五大主流分布式存储技术对比分析,你 pick 哪一种?
电脑杂谈 发布时间:2020-02-08 01:00:31 来源:网络整理
存储根据其种类,可分为块存储,对象存储和文件传输。在主流的分布式存储技术中,HDFS/GPFS/GFS属于文件传输,Swift属于对象存储,而Ceph可支持块内存、对象存储和文件传输,故称为统一存储。

一、 Ceph
Ceph最早起源于Sage就读硕士之后的工作、成果于2004年发表,并很快贡献给开源社区。经过多年的发展以后,已受到很多云计算和存储厂商的支持,成为应用更广泛的开源分布式存储平台。
Ceph根据场景可分为对象存储、块设备储存和文件传输。Ceph相比其他分布式存储技术,其优势点在于:它不单是存储,同时还充分利用了储存节点上的计算能力,在储存每一个数据时,都会通过推导得出该数据传输的位置,尽量将数据分布均衡。同时,由于采取了CRUSH、HASH等算法,使得它不存在传统的单点故障,且随着规模的缩减,性能并不会受到妨碍。
1.Ceph的主要架构

Ceph的更底层是RADOS(分布式对象存储平台),它带有可靠、智能、分布式等特点,实现高可靠、高能拓展、高性能、高自动化等用途,并最后储存用户数据。RADOS系统主要由两部分构成,分别是OSD和Monitor。
RADOS之上是LIBRADOS,LIBRADOS是一个库,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言,比如C、C++、Python等。
基于LIBRADOS层开发的有三种接口,分别是RADOSGW、librbd和MDS。

RADOSGW是一套基于当前流行的RESTFUL协议的端口,支持对象存储,兼容S3和Swift。
librbd提供分布式的块内存设备接口,支持块内存。
MDS提供兼容POSIX的文件系统,支持文件内存。
2.Ceph的功能模块

Ceph的核心模块包含Client客户端、MON监控服务、MDS元数据服务、OSD存储服务,各模块功能如下:
3.Ceph的资源划分
Ceph采用crush算法,在集群下,实现数据的迅速、准确存放,同时还能在软件故障或扩展硬件设施时,做到尽可能小的数据迁移,其原理如下:
当用户应将数据传输至Ceph集群时,数据先被分割成多个object,(每个object一个object id,大小可设定,默认是4MB),object是Ceph存储的最小存储单元。
由于object的总量很多,为了有效降低了Object到OSD的索引表、降低元数据的复杂度,使得写入和调用非常灵活,引入了pg(Placement Group ):PG用来管理object,每个object通过Hash,映射到某个pg中,一个pg可以包括多个object。
Pg再借助CRUSH计算,映射到osd中。如果是三副本的,则每位pg都会映射到三个osd分布式文件存储技术,保证了数据的冗余。

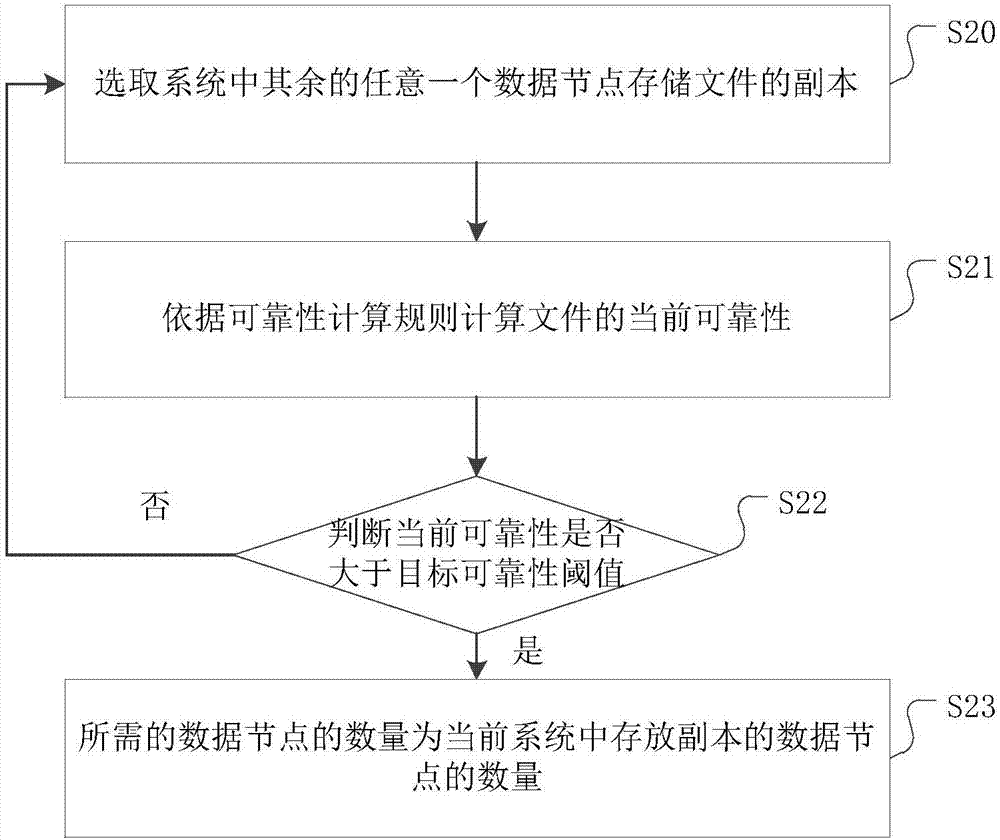
4.Ceph的数据写入
Ceph数据的写入流程
1) 数据通过负载均衡获得节点动态IP地址;
2) 通过块、文件、对象协议将文件存储至节点上;
3) 数据被分割成4M对象并获得对象ID;
4) 对象ID通过HASH算法被分配至不同的PG;
5) 不同的PG通过CRUSH算法被分配到不同的OSD

