mapreduce 函数原理_mongodb mapreduce 原理_mapreduce函数
电脑杂谈 发布时间:2019-09-09 19:05:53 来源:网络整理
快结课了,该写个小结了。
mapreduce是两个操作方法,即映射和规约 也是这个分布式计算的思想
主要过程是这么的:
即实现一个指定的Map映射函数,用来把一组键值对映射成新的键值对,再把新的键值对发送个Reduce规约函数,用来确保所有映射的索引对中的每一个共享同样的键组
特点就是:
分不可靠 MP
通过把对数据的操作分发给通信网络上对每个节点,每个节点会周期性的返回它所完成的工作和最新状况,如果一个节点沉默时间达到预设的时间间隔,主节点会觉得这个节点挂掉了,并会把以前分配在这个节点上的数据,重新分发给新的节点,保证数据不丢失。
用途:
分不排序,web连接图翻转,web的访问日志分析,文档聚类,机器学习,统计预测等
MapReduce提供了下面的主要功能:
1)数据划分和计算任务调度:
系统手动将一个作业(Job)待处理的大数据划分为这些个数据块,每个数据块对应于一个计算任务(Task),并手动调度计算结点来处置相应的数据块。作业和任务调度功能主要负责分配和调度计算节点(Map节点或Reduce节点),同时负责监控那些节点的执行状况,并负责Map节点执行的同步控制。
2)数据/代码互定位:

为了避免数据通信,一个基本原则是本地化数据处理,即一个计算结点尽可能处理其本地磁盘上所分布存储的数据,这推动了代码向数据的迁移;当能够进行这样本地化数据处理时,再寻求其它可用节点并将数据从网络上传送给该节点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻求可用节点以提高通信延迟。
3)系统优化:
为了避免数据通信开销mapreduce 函数原理,中间结果数据处于Reduce节点前会进行必定的合并处理;一个Reduce节点所处理的数据可能会来自多个Map节点,为了防止Reduce计算阶段出现数据相关性,Map节点输出的后面结果需使用必定的思路进行适度的界定处理,保证相关性数据发送到同一个Reduce节点;此外,系统还进行一些计算性能改进处理,如对最慢的计算任务采取多备份执行、选最快完成者作为结果。
4)出错检测和恢复:
以高端商用服务器构成的MapReduce计算集群中,节点软件(主机、磁盘、内存等)出错和工具错误是常态,因此MapReduce需要能检查并防护出错节点,并调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据传输的可靠性,用多备份冗余储存模式增加数据传输的可靠性,并能迅速评估和恢复错误的数据。
ps:以上的功能特点是百度的,我也不太懂 总有每天会懂的。
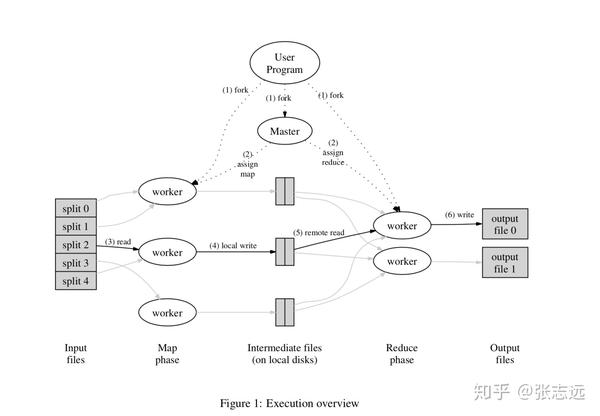
工作原理:
1..MapReduce库先把用户的输入文件界定为M份(M为用户定义)现在大概默认为128Mb
假如将1G数据根据128mb的数据块来划分则 可以划分为8块
2用户工程中的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业以及Reduce作业),worker的总量也是可以由用户指定的。、
3.被分配了Map作业的worker,开始加载对应分片的输入数据,Map作业总量是由M决定的,和split一一对应;Map作业从输入数据中抽取出字段对,每一个键值对都作为参数传递给map函数,map变量造成的后面键值对被缓存在硬盘中。
4..缓存的后面键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些后面键值对的位置会被通报master,master负责将信息转发给Reduce worker。
5.master通知分配了Reduce作业的worker它负责的分区在哪个位置(肯定不止一个地方,每个Map作业造成的后面键值对都或许映射到所有R个不同分区),当Reduce

worker把所有它负责的后面键值对都读回来后,先对他们进行顺序,使得同样键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是需要的。
6.reduce worker数组顺序后的后面键值对,对于每个唯一的键,都将键与关联的值释放给reduce函数,reduce函数造成的输出会添加到这个分区的输出文件中。
7.当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。

工作流程图

1. map任务处理
1.1读取键入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对读取一次map函数。
1.2
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4
对不同分区的数据,按照key进行顺序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。
2.reduce任务处理
2.1
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2
对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、values处理,转换成新的key、value输出。
2.3 把reduce的输出保存到HDFS文件中。
例子:实现WordCountApp

reducer

reducer
job


job 驱动
1.map 函数是对集合中的值进行操作mapreduce 函数原理,是对集合中元素操作,元素出现差异,但是,数量不变
执行流程:
HDFS上的数据与map 任务沟通时 会被切分split 一个split 对应一个map ,块和split数目不必定相同,每一个reduce任务 对应一个文件。结果存放在目录中
map任务运行在节点上(一个节点可以运行多个map任务,但是一个map任务不能跨多个结点上运行)reduce任务 与map 同理进入map 键值对 k1 v1原始数据
k3 v3 是结果数据
k2 v2 是中间数据
某些类的数据,送到某些reduce中,这个过程被称为shuffle——数据分配过程
map 和reducer 在为分布式下是在第一个节点的
map 任务次数 一般一个节点会有2个任务
输出流 hdfs 完成
其实在Mr 中最难的就是对业务逻辑的理解,代码都是死的。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-122305-1.html
-

-
徐振
如果不理睬
 如何安装系统
如何安装系统 VSCode插件的脱机安装
VSCode插件的脱机安装 JSP第3章练习
JSP第3章练习 嵌入式软件反编译中静态库功能识别的实现方法
嵌入式软件反编译中静态库功能识别的实现方法
打缓