云计算关键技术的分布式存储
电脑杂谈 发布时间:2020-04-10 10:29:59 来源:网络整理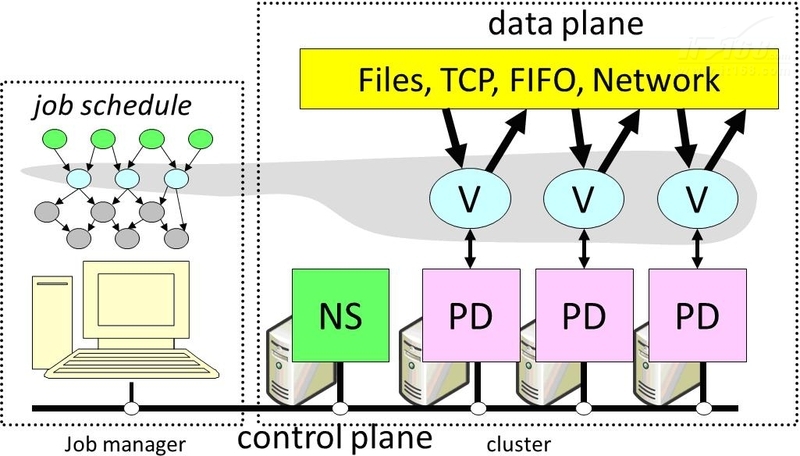
摘要: 分布式存储的目标是使用多台服务器的存储资源来满足单个服务器无法满足的存储要求. 分布式存储要求对存储资源进行抽象表示和统一管理,并能保证数据读写操作的安全性,可靠性,性能和其他要求.

分布式存储的目标是使用多个服务器的存储资源来满足单个服务器无法满足的存储要求. 分布式存储要求对存储资源进行抽象表示和统一管理,并能保证数据读写操作的安全性,可靠性,性能和其他要求.

随着过去几十年Internet技术的发展,越来越多的Internet应用程序需要存储大量数据,例如搜索引擎和Internet视频站点. 这些需求催生了一系列出色的分布式存储技术. 分布式存储技术可以通过多种方式实现. 更典型的实现是分布式文件系统. 分布式文件系统允许用户访问远程服务器的文件系统,例如本地文件系统. 用户可以将其数据存储在多个远程服务器上. 分布式文件系统基本上具有冗余备份机制和容错机制,以确保数据读写的正确性. 云环境的存储服务基于分布式文件系统,并已根据云存储的特性进行了配置和改进. 分布式存储实现的另一种类型是分布式存储软件或服务,例如著名的Ryze存储服务和许多P2P文件存储系统. 下面介绍分布式文件系统和云存储服务.

首先介绍一些典型的分布式文件系统. 素馨花是具有良好可伸缩性的高性能分布式文件系统. 该系统使用两层服务体系结构: 底层是分布式存储服务,可以自动管理可伸缩且高度可用的虚拟磁盘. 在此,分布式存储服务的上层运行素馨花分布式文件系统. JGtFile是基于P2P多播技术的分布式文件系统,支持在Internet等异构环境中进行文件共享. Ceph是一种高性能且可靠的分布式文件系统,它通过最大程度地分离数据和数据管理来实现出色的I / O性能.
Google文件系统(GFS)是Google设计的可扩展的分布式文件系统. 在考虑了分布式文件系统的设计标准之后,Google的工程师发现以下要求不同于传统的分布式文件系统: 首先,PC服务器容易出现故障,从而导致节点故障和故障. 原因很多,包括机器本身,网络,管理员和外部环境. 因此,有必要监视整个系统中的节点,检测错误,并开发相应的容错和故障恢复机制. 其次,在云计算环境中,海量结构化数据通常以GB的顺序保存为非常大的文件,因此,应将基于中小型文件(KB或MB)管理的原始文件系统设计更改为适应访问非常大的文件;第三,实际上,系统中绝大多数文件写操作都是追加操作,也就是说,实际上很少发生在文件末尾写数据,而在文件中间写数据,并且数据写在同一位置. 时间,在大多数情况下,它是按顺序读取的并且不会被修改,因此在设计系统时,将重点放在附加操作上可以大大提高系统性能;第四云计算分布式文件系统,在设计系统时,我们必须考虑开放和标准的操作界面,并在文件系统的下层隐藏诸如负载平衡和冗余复制之类的细节. 方便上层系统使用. 因此,GFS可以很好地支持海量数据处理应用程序. 图5.7显示了GFS的系统架构.

云计算的出现给分布式存储带来了新的要求和挑战. 在云计算环境中,数据存储和操作以服务的形式提供;数据的类型多种多样,包括普通文件,大型二进制文件(例如虚拟机映像文件),类似XML的格式化数据,甚至的关系数据等. 云计算的分布式存储服务设计必须考虑各种数据类型的存储机制,以及数据操作的性能,可靠性,安全性和简便性.
目前云计算分布式文件系统,在云计算环境中的分布式存储领域中已有一些研究成果和应用. BigTable是Google设计的用于存储海量结构化数据的分布式存储系统. Google使用此系统将网页存储为分布式,多维和有序图. Dynamo是基于Amazon设计的键/值对的分布式存储系统. 设计开始时的主要考虑因素之一是,亚马逊的大型数据中心可能会在组件出现故障的任何时候发生,因此Dynamo可以提供很高的可用性. 亚马逊的简单存储服务(S3)是一种云计算存储服务,支持存储多媒体二进制文件. Amazon的Simple DB是基于S3和AmazonEC2构建的云计算服务,用于存储结构化数据.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-170494-1.html
 计算机掉入水中时蓝屏有什么问题
计算机掉入水中时蓝屏有什么问题 图像识别是怎么实现的 无人货架成为泡沫?那么无人货柜的前景如何
图像识别是怎么实现的 无人货架成为泡沫?那么无人货柜的前景如何 简单教程:桌面上的win8图标教程
简单教程:桌面上的win8图标教程 QQ音乐下载
QQ音乐下载
难版支持一下