Python爬虫学习笔记_BeautifulSoup基本用法
电脑杂谈 发布时间:2020-03-19 03:00:37 来源:网络整理
Python爬虫学习笔记_目录
Berkeley Zhou:Python爬虫学习笔记_目录zhuanlan.zhihu.com
使用BeautifulSoup的第一步当然是导入BeautifulSoup库了
from bs4 import BeautifulSoup然后我们把HTML文本送入BeautifulSoup进行解析

html_soup = BeautifulSoup(html, 'html.parser')这里的features='html.parser'是制定BS的解析方法
根据BeautifulSoup的官网文档beautifulsoup怎么用,我们可以对比一下可以得出不同解析方法的差别
解析器使用方式优势劣势Python标准库BeautifulSoup(markup,”html.parser”)-Python的内置标准库
-执行速度适中

-文档容错能力强Python 2.7.3 or 3.2.2)前的版本中文档容错能力差lxml HTML 解析器BeautifulSoup(markup,”lxml”)-速度快
-文档容错能力强必须安装C语言库lxml XML 解析器BeautifulSoup(markup,[“lxml-xml”])
BeautifulSoup(markup,”xml”)-速度快
-唯一支持XML的解析器需要安装C语言库html5libBeautifulSoup(markup,”html5lib”)-最好的容错性
-以浏览器的方法解析文档
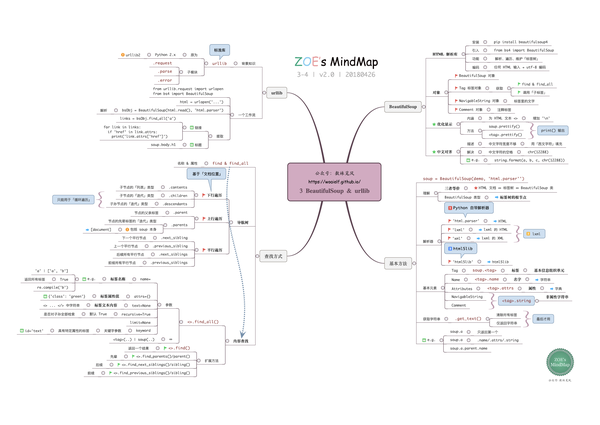
-生成HTML5格式的文档-速度慢
-不依赖外部扩展
注意,这里没有使用lxml解析还是html.parser是因为使用lxml需要调试额外的库,可能报错beautifulsoup怎么用,实际上和lxml应该没有太大差别
接下来我们呢使用解析完成返回的soup对象进行操作
例如,我们提取的这个网站的HTML文本如下

<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png">
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/>>爬虫教程</a> 中的简单测试.
</p>
</body>
</html>这个之后,如果我们想获得<p>节点内的内容,即
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/>>爬虫教程</a> 中的简单测试.
</p>我们只应该
print html_soup.p除此之外,我们还可以选取找到文本中所有的<a>tag的元素
href_all = html_soup.find_all('a')这么做的原因很简单,我们看到网页中所有的连接都放在了a tag中
这一操作返回的是一个列表,里面包含了所有的a tag元素
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-144650-1.html
-

-
刘元淑
有勇有茅
-
朱宇翔
òωó)大家好我就是舍
 梦幻西游手游华为版下载 v1.90.0 安卓版
梦幻西游手游华为版下载 v1.90.0 安卓版 广州瑞松展览
广州瑞松展览 简单的语言“数据报,客户端,服务器”
简单的语言“数据报,客户端,服务器” 一键查询各种Windows键
一键查询各种Windows键
但绝不容忍侵犯主权