第6章]二进制排序树(C语言实现)
电脑杂谈 发布时间:2020-03-26 08:06:25 来源:网络整理
对于普通的顺序存储,插入和删除操作简单有效. 并且由于混乱,此类表的查找效率非常低.
对于有序线性表(顺序存储),可以使用诸如减半,插值,斐波那契等搜索算法来实现查找,并且效率很高;并且由于顺序性,插入和删除必须花费大量时间.
那么,如何提高插入和删除效率,并更有效地实现搜索算法?
看一个例子:
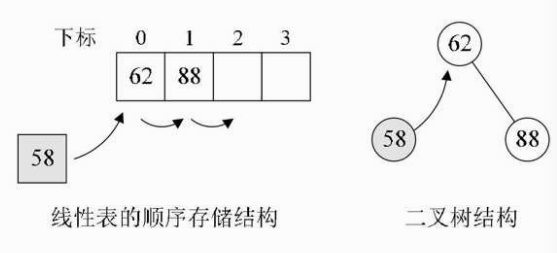
现在,我们的目标是与插入和查找一样高效. 假设我们的数据集仅以一个数字{62}开头,现在我们需要在数据集中插入88,因此数据与{62,88}集成在一起,并且从小到大依次保留. 然后找到是否有58,但是如果要性表的顺序存储中进行排序,则必须移动62和88的位置,如下图左图所示,您不能移动它吗?好吧,当然是二叉树结构. 当使用二叉树方法时,首先我们将第一个数字62设置为根节点,88大于62,因此将其设为62的右子树,而58小于62则将其作为左子节点. 树. 这时,插入58并不会影响62和88之间的关系,如下图右图所示.
换句话说,如果我们现在需要查找集合{62,88,58,47,35,73,51,99,37,93},我们打算在计划使用二叉树结构时创建此收藏集. 它是要创建的有序二叉树. 如下图所示,在创建62、88和58之后,下一个数字47小于58,因为它是它的左子树(请参阅③),35是47的左子树(请参阅④)和73大于62. ,但小于88,是88的左子树(请参阅⑤),51小于62,小于58和大于47的右树,是47(请参阅⑥)和99大于62和88. 是88的右子树(请参阅⑦)c语言 二叉排序树,是37小于62、58、47,但大于35是,是35的右子树(请参阅⑧),并且93大于62、88,并剩下99子树(请参阅⑨).
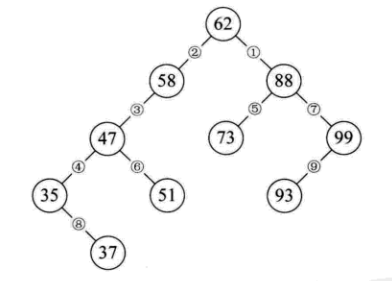
所以我们得到了一个二叉树,当我们遍历它时,我们可以得到一个有序的序列{35,37,47,51,58,62,73,88,93,99},所以我们通常称它是一个二进制排序树.

二进制排序树,也称为二进制排序树. 它可以是具有以下属性的空树或二叉树:
构造二进制排序树的目的实际上不是排序,而是提高查找,插入和删除关键字的速度. 无论如何,对有序数据集的搜索总是比无序数据集的搜索要快,并且二进制排序树的非线性结构也有利于实现插入和删除.
首先提供二叉树的结构:
/* 二叉树的链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; // 结点数据
struct BiTNode *lchild, *rchild; // 左右孩子指针
} BiTNode, BiTree;
想法: 当二叉树不为空时,首先将要找到的键值与根节点的键值进行比较. 如果它小于根节点的键值,则继续搜索左子树,否则找到右子树. 重复上述过程,直到搜索返回TRUE,否则返回FALSE.