5.Ceph的特点
Ceph存在一些缺点:
去中心化的分布式解决方案,需要提前做好规划设计,对科技团队的要求能力非常高。
Ceph扩容时,由于其数据分布均衡的特点,会导致整个储存系统性能的增长。
二、 GFS
GFS是google的分布式文件传输平台,是专为传输海量搜索数据而设计的,2003年提出,是闭源的分布式文件系统。适用于大量的排序调用和次序追加,如大文件的读写。注重大文件的大幅稳定带宽,而不是单次读写的延迟。
1.GFS的主要架构
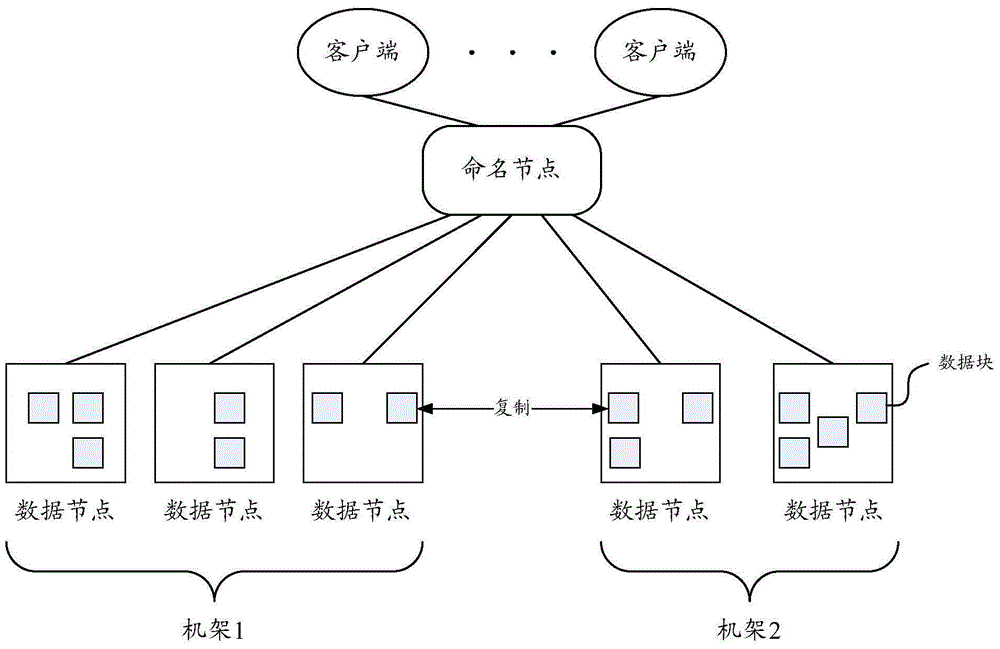
GFS 架构非常简洁,一个 GFS 集群通常由一个 master 、多个 chunkserver 和多个 clients 组成。
在 GFS 中分布式文件存储技术,所有文件被切分成若干个 chunk,每个 chunk 拥有唯一不变的标志(在 chunk 创建时,由 master 负责分配),所有 chunk 都实际传输在 chunkserver 的硬盘上。
为了容灾,每个 chunk 都会被复制到多个 chunkserve
2.GFS的功能模块

GFS client客户端:为应用提供API,与POSIX API类似。同时缓存从GFS master读取的元数据chunk信息;
GFS master元数据服务器:管理所有文件系统的元数据,包括命令空间(目录层级)、访问控制信息、文件到chunk的映射关系,chunk的位置等。同时 master 还管理平台范围内的各类活动,包括chunk 创建、复制、数据迁移、垃圾回收等;
GFS chunksever存储节点:用于所有 chunk的储存。一个文件被分隔为多个大小固定的chunk(默认64M),每个chunk有全局唯一的chunk ID。
3.GFS的写入流程
1) Client 向 master 询问要更改的 chunk在那个 chunkserver上,以及 该chunk 其他副本的位置信息;
2) Master 将Primary、secondary的相关信息返回给 client;
3) Client 将数据推送给 primary 和 secondary;
4) 当所有副本都证实收到数据后,client 发送写请求给 primary,primary 给不同 client 的操作分配序号,保证操作顺序执行;
5) Primary 把写请求发送到 secondary,secondary 按照 primary 分配的序号顺序执行所有操作;
6) 当 Secondary 执行完后回复 primary 执行结果;
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-139999-1.html
-

-
孙毅
自己都想推翻萨达姆
-
管雄甫
期待演员杨洋给我们展现他的潜力和作品
 Win10教程| Win10系统的三种解决方案始终无法安装和更新
Win10教程| Win10系统的三种解决方案始终无法安装和更新 神威计算机多少钱 中国两大巨头同时宣布!苹果、三星要哭了
神威计算机多少钱 中国两大巨头同时宣布!苹果、三星要哭了 近100个国家/地区遭到了黑客攻击. 病毒武器源自美国国家安全局
近100个国家/地区遭到了黑客攻击. 病毒武器源自美国国家安全局
这下麻烦了