正则表达式: 示例
电脑杂谈 发布时间:2020-03-24 23:11:55 来源:网络整理
任何正则表达式插入都会使匹配子字符串的这一部分被记住. 记忆后,此子字符串可用于其他目的,如所述.
例如/章(\ d +)\. \ d * /解释多余的转义字符和特殊字符,并指出应记住该模式的这一部分. 它与字符'Chapter'完全匹配,后接一个以上的数字字符(\ d表示任何数字字符,+表示大于1次),后接小数点(该字符本身也是一个特殊字符;表示该模式必须寻找文字字符“. ”),后跟任何大于0的数字字符. (\ d表示数字字符,*表示大于0次). 此外,圆括号还用于记住第一个匹配的数字字符.
此模式与字符串“打开第4.3章,第6段”匹配,并且会记住'4'. 此模式与“第3章和第4章”不匹配,因为没有点“. ”. 在此字符串中的“ 3”之后.
括号中的
“ ?:”,此模式匹配子字符串将不被记住. 例如,(?: \ D +)匹配一个或多个数字字符,但不记得匹配的字符.
正则表达式可用于方法和方法以及方法中. 这些方法的详细说明.
当您想知道是否在字符串中找到匹配项时,可以使用测试或搜索方法. 有关更多信息(但速度较慢),可以使用exec或match方法. 如果使用exec或match方法,并且匹配成功,则这些方法将返回一个数组,并更新关联的正则表达式对象和预定义的正则表达式对象的属性(有关详细信息,请参见下文). 如果匹配失败,则exec方法返回null(即false).
在下面的示例中,脚本将使用exec方法在字符串中查找匹配项.
var myRe = / d(b +)d / g;
var myArray = myRe.exec(“ cdbbdbsbz”);
如果不需要访问正则表达式的属性,则此脚本通过另一种方法创建myArray:
var myArray = /d(b+)d/g.exec("cdbbdbsbz“);
如果要从字符串构建正则表达式,则此脚本具有另一种方法:
var myRe =新的RegExp(“ d(b +)d”,“ g”);
var myArray = myRe.exec(“ cdbbdbsbz”);
使用这些脚本,将在成功匹配后返回一个数组并更新正则表达式的属性,如下表所示:
对象属性或索引在示例中描述了相应的值
匹配的字符串和所有子字符串都会被记住.
在输入字符串中匹配的从零开始的索引值.
初始字符串.
输入: “ cdbbdbsbz”
匹配的最终字符.
记住子字符串.

匹配的字符串和所有记住的子字符串的长度.
下一个匹配的索引值. (仅在使用g参数时详细描述此属性. )
模式文本. 创建正则表达式时更新,不执行.
在本示例中,如第二种形式所示,您可以使用正则表达式创建未分配给变量的对象以初始化容器. 如果执行此操作正则表达式使用实例,则每次使用它就像使用新的正则表达式. 因此,如果使用未分配给变量的正则表达式,则以后将无法访问此正则表达式的属性. 例如,如果您具有以下脚本:
var myRe = / d(b +)d / g;
var myArray = myRe.exec(“ cdbbdbsbz”);
console.log(“ lastIndex的值为” + myRe.lastIndex);
此脚本的输出如下:
lastIndex的值为5
但是,如果您具有以下脚本:
var myArray = /d(b+)d/g.exec("cdbbdbsbz“);
console.log(“ lastIndex的值为” + /d(b+)d/g.lastIndex);
它显示为:
lastIndex的值为0
当/ d(b +)d / g使用两个状态不同的正则表达式对象时,lastIndex属性将获得不同的值. 如果需要访问正则表达式的属性,则需要创建对象初始化,首先应将其分配给变量.
在正则表达式模式中使用括号会导致记住相应的子匹配项. 例如,/ a(b)c /可以匹配字符串“ abc”并记住“ b”. 使用数组元素[1],... [n]调用括号中的那些匹配子字符串.
使用括号匹配的子字符串的数量是无限的. 返回的数组包含所有找到的子匹配项. 以下示例显示了如何使用带括号的子字符串匹配.
以下脚本使用replace()方法转换字符串中的单词. 在匹配的替换文本中,脚本使用替换$ 1,$ 2表示第一个和第二个带括号的子字符串匹配.
var re = /(\ w +)\ s(\ w +)/;
var str =“约翰·史密斯”;
var newstr = str.replace(re,“ $ 2,$ 1”);
console.log(newstr);
此表达式输出“史密斯,约翰”.
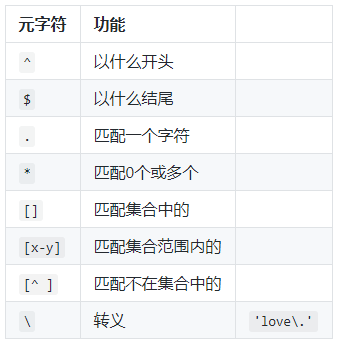
正则表达式具有五个可选参数,用于全局搜索和不区分大小写的搜索. 这些参数可以单独使用,也可以以任何顺序一起使用,也可以在包含正则表达式的部分中使用.
包含标志的正则表达式,请使用以下表达式:
var re = /模式/标志;
或
var re = new RegExp(“ pattern”,“ flags”);
应替换G,i,m,u,y或它们的组合.
值得注意的是,标志是正则表达式的一部分,以后不能添加或删除标志.
例如,re = / \ w + \ s / g将创建一个正则表达式,该正则表达式查找一个或多个字符,后跟一个空格,或组合所需的字符串.
此代码将输出[“ fee”,“ fi”,“ fo”].
var re = / \ w + \ s / g;
var str =“ fee fi fo fum”;
var myArray = str.match(re);
console.log(myArray);
在使用构造函数创建常规对象时,需要常规字符转义规则(以反斜杠\开头). 在此示例中,您可以:
var re = / \ w + \ s / g;
替换为:
var re = new RegExp(“ \ w + \ s”,“ g”);
两者是等效的,可能会得到相同的结果.
The
m标志用于指定将多行输入字符串视为多行. 如果使用m标志,则^和$匹配输入字符串中每行的开头或结尾,而不是整个字符串的开头或结尾.
示例: 使用规则性更改数据结构
下面的示例使用(继承自)方法来匹配名称* first last *输出新格式* last *,* first *. 该脚本使用$ 1和$ 2在括号中指示以前的匹配项.
var re = /(\ w +)\ s(\ w +)/;

