编码器使用RSC递归系统卷积码. RSC码由前馈多项式和反馈多项式确定.
电脑杂谈 发布时间:2020-04-22 18:15:40 来源:网络整理
编码器使用RSC递归系统卷积码. RSC码由前馈多项式和反馈多项式确定. 反馈变量检查输出是编码器输入位. 该主题的编码框图如图22所示. 交织器的使用是实现Turbo码的近似随机编码的关键. 交织器交织器是一个单输入单输出信号处理器. 输入序列通过交织器后,输出序列的序列将改变. 长度为N的交织器可以由N个整数π表示. 交织过程可以理解为交织器在时间s的输出等于在时间π的输入信号. 当前常用的Turbo码交织器是分组交织器伪随机S交织器和分组螺旋交织器. 表21示出了常规交织器组交织器的结构. 从该表可以看出,在交织之前和之后,该交织器之后的替换信息序列中的第一位和最后位的位置保持不变. 当分量编码器未归零时,如果原始数据帧的最后几位仍在交织后仍位于帧数据的末尾,则由于分量在解码数据帧的最后几位时的置信度较低,整个Turbo代码的性能是有限的,这种现象称为尾部效应尾部效应. 为避免此问题,在交织器的设计中,应将原始数据帧的最后几位替换为编码器2的输入序列的无尾位置. 当分量编码器返回零时递归系统卷积码,没有拖尾效应. ΣΣΤΤDkAkXkYkCk1行写列读取分组交织器分组螺旋交织器也是一种常规交织器,其交织过程是在mn矩阵中按行顺序写入原始序列,然后从矩阵的左上角开始读取,则将下一行向右移一位,直到读取数据为止.

也可以从交织矩阵的左下角到右上角读取相同的数据. 也就是说,每当读取前一行数据时,它就会通过一个成组的螺旋交错器向右移动. 这种类型的交织器有助于硬件的实现. 交织和解交织工作可以相同. 一个模块完成. 与分组交织器相比,由于交织后相邻符号之间的距离更大,因此在解相关方面优于分组交织器. 伪随机交织器关于伪随机交织器目前,人们普遍认为伪随机S交织器性能更好,也就是说,比较每个随机生成的替换位置π. 如果距离被拒绝,则必须重新生成. 另外,伪随机S交织器的设计与随机交织器相同. 如果不对Turbo码进行打孔,则低编码率(例如1)适用于深空通信场合,但对于要求更高带宽利用率的卫星通信,个人移动通信等而言,则期望更高的编码效率. 因此,有必要引入一种删余机制来周期性地删除所选择的比特,以减少编码信息0的冗余度并提高编码率. 对于迭代解码的情况,通常仅删除校验位. 对于1 2修剪,可以删除RSC1的所有偶数奇偶校验位. 可以删除RSC2的所有奇校验位. 对于编码率大于12的情况,选择其他删余方案可以获得更好的性能. 穿孔矩阵的作用是提高编码效率. 它的元素来自集合. 矩阵中的每一行对应两个分量编码器,其中“ 0”表示对应位置的校验位被删除,“ 1”表示对应位置的校验位被保留.

根据不同形式的打孔矩阵,可以获得具有不同码率的Turbo码. 在信息论中,交织器在turbo码编码器中扮演随机编码的角色. 伪随机交织器的使用使得交织序列的增加的随机性更适合于随机编码的原理. 因此,伪随机交织器是最好的交织器. 仿真结果表明,当交织长度很长时,伪随机交织器的优点是正确的. 伪随机交织器的映射规则不是特定的而是随机生成的. 对于具有交织长度为N的伪随机交织器,则其交织形式可以具有从N中选择的整数,该整数的机率取自原始集合1并从原始集合1中删除. 完成交织过程. 在本主题中,将噪声混合到编码器的输出信号中以模拟通信信道的方法如图24所示. 在加性高斯白噪声AWGN信道模型之后,S接收到的数据流是两个独立且分布均匀的高斯噪声样本,其均值为0. 方差为δ2. 两个编码器都必须是系统代码. 但是,Forney等. 已经证明,对于经典前馈卷积码,在相同的存储长度和较大的信噪比SNR的情况下,非系统卷积码NSC非系统卷积码具有较大的自由距离和较低的误码率BER. 这一结论导致了这样一个事实,即当前大多数实用的前馈卷积码都是非系统的卷积码.

