数据结构链接列表一(链接列表结构)[正在更新]
电脑杂谈 发布时间:2020-04-20 04:16:53 来源:网络整理
blog.csdn.net github.com
像数组一样,链表是线性结构,如图所示:
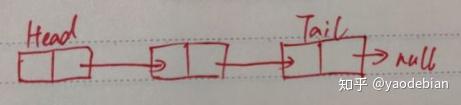
链表结构和数组结构有什么区别?
现在假设存在一种方案,其中系统中当前的剩余内存空间已足够. 现在,如果您需要申请一个100MB的数组或链表,尽管系统中的剩余空间大于100MB,但是没有连续的内存块大于或等于100MB,则该数组将被声明为成功,因为链表不受连续内存的影响,因此可以成功应用.
基于最基本的链接列表结构,链接列表还派生出几种不同的形式:

如果显示了其结构:

以上结构由一个连接的存储块组成,每个存储块称为一个节点,一个节点由两部分组成,一部分用于存储数据,另一部分仅用于存储地址. 下一个节点,即一个Pointer,此指针称为后继指针.
此外,链表具有两个特殊节点,即第一个节点和最后一个节点. 我们习惯性地称它们为头节点和尾节点:
如下所示:

从上图可以看出结构链表,链表的插入和删除非常简单,只要可以完成一个或两个步骤来指向后续指针,则它们的时间复杂度为O(1).
此外,由于链表由一系列分散的节点组成,因此无法执行诸如通过下标对相应节点进行数组访问之类的操作. 要找到每个节点,请从头节点进行迭代,直到找到相应的节点为止. 点,所以时间复杂度为O(n).
结构如图所示:

正如四个单词“循环链表”所说,该结构通过将尾节点的后续指针指向头指针而形成闭环结构. 当要处理的数据具有环形结构的特征时,这是特别合适的. 通过通告列表,例如著名的约瑟夫问题.

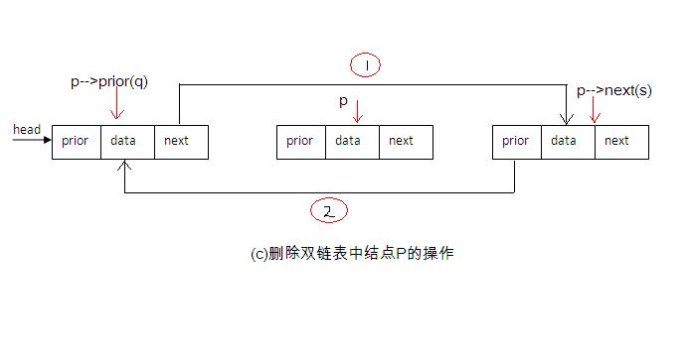
双向链表在单个链表的基础上向每个节点添加一个prev指针(prev),以实现双向访问结构链表,如图所示:

双链表在结构上比单链表具有更多的前任指针,这意味着此结构将占用更多内存,因此,在内存使用率更高的情况下,其性能与单链表相比如何?链表什么?
首先,从插入操作的角度来看:
然后从删除操作的角度来看:
最后,从查询的角度思考:

通常,两者都是遍历查询,时间复杂度为O(n),但是如果对链表的内容进行排序,则双链表将比单链表更有效. 因为我们可以记录每次查询后最后搜索的位置p,然后根据搜索值和p之间的关系来决定是向前搜索还是向后搜索,因此平均而言,仅需要搜索一半的数据.
即双向链表和循环链表的组合,如图所示:
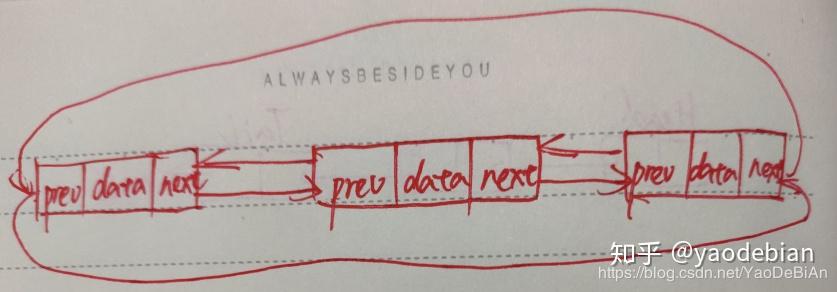
即双向链表和循环链表的组合,如图所示:

以上是两个数据结构通常的时间复杂度. 是否可以根据上述时间复杂度选择要使用的数据结构?
否,例如:
与数组相比,链接列表更适合插入和删除操作频繁且查询时间复杂度较高的方案. 但是,在特定的软件开发中,有必要比较阵列和链表的各种性能,并全面选择使用哪种.
此外,在日常编码中,我们可以采用将空间用于时间或将时间用于空间的想法:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-181972-1.html
-

-
谷仅仅
便宜点有意
 全面理解二进制排序树
全面理解二进制排序树 autoruns怎么用_autoruns汉化_microsoft autoruns
autoruns怎么用_autoruns汉化_microsoft autoruns![如何解决win8.1系统不推送win10系统升级消息的问题[图]](http://www.17qq.com/img_qqtouxiang/32886086.jpeg) 如何解决win8.1系统不推送win10系统升级消息的问题[图]
如何解决win8.1系统不推送win10系统升级消息的问题[图] 病毒代码 正在让西方颤抖的中国七杰
病毒代码 正在让西方颤抖的中国七杰
>我自愿为国家尊严而战