// 递归查找二叉排序树T中是否存在key,指针f指向T的双亲,其初始调用值为NULL
Status searchBST(BiTree *T, int key, BiTree *f, BiTree **p)
{
if (T == NULL) // 查找不成功,指针p指向查找路径上访问的最后一个结点并返回FALSE
{
*p = f;
return FALSE;
}
else if (T->data == key) // 查找成功,则指针p指向该数据元素结点,并返回TRUE
{
*p = T;
return TRUE;
}
if (key < T->data)
return searchBST(T->lchild, key, T, p); // 在左子树中继续查找(注意此时f的赋值)
else
return searchBST(T->rchild, key, T, p); // 在右子树中继续查找
}
想法: 类似于查找,但需要父节点进行分配. 代码如下:
// 当二叉排序树T中不存在关键字等于key的数据元素时,插入key并返回TRUE,否则返回FALSE
Status insertBST(BiTree **T, int key)
{
BiTree *p; // 指针p指向查找路径上访问的最后一个结点
// 不存在关键字等于key的数据元素时,才插入
if (!searchBST(*T, key, NULL, &p)) // 通过指针p获得查找路径上访问的最后一个结点的地址
{
BiTNode *temp = (BiTNode *)malloc(sizeof(BiTNode));
temp->data = key;
temp->lchild = temp->rchild = NULL;
// 根据key与最后一个节点key值比较大小,决定是在左子树还是右子树插入
if (p == NULL)
*T = temp; // T为空树,则插入temp为新的根结点
else if (key < p->data)
p->lchild = temp;
else
p->rchild = temp;
return TRUE;
}
else
return FALSE; // 树中已有关键字相同的结点,不再插入
}
由于删除了二进制排序树,因此请注意,我们无法删除节点并使该树不满足二进制排序树的特性. 因此,我们需要考虑多种情况.

(1)删除叶节点
直接删除而不影响原始树,如下所示:
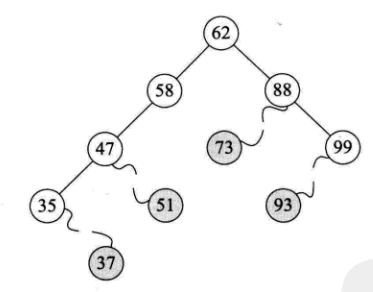
(2)删除仅具有左或右子树的节点
删除节点后,将其整个左子树或右子树移到已删除节点的位置. 子级继承父级业务,如下图所示:
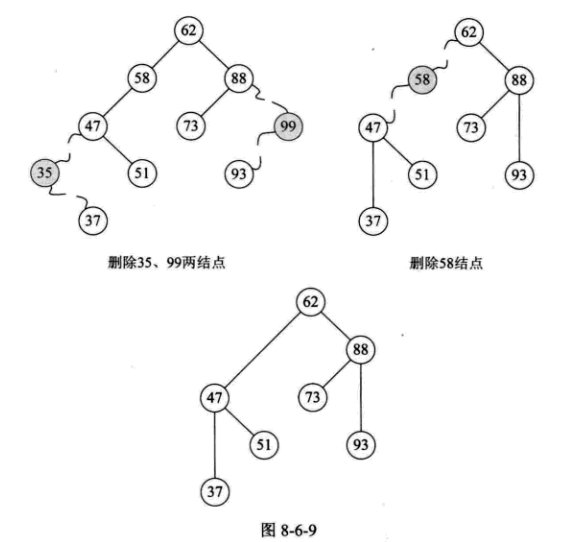
(3)删除具有左右子树的节点
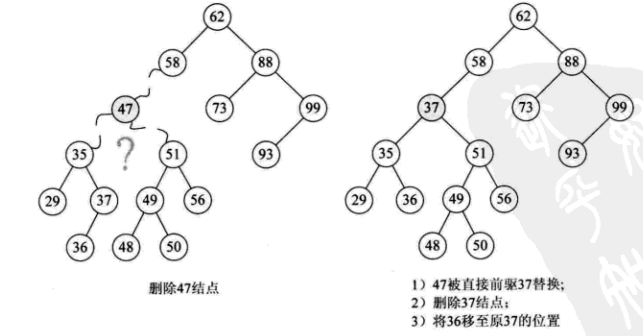
让我们仔细看看. 是否可以找到47个两个子树之一而不是47个?果然37或48都可以替换47. 这时,在删除47之后,整个二进制排序树没有实质性改变.
