Hadoop内部技术: MapReduce体系结构设计和实现原理的深入分析
电脑杂谈 发布时间:2020-04-08 18:14:21 来源:网络整理
第1章阅读源代码之前的准备工作
通常,在研究系统的技术细节之前深入解析mapreduce架构设计i与实现原理,必须进行一些基本的准备工作深入解析mapreduce架构设计i与实现原理,例如准备源代码读取环境,设置操作环境以及尝试使用系统. 对于Hadoop,因为它是一个分布式系统,并且由多个守护程序组成,所以它具有一定的复杂性. 如果您想深入了解其设计原理,则仅执行上述准备工作还不够,还需要学习一些如何使用调试工具来调试和跟踪Hadoop源代码的方法. 使用时学习,以便您事半功倍.
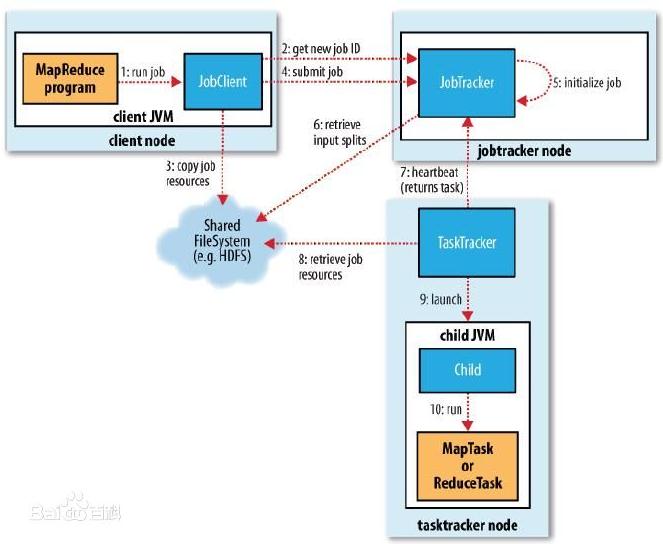
本章的目的是帮助读者构建“高效”的Hadoop源代码学习环境,包括Hadoop源代码阅读环境,Hadoop使用环境以及Hadoop源代码编译和调试环境. 主要涉及以下内容:
❑在Linux和Windows环境下构建Hadoop源代码阅读环境的方法;

❑Hadoop的基本使用,主要包括Hadoop Shell和Eclipse插件工具的使用;
❑Hadoop源代码的编译和调试方法,包括调试方法,包括使用Eclipse进行远程调试和打印调试日志.

考虑到大多数用户在单台机器上学习Hadoop源代码,本章中的内容基于单台机器环境. 本章中的大多数内容都是相对基础的,已经精通此部分的读者可以直接跳过本章.
1.1准备源代码学习环境

对于大多数公司而言,Linux操作系统已部署在实验和生产环境中的服务器群集中. 考虑到Linux在服务器市场上的主导地位,Hadoop从一开始就是基于Linux操作系统开发的,因此它对Linux具有完美的支持. 尽管Hadoop使用具有跨平台功能的Java作为主要的编程语言,但是由于其某些功能使用了Linux操作系统相关技术,因此对其他平台的支持不够友好,并且尚未进行严格的测试. 换句话说,其他操作系统(例如Windows)只能用作开发环境,而不能用作生产环境. 对于学习源代码而言,操作系统的选择不是很重要,读者可以根据自己的喜好来决定. 本节以64位Linux和32位Windows为例,介绍如何在一台机器上准备Hadoop源代码学习环境.
......
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-168489-1.html
-

-
晋明帝
去追求就是最好的
 PHP cURL在活动服务器上未使用代理
PHP cURL在活动服务器上未使用代理 eclipse编译Java文件
eclipse编译Java文件 任天堂 磁碟机_任天堂fc改av_任天堂磁碟机赛车
任天堂 磁碟机_任天堂fc改av_任天堂磁碟机赛车 乐至宝沙发,乐至宝沙发价格
乐至宝沙发,乐至宝沙发价格
本来就应该受到法律的制裁