Dataguru数据分析社区
电脑杂谈 发布时间:2019-07-23 14:09:24 来源:网络整理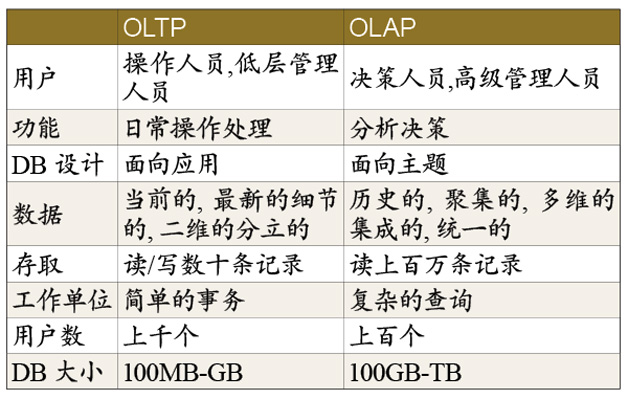
OLAP是联机分析处理 主要是查询处理
OLTP是联机事务处理 主要是事务处理 即插入 修改 查询和删除操作
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观、易懂的查询结果。
用户在界面上轻松的增、删、改、查,那么中也要有相应的增、删、改、查,而增删改查具体操作对象就是中的数据,说白了就是表中的字段。2):数据的操作,内存支持对数据进行增,删,改,查,数据完整性校验等一些基本功能。这种命令是sql语句,用来对的表和记录进行增、删、改、查操作[3]。
---------------------
设计的一个根基就是要弄清楚的类型。
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing事务处理,联机事务处理)、联机分析处理OLAP(On-Line Analytical Processing分析处理,联机分析处理)。

OLTP是传统的关系型的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
4 在绑定数据,做表的分页.update,delete,等操作都可以可视化操作,方便了初。4在绑定数据,做表的分页.update,delete,等操作都可以可视化操作,方便了初学者。shuffle write操作,我们可以简单理解为对pairs rdd中的数据进行分区操作,每个task处理的数据中,相同的key会写入同一个磁盘文件内。
OLTP:用户并发数都很多,但他们只对做很小的操作,侧重于对用户操作的快速响应,这是对最重要的性能要求。
b.临时文件:通常可以理解为做一个大的操作oltp选型,由于内存不足,需要将内存中的文件写到磁盘上,这样则有可能导致临时文件写的非常大,通常出现这种情况的时候,在做大的排序操作(order by,group by),由于内存不足,需要将数据刷写到临时文件中,下图的案例中,由于中一条order by的语句频繁的执行,但是排序的sql没有索引,导致了临时文件的频繁写操作:。b.临时文件:通常可以理解为做一个大的操作,由于内存不足,需要将内存中的文件 写到磁盘上,这样则有可能导致临时文件写的非常大,通常出现这种情况的时候,在做大 的排序操作(order by,group by),由于内存不足,需要将数据刷写到临时文件中,下图的案 例中,由于中一条order by的语句频繁的执行,但是排序的sql没有索引,导致了临时文件 的频繁写操作:。实现方式是先将须要排序的字段和可以直接定位到相关行数据的指针信息取出,然后在设定的内存(通过参数sort_buffer_size设定)中进行排序,完成排序之后再次通过行指针信息取出所需的columns。
常见的OLTP系统有:门票销售系统,银行交易等。
对mysql性能方面oltp选型,有包括磁盘优化(sas迁移到ssd)、服务器优化(内存、服务器本身配置)、除了二阶段的其 他核心性能优化选项(innodb_log_buffer_size/back_log/table_open_cache /thread_cache_size/innodb_lock_wait_timeout等)、连接池软件选择应用,对show * (show status/show profile)类的操作语句有深入了解,能够完成大部分的性能问题追查。性能最关键的因素在于io,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化最关键的问题在于减少磁盘的io,就个人理解应该分为物理的和逻辑的优化, 物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化。3、通过数据连接池优化并发查询的速度4、实现数据集缓存机制,大幅优化大量相同查询的速度,且数据表变化后自动更新缓存5、不用安装任何第3方库,unidac加搜索路径即可6、优化服务端多线程显示log的方式7、不用附加动态库完全都是 pas ^_^最近有个项目要用到远程对象,回头看了看之前的远程对象感觉都不太适用,老的版本很稳定,但是基于ado的。

OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
下表列出OLTP和OLAP之间的比较
操作人员,低层管理人员
决策人员,高级管理人员
日常操作处理
分析决策
面向应用

面向主题
当前的,的细节的,二维的分立的
历吏的,聚集的,多维的,集成的,统一的
读/写数十条记录
读上百万条记录
工作单位
简单的事务

复杂的查询
虽说在一张图纸内单位设置没有意义,但单位不同,标注、文字、线型、填充等的比例应该不相同,因此cad提供了英制和公制的模板来供大家选择,大家也可以根据需要来建立自己的模板,平时我们只要区分公制和英制就可以了,不必太关注单位,如果需要合并不同单位比例绘制的图纸时就要特别注意插入单位的设置。同一部剧,若翻译有需求可配备一到两名资源,一人下载低画质版本供翻译下载使用,另一人下载最高画质版本供后期和时间轴进行字幕及特效制作。ni multisim 10的元器件库提供数千种电路元器件供实验选用,同时也可以新建或扩充已有的元器件库,而且建库所需的元器件参数可以从生产厂商的产品使用手册中查到,因此也很方便的在工程设计中使用。
个人对这些模板的理解为:
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁。使用一般用途或事务处理模板
从用户执行start transaction命令到用户执行commit命令之间的一系列操作为一个完整的事务周期。但是在一些特殊的应用中,数据完整性比性能更重要的情况下,如果希望客户端回滚时,remoting server上执行的操作也可以回滚,那么可以使用msdtc的transaction internet protocol(tip)协议(事实上,msdtc除了支持常用的oletx分布式事务协议外,还支持xa和tip协议),让客户端启动的事务“传播”至remoting server,那样只要remoting server同样使用客户端传播过来的事务,即可实现remoting下的分布式事务。循环则更直观.递归一般用于处理一级事务能转化成更简的二级事务的操作.归纳不出二级事务或者二级事务更复杂的情况不能用.。
analysis应用会针对事务对response time进行统计,例如,脚本中有一个“查询”操作,为了明确知道“查询”操作所需要的响应时间,把这个操作定义为一个事务,这样在运行测试脚本的时候,loadrunner运行到该事务的时候,会开始计时,知道运行到该事务的结束点,计时结束。请注意,幻读重点是插入或者删除数据导致的(对满足条件的数据行集进行锁定),同样的道理,在事务1中,客户管理查询所有用户生日在1990-06-05的人只有20个,操作并没有完成,此时事务2中,刚好有一个新注册的用户,其生日也1990-06-05,在事务2中插入新用户并提交了事务,此时在事务1中再次查询时,所有用户生日在1990-06-05的人变为21个了,从也就导致了幻读。选择一个存活ip地址,扫描所开放的端口(分别用ping扫描,syn扫描尝试),并查询常用端口所对应的服务及操作系统信息。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-115152-1.html
-

-
蔡毅
自己活着
水军太多了