祥
歼-16
-
刘红梅
广东没蛆
-
 只需要在win7 Ultimate中设置系统还原点
只需要在win7 Ultimate中设置系统还原点 并行文件系统的特点 实现并行运算的方法汇总
并行文件系统的特点 实现并行运算的方法汇总 C# winform程序用 richtextbox 控件直接
C# winform程序用 richtextbox 控件直接 如何完全卸载McAfee
如何完全卸载McAfee
不要侮辱印度人