图文:以MapReduce编程五步走为基础,说MapReduce工作原理
电脑杂谈 发布时间:2019-11-30 06:05:14 来源:网络整理
在之前的Hadoop是什么 <;
中早已说过MapReduce采用了分而治之的思想,MapReduce主要分为两部份,一部分是Map——分,一部分是Reduce——合
MapReduce的数据都是以键值对的方式存在的
首先,我们假定我们有一个文件,文件中存了下面内容
hive spark hive hbase
hadoop hive spark
sqoop flume scala
这里涉及到一个偏移量(一个字符或括号为1位)
第一行的偏移量为0,内容为“hive spark hive hbase”
第二行的偏移量为21,内容为“hadoop hive spark”
第三行的偏移量为39,内容为“sqoop flume scala”
* Map

* 输入
MapReduce处理的数据是从HDFS中读起来的
以偏移量为key,内容valuemapreduce工作原理图文详解,则存在:
(0,“hive spark hive hbase”)
(21,“hadoop hive spark”)
(39,“sqoop flume scala”)
* 输出
将输入的value中的词以括号为分割逐个取出来做key,1做value存起来
(hive,1)
(spark,1)
(hive,1)
(hbasemapreduce工作原理图文详解,1)

(hadoop,1)
注意:有多少行,Map就要循环做几次
* shuffle(之后会具体说,这里简单解释)
* 输入
map的输出
* 输出
相同的key的value进行合并
这里合并不是进行累加或别的运算,而是合并到一个集合中
(hive,[1,1,1])
(spark,[1,1])
(hbase,[1])
(hadoop,[1])

。。。。。。
* reduce
* 输入
shuffle的输出
* 输出
根据业务将value进行合并
例如当前的业务还会将value进行累加
MapReduce处理数据五步走
整个MapReduce程序,所有数据以(key,value)形式流动
* 第一步:input
正常状况上不需要写代码
仅仅在MapReduce程序运行的之后选定一个路径就能
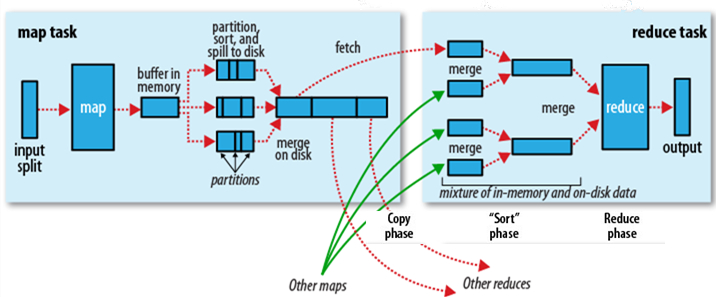
* 第二步:map(核心)
map(key,value,output,context)
key:每行数据的偏移量——基本没用
value:每行数据的内容——真正应该处理的内容
* 第三步:shuffle
不需要写代码
* 第四步:reduce(核心)
reduce(key,value,output,context)
key:业务需求中的key
value:要聚合的值
* 第五步:output
正常状况上不需要写代码
仅仅在MapReduce程序运行的之后选定一个路径就能
* 工作原理
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-131831-1.html
-
 朱晃
朱晃
 不需要审稿费的期刊_免审稿费的医学杂志_文教资料审稿费
不需要审稿费的期刊_免审稿费的医学杂志_文教资料审稿费 在严峻的冬季PC市场中,操作系统领域的三巨头将如何发挥作用?
在严峻的冬季PC市场中,操作系统领域的三巨头将如何发挥作用? 在RichTextBox控件中添加照片跟文字
在RichTextBox控件中添加照片跟文字 传统水行业的通用数字化转型
传统水行业的通用数字化转型