数据结构篇--浅析二叉树(BST)
电脑杂谈 发布时间:2019-11-25 05:02:15 来源:网络整理
二叉查找树(BST)也称为二叉搜索树或二叉排序树,二叉查找树的结点包含字段key。它的左子树不为空,那么左子树上所有结点的key都小于根节点的key
它的右子树不为空,那么右子树上所有结点的key都大于根节点的key
它的左右子树也分为二叉排序树。
遍历分为:
前序遍历(DLR):树根->左子树->右子树
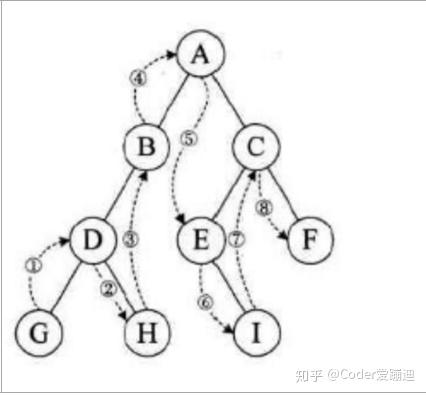
先访问根结点,在数组左子树,最后遍历右子树。并且在遍历左右子树时,仍需先访问根结点,然后递归左子树,最后遍历右子树。如图遍历次序为ABDGHCEIF

找了一个比较容易理解的事例
代码如下:
public void preOrder(Node root){

if(root != null){
syso(root.getValue() + “ ”);
//递归调用
preOrder(root.leftChild);
preOrder(root.rightChild);
}
}
中序遍历(LDR):左子树->树根->右子树
先遍历左子树,然后访问根结点,最后遍历右子树;并且在遍历左右子树的之后,仍然先遍历左子树,然后访问根结点,最后遍历右子树

如图遍历结点排序为:GDHBAEICF
public void inOrder(Node root){
if(root != null){
inOrder(root.leftChild);
syso(root.getValue() + “ ”);
inOrder(root.rightChild);
}
}
后序遍历(LRD):左子树->右子树->树根
先遍历左子树,然后递归右子树,最后访问根结点;先遍历左子树,然后递归右子树,最后访问根结点。如图节点数组排序为GHDBIEFCA

public void postOrder(Node root){
if(root != null){
postOrder(root.leftChild);
postOrder(root.rightChild);
syso(root.getValue() + “ ”);
}

}
二叉排序树的查找:
先比较根节点的值,如果应查找的值大于根结点,则查找根节点的左孩子节点,然后再次与对比,如果小于节点值,则查找右孩子节点,依次类推,直到查找到并返回结果以及没有查找到返回提示。
二叉排序树的插入:与查找类似,只不过一直找到叶子结点,若没有重复,则将待插入节点成为新的叶子结点插入。
二叉排序树的删除:
首先遍历二叉排序树,如果不存在要删除的节点,则不做任何操作因此分三种状况讨论:待删结点是叶子结点,则直接删掉待删结点只有左子树或者只有右子树,则将待删节点的父节点的引用置位该节点的孩子节点
待删节点既有左子树又有右子树,可以使用左子树的最大节点(直接前驱节点)或左子树的最小节点(直接后继节点)。
二叉树与快速排序的结合:
这一天仍然在反思树形结构与快速排序的结合改进。因为它们都具有“递归”和“二分”的观念,只不过数据结构不同。并且很明显在多数状况上,使用树状结构顺序,时间复杂度要比数组更高一些。树形结构进行顺序时,只应该先将数组元素插入树中,然后根据中序遍历的方式,取下来保存到数组中,那么就完成了数组的顺序。
当给出一组数列时,我们可以将数列中的元素,迁移至树形结构(Tree)中,为了减少将逆序列排成正序列以及将正序列排列成逆序列的状况发生,我们此处可以先将第一个数(left),最后一个数(right),中间一个数(mid)取出来,取出那三个数的后面数,来成为树的根结点。然后递归函数,依次从链表中取出每一个元素,与根节点对比,如果比根节点小,则放到右孩子节点,反之置于左孩子节点。然后接着取出下一个数组元素,从根结点开始进行非常,然后跟根节点的子儿子节点非常,直到最后,然后插入树结构中。
如果我们采用平衡二叉树(Self-balancing binary search tree)的树状结构,平衡二叉树能确保数据的左右两边的节点层级相差不会大于1.二叉排序树+数据结构,通过这种减少树形结构因为删除增加变成线性链表影响查询精度,保证数据平衡的状况上查找数据的速率近于二分法查找;当在这里这样做就将数组中的元素分为了两个别,在插入完成后,按照中序遍历即可。但是使用平衡二叉树,可能会造成节点的经常移动,影响算法的时间复杂度,但是结果既太简洁,并且便于遍历。
在树形结构中采用递归不断的对比,每次对比以后中二叉排序树+数据结构,都会将查找范围扩大一半,这里相当于快速排序的一种优化。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-131230-1.html
-

-
笠原弘子
日本海上自卫队最近声称
-
葛子嘉
注定了三哥只能当个三流国家
 80端口Web服务攻击痕迹
80端口Web服务攻击痕迹 正确理解我国的基本社会主义经济体制
正确理解我国的基本社会主义经济体制 扔掉鼠标并使用键盘来控制一切〜
扔掉鼠标并使用键盘来控制一切〜 2012年12月编程语言列表: Objective-C sprint捍卫年度语言
2012年12月编程语言列表: Objective-C sprint捍卫年度语言
恶意攻击诋毁用的吧