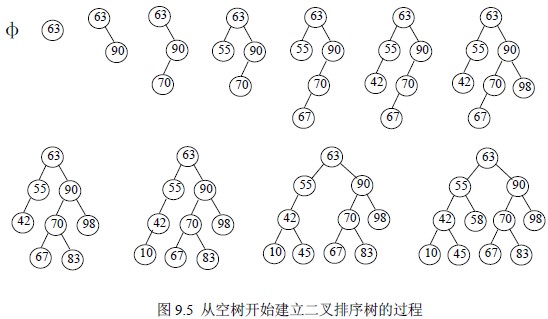
二叉树是解决链表搜索的线性特征,而二叉树则采用了划分成整数的方法
电脑杂谈 发布时间:2020-04-04 22:01:13 来源:网络整理
2014-04-20 17: 40 |发布者: watchmen |查看: 3832 |

收藏夹
摘要: 该树用于解决链表搜索的线性特征. 树采用分割的方法. 例如,二叉树采用分为两部分的方法. 搜索和插入期间的时间复杂度将逐渐移至Log2 N附近. 与链表相比二叉排序树 时间复杂度,该结构具有更好的搜索效率. 当然,这是基于一定的内存空间...
(1)了解树木的基本原理和应用场景以及树木的优越性.

(2)掌握二叉树的特性,应用场景和编程示例.
引入了问题: 读取包含大量单词的文件,计算哪些单词以及每个单词的出现次数. 此外,如有必要,输出TOP100.
解决方案: 每次出现一个单词时,都要找出该单词是否存在于现有单词组中. 如果有,则将数字加1. 如果不是,请添加此单词并将其值设置为1. 主要操作:

(1)读取磁盘文件并得到单词. fopen / fread /简单分词.
(2)如何判断现有单词组中是否存在该单词以及在何处找到它.
如果现有单词组未排序(ASCII码值). 您需要遍历.

如果现有单词已经排序(ASCII码值). 二分法的平均搜索效率为O(logn),但需要对数组进行排序. 如果没有排序,则必须使用O(nlogn)预处理对其进行排序. 而且,它很难插入,并且经常需要移动整个阵列,因此在动态情况下速度较慢.
(3)添加单词是否方便.
03.05二进制排序树搜索二叉排序树 时间复杂度,删除操作
有关更多信息,请参阅Pdf文档.
支持的文档和代码.
binary_tree.c
IT500高级工程师的算法分析_03_数据逻辑组织_tree_binary tree_watchmen watchmen.cn.pdf
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-164091-1.html
-

-
田中大文
因为去不了
-
晋穆帝司马聃
 电脑蓝屏开不了机怎么办?详细解决步骤介绍
电脑蓝屏开不了机怎么办?详细解决步骤介绍
 Win7一键重装|计算机系统一键重装win7教程
Win7一键重装|计算机系统一键重装win7教程 固定资产折旧的会计处理
固定资产折旧的会计处理 联想旭日410m驱动_联想旭日410m拆机教程_联想旭日1000驱动声卡
联想旭日410m驱动_联想旭日410m拆机教程_联想旭日1000驱动声卡
如果中国人取越南