使用图对搜索引擎原理进行简单分析
电脑杂谈 发布时间:2020-04-11 02:17:17 来源:网络整理
摘要: 首先,让我们简要介绍一下搜索引擎的“三个轴”: 数据收集-预处理[索引]-排名. 数据收集是数据收集的阶段. 网页是从广阔的Internet世界中收集到它们自己的中进行存储的. 1.爬网和维护策略需要处理大量...
首先,让我们简要介绍一下搜索引擎的“三轴”: 数据收集->预处理[索引]->排名.

数据收集
在数据收集阶段搜索引擎原理 存储,网页是从广阔的Internet世界收集到自己的中进行存储的.
1. 抓取维护策略
面对大量要处理的数据,需要预先考虑许多问题. 例如,是“实时获取”还是“预先获取”?维护数据时,是“常规爬网”(定期深度爬网以替换原始数据)还是“增量爬网”(以原始数据为基础,将新旧交替)?
2. 链接跟踪
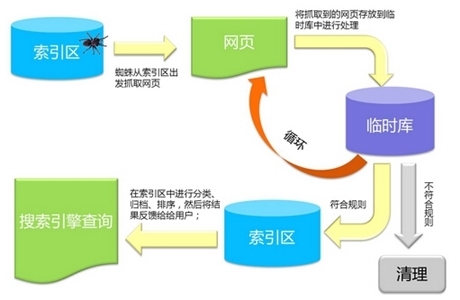
我们都知道蜘蛛会沿着链接爬行和爬行页面. 如何快速为用户捕获相对重要的信息并获得广泛的覆盖范围无疑是搜索引擎需要关注的问题.
首先,如何捕获重要信息.
要知道这一点,主页需要了解人们如何主观判断页面是否重要(首先考虑). 实际上,无非是以下情况:
该网页具有历史累积权重(域名使用时间长,质量高且具有旧资格),许将参考此页面(指向外部链接),许将参考此页面(重印或镜像) ,此页面很方便用户可以快速浏览(浅层次结构),经常出现新内容(更新)等.
在链接跟踪阶段,唯一可用的信息是“该页面便于用户快速浏览(浅层次结构)”,而尚未获得其他信息.
信息的覆盖实际上是蜘蛛在跟踪链接时使用的两种策略: 深度爬网和广度爬网.

当您想到臀部时,您会知道广度爬网可以帮助您获取更多信息,而深度爬网则可以帮助您获取更全面的信息. 搜索引擎蜘蛛通常在爬网数据时使用这两种方法,但是相比之下,广度爬网比深度爬网更多.
3. 地址库
在建立搜索引擎的早期,必须有一个手动输入的库,否则,蜘蛛在跟踪连接时将无法启动. 沿着这些库,蜘蛛可以找到更多链接.
当然,多个搜索引擎将发布页面提交门户,以便网站站长可以提交网站.
但是值得一提的是,搜索引擎更喜欢他们找到的链接.
4. 文件存储
跟踪链接后,需要存储跟踪的信息. 存储的对象,第一个是url搜索引擎原理 存储,第二个是页面内容(文件大小,最后更新时间,http状态代码,页面源代码等).

关于url,由于我上次看到一个带有泛端口作弊的站点,因此这里有一个简短的提及. 网址由传输协议,域名,端口,路径,文件名和其他部分组成.
预处理[索引]
获取数据后,需要对其进行预处理(许喜欢将此步骤称为索引). 主要从文本提取,分词,索引,链接分析等方面.
1. 提取文字
一个易于理解的部分,它提取源代码中的文本. 当然,应注意,这将包括元信息和一些替代文本(例如alt标签).
2. 分词
每次我走到这一步时,我总是想叹息汉字的深刻. 什么!什么!什么!
叹了口气,继续走下去.
分词是中文中的一个独特步骤,即根据句子的含义拆分文本. 通常,分词将基于字典和统计信息.
为了更有效地执行机器单词分割,通常使用“正向匹配”和“反向匹配”两种思想. 值得一提的是,“反向匹配”方法更容易获得更多有价值的信息(请思考为什么).
应该强调的是,为了便于分词后的短语更好地表达文章的核心含义,请取消暂停单词(例如ah,um之类的单词)并去噪(导航,版权,分类等)主题表达的内容以影响内容.

3. 重复数据删除
暂停后,去噪后的其余短语已经可以很好地表达页面的主要含义. 为了使内容不会被搜索引擎重复包含,搜索引擎需要一种算法来执行重复数据删除过程.
例如,著名且常用的MD5算法,请单击百度百科上的链接进行自己的大脑补充.
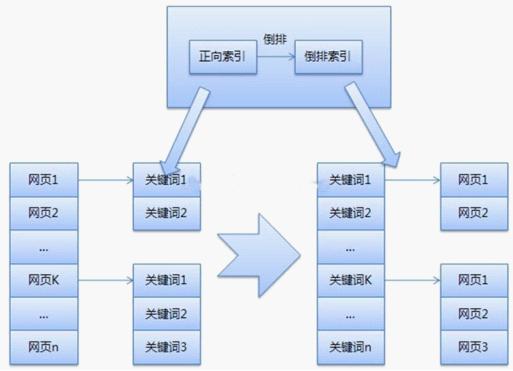
4. 创建索引
重复数据删除完成后,它是人们经常谈论的前向索引和反向索引.

5. 链接算法

排名
创建索引文件后,它与排名不远.
1. 搜索词的处理
搜索引擎还将对搜索词进行单词分割(考虑原因). 话虽如此,我不禁要想一想汉字的深刻性.
为此,我要添加的是一个称为文本粒度的概念. 为了避免误认孩子,还是给百度官方解释一下.
2. 文件匹配和子集选择
根据百度的官方声明,在对用户搜索到的单词进行单词分割之后,可以调出索引. 这里要考虑的一件事是用户经常查看前几页的搜索结果. 因此,对于资源会计,搜索引擎趋向于仅返回部分结果(百度显示76页,Google显示100页),这是召回的索引库的子集.
3. 相关计算
通常,有五个因素会影响这种关系.

关于这部分,这是SEO优化方法和每个人都经常谈论的方法,在此不再赘述.
4. 排名过滤和调整
实际上,在进行了相关计算之后,结果已经大致确定. 只是为了惩罚一些涉嫌作弊的网站,搜索引擎会在本节中对结果进行微调.
例如,百度的11位机制.
5. 显示结果
深呼吸,最后您可以看到显示的结果.
返回的结果将包括标题,描述,快照条目,快照日期,URL等.
这里值得一提的是,不仅描述了搜索引擎可以动态爬网,而且在不久的将来,标题也将动态爬网.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-171269-1.html
-

-
姜雨辰
一楼
-
王景中
~
高喊着防杀伤性武器入侵伊拉克