由于这个原因,C Berrou等人. 在提出一种新型的递归系统卷积码RSC递归系统卷积时递归系统卷积码,于1993年提出了Turbo码. 此代码在高代码速率下比最佳NSC更好. 由于Turbo代码需要使用系统代码,因此,递归系统卷积代码RSC会以截断形式选择. 与非递归系统卷积代码NSC相比,递归系统卷积代码RSC具有更好的权重频谱分布和更好的误差. 当编码率较高且信噪比较低时,编码率的性能及其优势将更加明显. 截断是通过删除冗余校验位来调整编码率. Turbo代码使用两个编码器来生成冗余位,这些冗余位是正常情况下的两倍以上. 在许多情况下这不是必需的. 但是它不能排除两个编码器中的任何一个,因此折衷方案是根据某个规则依次选择两个编码器的校验位. 例如,当使用具有两个码率R 2的系统卷积码时,如果不使用截断系统信息位和两个编码器中的每一个的一个校验位,则将生成R 3的码率. 但是,如果将编码器1的奇偶校验位序列乘以截断矩阵,并且将编码器2的奇偶校验位序列乘以截断矩阵,则会产生依次在编码器12之间取值的效果. 此时,尽管1位信息仍然生成2位校验,但是只有系统信息位和1位备用值校验被发送到通道. 调整比特率以符合R Turbo码解码原理. 获得Turbo码取得出色性能的根本原因之一是使用迭代解码,通过在组件之间交换软信息来提高解码性能.
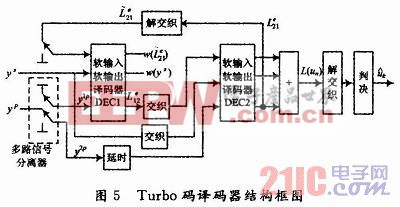
对于诸如Turbo码之类的并行级联代码,如果组件的输出是硬性决定,则不可能实现组件之间的软信息交换,这限制了系统性能的进一步提高. 从信息论的角度来看,任何艰难的决定都会丢失部分信息. 因此,如果组件的内部代码可以提供反映其输出可靠性的软输出,则其他组件的外部代码也可以使用该软代码. 决策解码,从而可以进一步提高系统性能. 因此,人们提出了软输入和软输出解码SISO的概念和方法. Turbo码的分量码SISO解码算法通常可以分为SOVA和MAP两种主要算法. SISO解码模块. 因为turbo码解码需要使用组件之间的软信息交换来提高解码性能,所以组件必须能够接受软信息并输出软信息. 也就是说,它需要使用软输入软输出SISO. SISO的输入信息应具有三个系统信息验证信息和一个先验信息. SISO的输出应为软判决信息. 在这里,我们将介绍SISO的输入和输出信息的定义和生成. 在这里,我们首先给出变量名称和下标用法规则. k代表时间,代表时间在组件编码器的状态,k代表时间,从组件编码器输出的信息位,k代表从编码器在时间k输出的校验位,代表组件编码器输出的代码序列,代表接收到的代码序列.
当接收到发送的比特时,条件似然比显示在公式中. 假设对已编码符号位进行BPSK调制并通过高斯信道或衰落信道进行传输,我们可以得到接收端的接收概率. 发射的比特2的能量是噪声方差a是信道的衰落幅度. 对于无衰落的AWGN信道,软判决解码和硬判决解码. 在以前的通信系统中,当接收到信号时,和解调器是分开分开的. 首先,解调器对信息做出最佳决策,然后将决策结果输出到. 然后,对输入信息做出最佳决策,以纠正调制器产生的错误决策. 这就是硬决策解码的想法. 人们慢慢意识到这会导致解码性能下降. 在现代通信系统中,人们使用编码和调制的组合来组合解调和解码. 即,解调器不对输入信息做出硬性决定,而是输出可能出现在中的符号的概率值. 错误信息被传递到以降低误码率并提高解码性能. 使用解调器输出的符号判决的概率值与编码器输出的信息进行组合,以做出最终判决. 这就是软决策的想法. 研究表明,解调器使用软判决解码时获得的编码增益比使用硬判决解码时获得的编码增益高约2dB. 在对结构进行打孔之后,编码器的输出将交替组成. 它将被发送到调制器,进行调制,然后在接收端发送到信道进行传输和解调. 的匹配滤波器的输出采样值会将采样序列输入,以进行解码以估计原始传输. 图25所示的信息是Turbo码的框图.
