集群分析,聚类算法包括哪些数据类型?
电脑杂谈 发布时间:2020-04-20 12:08:06 来源:网络整理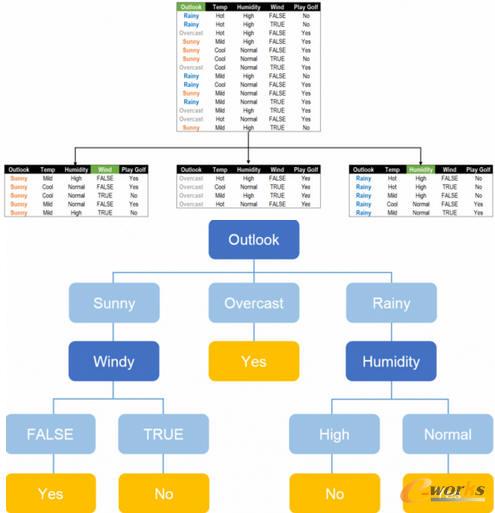
许多基于内存的聚类算法使用以下两个数据结构: (1)数据矩阵(DataMatrix或object-disc结构): p变量用于表示n个对象,例如年龄,身高算法的数据包括哪些,属性变量,例如性别和体重代表目标人物,...
许多基于内存的聚类算法使用以下两个数据结构:
(1)数据矩阵(或对象到磁盘的结构): 使用p个变量表示n个对象. 例如,使用属性变量(例如年龄,身高,性别和体重)来代表目标人. 模块化矩阵,行和列表示不同的实体:
(2)差异矩阵(也称为对象-对象结构): 存储所有n对对象之间的相似性(接近度),也称为单模矩阵,行总和列表示相同的实体. 其中d(ij)是对象i和对象j之间测得的差异或不相似性. d(i,f)是非负值. d(ij)越大,两个对象的差异就越大; d(i,j)越接近0,则两者越相似(相似).

许多聚类算法都基于相异矩阵. 如果数据以数据矩阵的形式表示算法的数据包括哪些,通常有必要先将其转换为相异矩阵.
相异性d(i,j)的具体计算取决于所使用的数据类型. 常用的数据类型包括: 区间刻度变量,二进制变量,标称类型,序数类型和比例刻度度变量,混合类型变量.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-182349-1.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
-

-
吴苗苗
若有信心击沉来舰
![[javascript]定期审核](http://upload.gezila.com/data/20141213/561418436416.png) [javascript]定期审核
[javascript]定期审核 聚丙烯管道的状态分析和前景预测
聚丙烯管道的状态分析和前景预测 “勒索软件”的出现: 车联网仍然安全吗?
“勒索软件”的出现: 车联网仍然安全吗? 绝句吴韬古诗拼音版
绝句吴韬古诗拼音版
否则以两舰对一舰