beautifulsoup怎么用_beautifulsoup text_beautifulsoup python
电脑杂谈 发布时间:2020-03-19 03:01:47 来源:网络整理
<head><title>The Dormouse's story</title></head>
<ur><li class="item-0"><a href="link1.html">first item</a></li></ur>
上面HTML文档中的head、title、ur、li都是HTML标签(节点名称),这些标签加上里面的内容就是tag。
获取Tags
# 导入模块
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 初始化BeautifulSoup对象,指定lxml解析器
soup = BeautifulSoup(html, 'lxml')
# prettify()方法格式化soup的内容
print(soup.prettify())
# soup.title选出title节点
print(soup.title)
# <title>The Dormouse's story</title>
print(type(soup.title))
# <class 'bs4.element.Tag'>
print(soup.head)
# <head><title>The Dormouse's story</title></head>
print(soup.p)
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p>说明:使用soup加节点名称可以获得节点内容,这些对象的类别是bs4.element.Tag,但是它查找的是在内容中第一个符合规定的节点。比如前面代码有多个p标签beautifulsoup怎么用,但是它只查找了第一个p标签。
对于Tag有两个重要的属性,name和attrs。当选取一个节点后,name属性获取节点的名称,attrs属性获取节点的属性(以字典形式返回)。
print(soup.name)
# [document] #soup 对象本身比较特殊,它的 name 即为 [document]
print(soup.head.name)
# head #对于其他内部标签,输出的值便为标签本身的名称
print(soup.p.attrs)
# {'class': ['title'], 'name': 'dromouse'}
# 在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
# 下面三种方法都可以获取字典里的值,是等价的,结果都一样
print(soup.p.get('class'))
# ['title']
print(soup.p['class'])
# ['title']
print(soup.p.attrs['class'])
# ['title']
# 还可以针对属性或者内容进行修改
soup.p['class'] = "newClass"
print (soup.p)
# <p class="newClass" name="dromouse"><b>The Dormouse's story</b></p>
获取了Tag,也就是获取了节点内容beautifulsoup怎么用,但是只想要获得节点内部的内容如何办?只需使用.string即可。
# 获取节点内容
print(soup.p.string)
# The Dormouse's story
print(type(soup.p.string))
# <class 'bs4.element.NavigableString'>在选择节点的之后,也可以先选择一个节点,然后以这个节点为基准选择它的子节点,父节点,子孙节点等等,下面就介绍常见的选用原则。
.contents

tag的.contents属性可以将tag的直接子节点以列表的方法输出。
下面举例选取head节点为基准,.contents选取head的子节点title,然后以列表返回。
print(soup.head.contents)
# [<title>The Dormouse's story</title>]输出模式为列表,可以用列表索引来获得它的某一个元素.
print(soup.head.contents[0])
# <title>The Dormouse's story</title>
.children
children属性和contents属性不同的是它返回的不是一个列表,而是一个。可用for循环输出结果。
print(soup.head.children)
# <list_iterator object at 0x0000017415655588>
for i in soup.head.children:
print(i)
# <title>The Dormouse's story</title>
上面两个属性都没法获取到基准节点的下一个节点,要想获取节点的所有子孙节点,就可以使用descendants属性了。它返回的只是一个。
print(soup.descendants)
# <generator object descendants at 0x0000028FFB17C0>
还有其它属性如查找父节点,组父节点的属性就不记录了(平时很少用)。

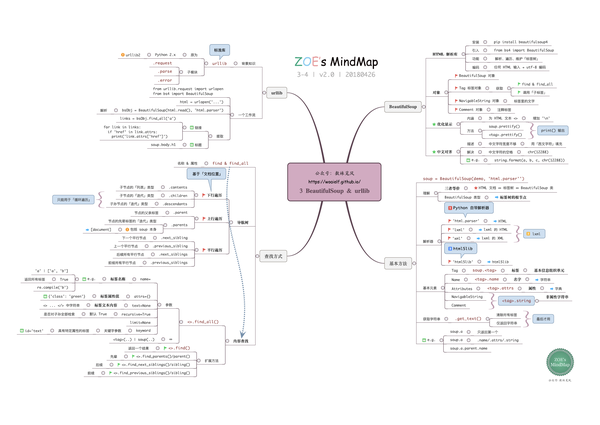
BeautifulSoup提供了一些查询方式(find_all,find等),调用对应方式,输入查询参数就可以受到我们想要的内容了,可以理解为搜索引擎的功能。(百度/谷歌=查询方法,查询内容=查询参数,返回的网站=想要的内容)
下面介绍更常见的find_all方法。
作用:查找所有符合条件的元素,返回的是列表方式
API:find_all(name, attrs, recursive, text, **kwargs)
1. name
name 参数可以按照节点名来查找元素。
A. 传字符串
最简单的过滤器是字符串.在搜索方式中传入一个字符串参数,BeautifulSoup会查找与字符串完整匹配的内容,下面的事例用于查找文档中所有的<p>标签。
print(soup.find_all('p'))
# 通常以下面方式写比较好
print(soup.find_all(name='p'))
B.传正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面举例中找出所有以p开头的标签。
import re
print(soup.find_all(re.compile('^p')))
C.传列表
如果传入列表参数,BeautifulSoup会将与列表中任一元素匹配的内容返回。下面代码会找到HTML代码中的head标签跟b标签。
print(soup.find_all(['head','b']))
# [<head><title>The Dormouse's story</title></head>, <b>The Dormouse's story</b>]
2. attrs
find_all中attrs参数可以按照节点属性查询。
查询时传入的参数是字典类型。比如查询id=link1的节点
print(soup.find_all(attrs={'id':'link1'}))
# [<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]对于常用的属性,可以不用以attrs来释放,直接传入查询参数就能。比如id,class_(class为Python关键字,使用下划线区分),如下:
print(soup.find_all(id='link1'))
print(soup.find_all(class_='sister'))运行结果:

[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3. text
text 参数可以搜搜文档中的字符串内容,与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表。下面代码查找节点里内容中有story字符串的节点,并返回节点的内容。
print(soup.find_all(text=re.compile('story')))
# ["The Dormouse's story", "The Dormouse's story"]
find方法与find_all方法的区别:
find_all:查询符合所有条件的元素,返回列表。
find:只查找第一个匹配到的元素,返回单个元素,类型tag。
查询方法与find_all大同小异。示例:
print(soup.find(name='p')) # 查询第一个p标签
print(soup.find(text=re.compile('story'))) # 查找第一个节点内容中有story字符串的节点内容运行结果:
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
The Dormouse's story
崔庆才 [Python3网络爬虫开发实战]:4.2-使用Beautiful Soup
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-144652-1.html
-

-
霍文艺
一个让人随便入侵领海领空的国家还谈什么强国
节奏有些乱了