var str =“约翰·史密斯”;
var newstr = str.replace(re,“ $ 2,$ 1”);
console.log(newstr);
显示“史密斯,约翰”.
示例: 正则表达式以分割不同的行
var text ='一些文本\ n还有更多\ r \ n还有\ r这就是结尾';
var lines = text.split(/ \ r \ n | \ r | \ n /);
console.log(行); //记录['Some text','And more more,'And yet','This is end']
正则表达式需要注意模式顺序.
示例: 在多行上使用正则表达式
var s =“拜托,请\ n,我今天快乐!”;
s.match(/yes.*day /);
//返回空值
s.match(/是[^] *天/);
//返回“是\ n,我的一天”
示例: 使用带有“ sticky”标志的正则表达式
此示例显示了如何在正则表达式上使用粘滞标记来匹配多行输入中的每一行.
var text =“第一行\第二行”;
var regex = /(\ S +)行\ n? / y;
var match = regex.exec(文本);
console.log(匹配项[1]); //记录“第一”
console.log(regex.lastIndex); //记录11
var match2 = regex.exec(文本);
console.log(match2 [1]); //记录“第二”
console.log(regex.lastIndex); //记录为“ 22”
var match3 = regex.exec(文本);
console.log(match3 === null); //记录为“ true”
您可以使用try {…} catch {…}来测试运行时是否支持粘滞标记. 在这种情况下,必须使用eval(…)表达式或RegExp(正则表达式字符串,标志字符串)语法(这是因为/ regex /标志符号将在编译时进行处理正则表达式使用实例,因此在catch块中处理异常)会在之前引发异常,例如:
varsupports_sticky;
尝试{RegExp('','y'); support_sticky = true;}
抓住(e){supports_sticky = false;}
警报(supports_sticky); //在Firefox 2中提醒“ false”,在Firefox 3中提醒“ true” +
示例: 使用正则表达式和Unicode字符
如上表所述,\ w或\ W仅匹配基本ASCII字符;例如“ a”到“ z”,“ A”到“ Z”,0到9和“ _”. 要匹配其他语言(例如西里尔字母或希伯来语)的字符,请使用\ uhhhh,“ hhhh”以十六进制表示字符的Unicode值. 以下示例显示了如何从单词中分离Unicode字符.
var text ='Образецtextнарусскомязыке';
var regex = / [\ u0400- \ u04FF] + / g;
var match = regex.exec(文本);
console.log(匹配[0]); //记录“Образец”
console.log(regex.lastIndex); //记录为'7'
var match2 = regex.exec(文本);
console.log(match2 [0]); //记录“на” [未记录“ text”]
console.log(regex.lastIndex); //记录为“ 15”
这里是获取Unicode中不同块范围的外部资源: Regexp-unicode-block
示例: 从URL提取子域
var url ='http://xxx.domain.com';
console.log(/[^.]+/. exec(url)[0] .substr(7)); //记录“ xxx”
正则表达式1: 构建正则表达式
正则表达式2: 图案的组成
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-151116-1.html
-

-
封行高
事实上中国在这几年内因为实力逐渐强大
-
-
张其立
情深缘浅
-
贺严东
哈哈
 fcnes游戏合集下载_任天堂 磁碟机_任天堂磁碟机赛车
fcnes游戏合集下载_任天堂 磁碟机_任天堂磁碟机赛车 二元排序树的相关算法排序
二元排序树的相关算法排序 c语言内存分配对应 Java系列笔记(3) - Java 内存区域和GC机制
c语言内存分配对应 Java系列笔记(3) - Java 内存区域和GC机制 143,000个CPU: 访问中国第一台自主超级计算机
143,000个CPU: 访问中国第一台自主超级计算机
一点都不