为什么要37和48?是的,它们恰好是二进制排序树中最接近或小于它的两个数字. 换句话说,如果我们对该二进制排序树执行有序遍历,则结果序列为{29,35,36,37,47,48,49,50,51,56,58,62,73,88 ,93,99}.

因此,更好的方法是找到节点p的有序序列的直接前驱(或直接后驱)s,用s替换节点p,然后删除节点s,如下图所示:
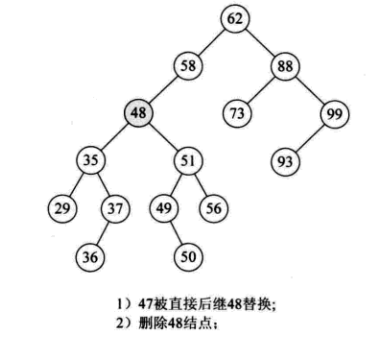
根据我们对删除节点的三种情况的分析:
离开节点;仅具有左或右子树的节点;带有左右子树的节点.
这是deleteNode的代码:
// 从二叉排序树中删除结点p,并重接它的左或右子树。
Status deleteNode(BiTree **p)
{
BiTree *q, *temp;
if ((*p)->rchild == NULL) // 右子树空则只需重接它的左子树(待删结点是叶子也走此分支)
{
q = *p; *p = (*p)->lchild; free(q);
}
else if ((*p)->lchild == NULL) // 只需重接它的右子树
{
q = *p; *p = (*p)->rchild; free(q);
}
else /* 左右子树均不空 */
{
q = *p;
temp = (*p)->lchild;
while (temp->rchild) // 转左,然后向右到尽头(找待删结点的前驱)
{
q = temp;
temp = temp->rchild;
}
(*p)->data = temp->data; // temp指向被删结点的直接前驱(将被删结点前驱的值取代被删结点的值)
if (q != *p)
q->rchild = temp->lchild; // 重接q的右子树
else
q->lchild = temp->lchild; // 重接q的左子树
free(temp);
}
return TRUE;
}
以下算法递归地在二进制排序树T中搜索键,并在找到键时将其删除.
// 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点
Status deleteBST(BiTree **T, int key)
{
if (!*T) // 不存在关键字等于key的数据元素
return FALSE;
else
{
if (key == (*T)->data) // 找到关键字等于key的数据元素
return deleteNode(T);
else if (key < (*T)->data)
return deleteBST(&(*T)->lchild, key);
else
return deleteBST(&(*T)->rchild, key);
}
}

可以看出,该代码与先前的二进制排序树搜索几乎相同,唯一的区别是,当找到与键值对应的节点时,将执行删除操作.
