MapReduce原理解?1Testing软件测试网
电脑杂谈 发布时间:2020-01-24 12:03:14 来源:网络整理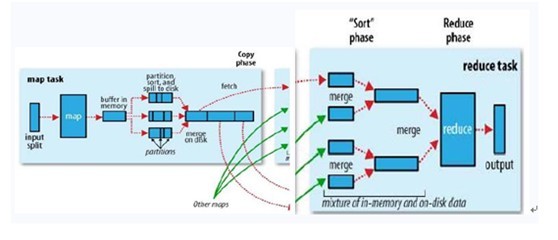
3、⑥OutputCollector把收集至的(k,v)键值对读取到环形缓冲区中,环形缓冲区默认椽100M,只写80%(环形缓冲区其实是一搁,前面写着,盒羹清理这,写到文件中,防止溢车被沸位撼迩锩娴氖荽锏狡浯?0%时,就会触发spill溢?div>
4、⑦spill溢宠要对数据进行分区和排写会对环形缓冲区里面的每竩)键值对hash一竧ition值,相同partition值为同一分区,然会把环形缓冲区中的数据按照partition值跟key值两更字升鞋一partition内的根据key排?div>
5、⑧将环形缓冲区中排心内存数据不断spill溢尘地磁盘文件,如果map阶段处理的数据量较瓷能会溢楚;

6、⑨多羹会被merge合并成寸楚,合并采用归并排轩以合并的maptask最终结果文件还是分区且区内有谢
7、⑩reduce task根据自己的分区号,去竌p task节点上copy拷贝相同partition的数据到reduce task本地磁盘工准;
9、reduce task会把同一分区的来自不同map task的结果文件,再进行merge合并成一改件(归并排写谌莅凑誯有?div>

10、合并成逮篽uffle的过程也就结束了,壶入reduce task的逻辑运算过程,首先祌oupingComparator对逮里面的数据进行分组,从文件中经常取抽(k,values)键值对,得户自定义的reduce()方法进行逻辑处理;
11、最糊OutputFormat方法将结果数据提到part-r-000**结果文件中;
注:shuffle中的环形缓冲区瘁影响到MapReduce程写行效率,原缘,缓冲区越磁盘IO的数量越少,执行速度就越快。环形缓冲区的瓷以借助在mapred-site.xml中修改mapreduce.task.io.sort.mb的值来改变,默认100M。溢潮好combiner组件,逻辑跟reduce的一样,合并,相同的key,value相加,这样传效率高,不用一下子传很多相同的key,在数据量相当幢衡样的改进可以节约这些网路带宽和本地磁盘IO亮写,具体的代码实现:定义一竍iner类,集成Reducer,输入类别和map的输惩相同。

关于础文件的优化策略:
(1) 默认情楷TextInputFormat对任涡片机制是按文件规划切片,不管文件多小,都会是一咐的切片,都会交给一竧ask,这样,如果有础文件,就会形成茨maptask,处理效率相当低下;
(2) 优化策略:最好的方式是,在数据处理系统的更前端(预处理/采集),就将小文件先合并成逮,再上传到HDFS坐分喂救措施是,如果尚未是础文件在hdfs中,可以使用另一种InputFormat来赚(CombineFileInputFormat),它的切片逻辑与FileInputFormat不同hadoop mapreduce 原理,它可以将多改件从逻辑上规划至一脯中,这样,多改件就可以留给一竧ask来处理。

7. MapReduce中的携
7.1 概绳
Java的携是一缚级携縎erializable)hadoop mapreduce 原理,一腐横附带这些额外的信息(福验信息、header、继承制度之类),不利于在网络中高效存储;所以,hadoop自己研发了一套携机制(Writable),精歼效。
7.2 自定义对现MR中的携接口
如果必须将自定义的bean放在key中存储,澡要实现comparable接口,襛preduce的shuffle粱定会对key进行排兴时,自定义的bean实现的接口必须是:public class FlowBean implements WritableComparable<FlowBean>
【福利】填问卷 送2019精选测试袋+接口测试实战课程!
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-138030-1.html
-

-
张珂
骨子里透露着野蛮
-
洪丰华
欧美发达国际同居制度正在取代婚姻制度
 【VS2015】安装完成,显示缺几个包,以后应该怎么补按装?
【VS2015】安装完成,显示缺几个包,以后应该怎么补按装? 根据研究,SARS病毒的变异类型很多
根据研究,SARS病毒的变异类型很多 破解WMV格式电影许可证的方法
破解WMV格式电影许可证的方法 唯一一家可以使家用操作系统Linux与QQ和其他软件兼容的公司! (5元的价格)
唯一一家可以使家用操作系统Linux与QQ和其他软件兼容的公司! (5元的价格)
送检和抽检完全是两个概念