学习字典只是告别JSP的一个好主意
电脑杂谈 发布时间:2020-03-28 18:14:33 来源:网络整理
起初,我只是想让页面映射出我的字典值,但是发现了一个更大的问题.
如果您自己进行演示,则需要将词典数据映射到首页. 你会怎么做?总体思路应该是准备字典jsp开发之路,准备数据,然后映射这两部分.
在此过程中,我还在想,如何保存字典数据?有一个相对简单的方法,该方法也很聪明,使用一个实用程序类,使用枚举方法保存字典值. 配置文件也可以在此类中加载.
import java.io.IOException;
import java.util.Properties;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Keys {
private final static Logger logger = LoggerFactory.getLogger(BaseDictUtil.class);
public static String project_name;
// 加载配置文件
static {
logger.info("======= Start load Properties =====");
Properties webapp_prop = new Properties();
try {
webapp_prop.load(BaseDictUtil.class.getResource("/webapp.properties").openStream());
project_name = webapp_prop.getProperty("webapp_project_name");
logger.info("======= End load Properties =====");
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 配置性别字典
public enum Gender {
Gender_1("男生", 1), Gender_2("女生", 2);
public static String getName(int index) {
for (Gender c : Gender.values()) {
if (c.getIndex() == index) {
return c.name;
}
}
return null;
}
private Gender(String name, int index) {
this.name = name;
this.index = index;
}
private String name;
private int index;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
}
}
在词典很少的情况下,使用上述方法方便快捷,但是存在问题. 如果您需要添加新词典并更改代码,这将非常麻烦.
让我们看看另一种更常用的方法. 此方法需要使用. 在项目开始时,该字典将保存在表中并加载到Map中.

地图中的值有一定的规则. 由您决定地图的关键. 通常,首先将字典分组,然后获得对应的关系. 例如,城市组代码是city,城市下的001代表北京. 地图的结构可以是城市作为主键,值是子地图. 子地图中存储着城市编号和特定城市的地图.
我在互联网上看到另一个小组,并把它带给您分享. dict记录可以分为哪个表,哪个值以及它代表什么值. 对应和Map,我们可以这样设计.
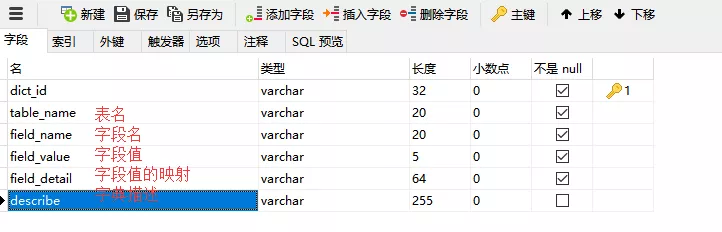
映射中的键是tableName_fieldName_fieldValue,值是field_detail. 同样,在这里我们可以将配置文件加载到Map中. 在这里,我们可以选择加载一些系统级配置.
public class BaseDictUtil {
@Autowired
private static BaseDictDao dicDao;
private static HashMap<String, String> hashMap = new HashMap<>();
private final static Logger logger = LoggerFactory.getLogger(BaseDictUtil.class);
// 静态方法在程序启动的时候只加载一次,这样为了让查询方法只去查询一次
static {
// 获取应用上下文对象
@SuppressWarnings("resource")
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:applicationContext-dao.xml");
// 获取dicDao实例
dicDao = ctx.getBean(BaseDictDao.class);
queryDic();
}
// 加载配置文件
static {
logger.info("======= Start load Properties =====");
Properties webapp_prop = new Properties();
Properties base_prop = new Properties();
try {
webapp_prop.load(BaseDictUtil.class.getResource("/webapp.properties").openStream());
hashMap.put("webapp_project_name", webapp_prop.getProperty("webapp_project_name"));
base_prop.load(BaseDictUtil.class.getResource("/base_dict.properties").openStream());
hashMap.put("base_dict.dict_type_code.001", base_prop.getProperty("base_dict.dict_type_code.001"));
logger.info("======= End load Properties =====");
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 从中取值放入到HashMap中
public static void queryDic() {
List<BaseDict> dics = dicDao.selectAll();
for (int i = 0; i < dics.size(); i++) {
BaseDict dic = dics.get(i);
String tableName = dic.getTable_name();
String fieldName = dic.getField_name();
String fieldValue = dic.getField_value();
String key = tableName + "_" + fieldName + "_" + fieldValue;
String value = dic.getField_detail();
logger.info(key + " ---> " + value);
hashMap.put(key, value);
}
}
public static String getFieldDetail(String tableName, String fieldName, String fieldValue) {
StringBuilder sb = new StringBuilder();
StringBuilder keySb = sb.append(tableName).append("_").append(fieldName).append("_").append(fieldValue);
String key = keySb.toString();
String value = hashMap.get(key);
return value;
}
public static String getProperties(String key) {
return hashMap.get(key);
}
public static void main(String[] args) {
String detail = BaseDictUtil.getFieldDetail("customer", "cust_level", "2");
System.out.println(detail);
System.out.println(getProperties("webapp_project_name"));
}
}
到目前为止,我们已经处理了字典. 在实体中获取数据非常容易,但是现在我们有一个问题,如何将两者结合在一起,我们应该先在后台处理数据,然后将其传输到前台还是分别传递到前台,那么映射是由前端处理的?

这个问题对我来说真的很难. 有一种非常愚蠢的方式. 当我们获得实体数据时,我们将其一一映射,最后将其返回到前台以处理结果. 作为后端工程师,这不是我的想法. 但是,我没有处理前台的技能. 唉
这是函数的结尾. 我主要想谈谈前端和后端的分离. 前端和后端没有分开,后端工程师既是父亲又是母亲. 同时使用数据和页面实在令人作呕.
但是黎明来了,现在我提倡前后分开. 作为一名后端工程师,我真的很高兴. 随之而来的是,JSP页面被放弃,并切换为HTML + JS或Front Frame + JS.
为什么放弃JSP?
1. 数据和静态资源放在一起. 对CSSjsp开发之路,JS和图像的各种请求将增加服务器的压力.
2,JSP必须在支持Java的Web容器(tomcat之类)中运行,不能使用nginx.

3. 第一次请求JSP时,必须将JSP转换为Web容器中的servlet,因此第一次访问很慢.
4. JSP页面中的内容非常复杂,包括html,各种标签和JS. 它使前端头疼,使后端头疼.
5. 如果JSP中有很多内容,则页面响应将由于加载同步而变慢.
以前的开发步骤是这样的
1. 客户端发送请求.
2. 服务器上的servlet或控制器接收请求(路由规则由后端制定,整个项目开发的重要部分位于后端).

3. 调用服务和dao代码以完成业务逻辑.
4. 返回JSP.
5,JSP显示了一些动态代码.
这是在前端和后端分离之后发生的事情.
1. 浏览器发送请求.
2. 直接进入html页面(路由规则由前端设置,整个项目开发的重心向前移动).
3. html页面负责调用服务器接口以生成数据(通过ajax等).
4. 填写html以显示动态效果.
前端和后端大多使用JSON进行数据交互,并通过ajax异步加载数据,因此无论数据量多么复杂,都可以轻松访问项目. 数据被返回.
很高兴地说,这么多前端和后端是分开的. 但是,我自己编写的演示没有前台来处理. 不要说,我默默地移动了砖块……
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-155643-1.html
是否落后你也并不清楚