int main(void)
{
int a[10] = { 62, 88, 58, 47, 35, 73, 51, 99, 37, 93 };
BiTree *T = NULL;
// 插入元素
for (int i = 0; i<10; i++)
{
insertBST(&T, a[i]);
}
// 删除元素
deleteBST(&T, 93);
deleteBST(&T, 47);
// 中序递归遍历
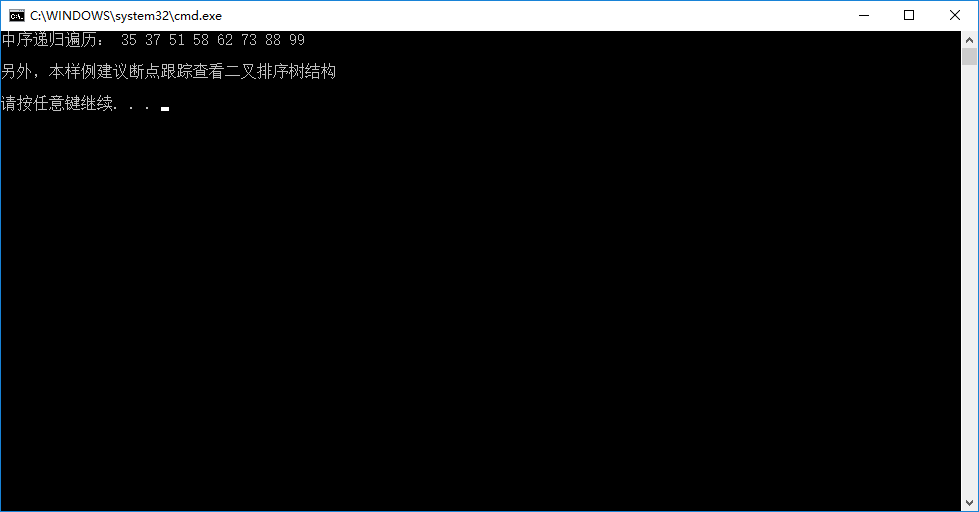
printf("中序递归遍历: ");
inOrderTraverse(T); // 中序递归遍历,会得到一个有序的序列
printf("\n\n另外,本样例建议断点跟踪查看二叉排序树结构\n\n");
return 0;
}
输出如下图所示:
简而言之,二进制排序树被存储为链接,这保留了在链接存储结构上执行插入或删除操作时不必移动元素的优点. 只要找到合适的插入和删除位置,就只需修改链接指针. 可以.
对于搜索二进制排序树,采用从根节点到要搜索的节点的路径. 比较次数等于二进制排序树中给定值的节点数. 技术情况至少是一次,即根节点是要查找的节点;最多不会超过树的深度. 即,二进制排序树的搜索性能取决于二进制排序树的形状. 问题在于二进制排序树的形状不确定.
例如,像{62c语言 二叉排序树,88,58,47,35,73,51,99,37,93}这样的数组,我们可以构建一个二进制排序树,如下图左图所示. 但是,如果数组元素的顺序是从小到大,例如{35,37,47,51,58,62,73,88,93,99},则二元排序树将成为极右倾斜树,请注意,它仍然是二进制排序树,如下图右图所示. 这时,它也在寻找节点99. 左图只需要两个比较,右图需要10个比较才能得到结果. 两者非常不同.
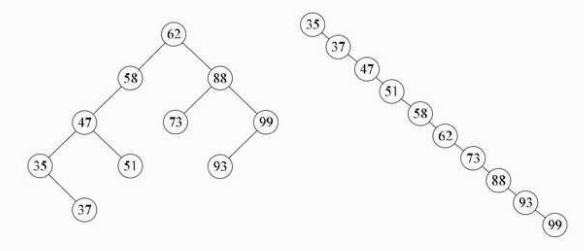
换句话说,我们希望二进制排序树更加平衡,也就是说,它的深度与完整的二进制树的深度相同,因此搜索时间也因O(logn)而复杂化,大约为搜索的一半. 在上图右侧的情况下,搜索时间复杂度为O(n),相当于顺序搜索. 因此,如果要按二进制排序树查找集合,则最好将其构建为平衡的二进制排序树.
参考:
大华数据结构-第8章搜索
二进制排序树
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-152725-1.html
 Win10教程| Win10系统的三种解决方案始终无法安装和更新
Win10教程| Win10系统的三种解决方案始终无法安装和更新 神威计算机多少钱 中国两大巨头同时宣布!苹果、三星要哭了
神威计算机多少钱 中国两大巨头同时宣布!苹果、三星要哭了 近100个国家/地区遭到了黑客攻击. 病毒武器源自美国国家安全局
近100个国家/地区遭到了黑客攻击. 病毒武器源自美国国家安全局
用经济手段瓦解北约和美欧联盟围堵中国战略