结构框图13 SOVA解码算法基于SOVA算法的Turbo代码结构如图26所示. SOVA算法Turbo代码SOVA算法基于Viterbi算法提供软判决输出和使用外部功能的能力. 信息. 对于典型的Turbo代码编码器结构,代码存储级别为v. 代码率为1 1V的递归系统卷积代码. RSC编码器光栅图中的状态总数为20. 每个状态只有两个输入分支和两个输出分支. 传统的SOVA算法包括以下步骤: 在时间k的累积路径度量的计算在每种状态下,路径m的累积路径度量是由编码器在时间k输入的信息位的公式给出的. SOVA1SOVA2解交织交织器解复用交织器解交织Yt 14计算软判决值时第k条路径m的概率. 该公式表示累积路径度量和剩余路径平行路径的概率. 由此,可以获得时刻k的路径判定的对数似然比. 软决策值是公式. 在每个时间k更新软判决值. 软判决值的更新规则是HR SOVA和BR SOVA. min HRSOVA BRSOVA分别是时间k处生存路径的第J位和生存路径的并行路径. BRSOVA具有比HR SOVA更好的性能,但是算法的复杂性会增加很多,因此HR SOVA经常在实践中使用.
通过从最大似然路径上的硬判决序列的条件对数似然比中减去固有信息值来计算外部信息值,以获得外部信息的估计值. 改进了通过公式改进的SOVA解码算法. SOVA算法主要是限制SOVA双向SOVA限制SOVA. 15 SOVA算法的性能低于MAP算法的原因之一是SOVA的输出软判决值太大,或者判决的可信度太高. 限制SOVA通过设置阈值限制软判决值来解决此问题. 解码过程,路径度量和对数似然比的计算与传统SOVA相同. 唯一要校正的是使用公式10来限制软判决值Δ. 10很难选择适当的阈值Δ来限制SOVA. 如果Δ的值太大,则限制过程基本上不起作用. 如果该值太小,则由于对软判决值的过度校正会降低解码性能. 阈值Δ与决策可信度的统计特性有关. 最佳软判决值阈值应根据信道特性(例如信噪比)的变化而变化. 可以根据正向或反向网格图对SOVA算法进行解码. 由于前向和反向SOVA解码方向不同,因此路径选择和每个路径度量的累加值也不同,因此在正向和反向解码生成的软输出值之间存在差异. 双向SOVA算法在传统SOVA解码结构的基础上增加了反向SOVA解码单元,因此每个解码模块可以同时执行正向和反向SOVA解码操作,并通过合成两个方向来提供自己的软判决输出. 为下一轮解码提供了更可靠的外部信息,以达到提高SOVA解码性能的目的.
SOVA算法的性能比MAP算法低的原因之一是SOVA的软输出值太大. 双向SOVA通过引入反向SOVA解码单元来减少SOVA的软值偏差. 目前,双向SOVA的性能是各种SOVA改进算法中最好的. 然而,由于在两个方向上都引入了计算,因此解码复杂度大大增加. 极限SOVA算法使用预设的阈值Δ值在一定程度上限制SOVA的性能. 但是,极限SOVA仅限制了较大的软决策值,并且不处理小于阈值的软决策值. 实际上,SOVA的软判决值的估计偏差存在于Δ的整个实数字段中,因此仅对超过阈值的软判决值进行限制处理的效果受到限制. 这在一定程度上影响了SOVA算法的性能. 提高. 借鉴量化中非均匀量化的思想,提高了量化信噪比,引入了软判决值校正函数H,其特征应类似于A律或群律压缩非均匀量化中的特征曲线. 首先,在整体特性上需要压缩Δ. 其次,当Δ较小时,压缩减小,而当Δ较大时,压缩增大. 校正函数用于校正整个Δ的非负实数字段,以提高SOVA软输出值的精度. 由于引入了校正功能,此方法称为修改后的SOVA. 校正函数H的选择直接影响解码性能. 如果完全遵循非均匀量化中的A律或μ律压缩特性曲线或类似的连续压缩特性函数,则难以确定系数Aμ或解析函数公式. 出于简化算法的考虑
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-185055-1.html
-

-
卫万
芝麻糊里面都是密封包装
 手机号码 查 淘宝刷单怎么做?亲身经历告诉你淘宝刷单真相
手机号码 查 淘宝刷单怎么做?亲身经历告诉你淘宝刷单真相 档案信息化应用系统建设 东阳到太原~物流专线
档案信息化应用系统建设 东阳到太原~物流专线 First-chance exception in main.exe
First-chance exception in main.exe 下载好U盘装系统软件安装包,更加不能错过
下载好U盘装系统软件安装包,更加不能错过
今儿逛书店看到了小米出了本公关营销书