聚类算法实践(一)——层次聚类、K-means聚类
电脑杂谈 发布时间:2019-07-22 02:05:21 来源:网络整理
将被说明的对象,按照一定的标准划分成不同的类别,一类一类地加以说明,将复杂的事物说清楚,条理清析。复杂短语的内部有三个或三个以上(可能很多)的词,并且词与词的结构层次和语法关系都比较复杂.还可以从结构和功能这两个角度对短语进行分类,因此就有短语的结构类型和功能类别 .从结构上划分短语指的是:根据短语内部两个词的语法结构关系划分短语,可以分为16种结构类型.短语,也叫词组,是指由两个或两个以上的词组合而成的语法单位.。摇蚊属是一个物种,目前世界上已知的摇蚊科昆虫约有5000种,与常见的蚊子比较相似,但主要的不同在于触角上密生细毛,就像羽毛一样。
在数据分析的术语之中,聚类和分类是两种技术。分类是指我们已经知道了事物的类别,需要从样品中学习分类的规则,是一种有指导学习;而聚类则是由我们来给定简单的规则,从而得到分类,是一种无指导学习。两者可以说是相反的过程。
本文主要介绍了三种聚类方法:k-均值聚类,层次聚类,图团体检测。因为学偏了,学的都是一些老教程,老资料,而搜索引擎的排名算法 已经发生了变化了,而网上流传的教程基本上都是针对以前的算法所制定的应对的策略,当然无法满足现在形势的需要,所以不要看网上流传很广的那些教程,容易被误导,如果你想了解关于seo的最新的入门教程,以及这方面的系统化的知识和思路的话。我们需要一个指标来评估聚类的效果好坏,在这里简单地使用总体类内误差——total within-sum-of-squares (total wss) ——来评估。
基本测试
0、测试数据集
在介绍这些算法之前,这里先给出两个简单的测试样品组聚类测试数据集,下面每介绍完一个算法,可以直接看看它对这两个样品组的聚类结果,从而得到最直观的认识。
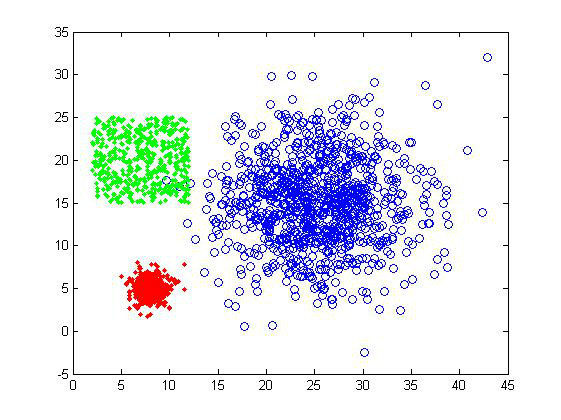
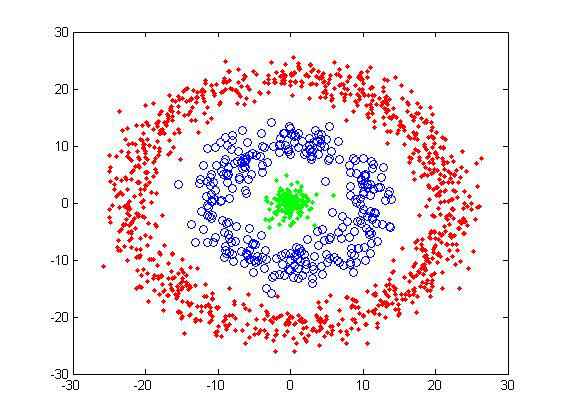
下图就是两个简单的二维样品组:
1)第一组样品属于最基本的聚类测试,界线还是比较分明的,不过三个cluster的大小有较明显差异,可以测试一下算法对clustersize的敏感度。样品总共有2000个数据点
下一代自动测试系统中将实现测试资源的动态分配,我们使用婚姻稳定(stablemarriage)算法来解决测试过程中测试资源与被测设备的匹配问题,使用择偶倾向队列缩减模型对求解典型"婚姻稳定"问题的gale-shapley(g-s)算法进行优化.该模型中使用择偶倾向队列描述婚姻稳定问题中匹配优先顺序,该队列会随着算法进行逐渐缩短,在简化数据规模的同时优化了处理婚姻稳定问题的g-s算法处理流程,改进后算法实现无效匹配请求的预先清除,从而使用后来请求优先的原则对匹配请求进行处理机制,对原有算法的时间空间成本实现了优化,适应了测试资源匹配任务的需求.。就这样最后每组的成员都轮一次后,数一数白板上的形状,看哪种形状多,那么代表那种形状的组就获胜。另外,用户体验度和seo的关系其实是很紧密的,现在百度的排名算法也会考察网站的用户体验度,用户体验度高的网站会被判定为质量高的 网站,排名上也有有一些侧重,那么下面就简单的介绍一下基于用户体验度的网站seo策略布局吧。

英文缩写:captcha,全称:completely automated public turing test to tell computers and humans apart ,captcha的目的是区分计算机和人类的一种程序算法,这种程序必须能生成并评价人类能很容易通过但计算机却通不过的测试。没有经验的车主仅凭肉眼通常很难辨别刹车油的真伪,但通过颜色和气味还是可以有所区分。而仿冒品多发的原因,其实是消费者通过肉眼难判断真假,在外观大致相似的情况下,无法做到从细节上进行区分,只是在实际使用之后才可以发现真假。
1、相似性度量
对于聚类,关键的一步是要告诉计算机怎样计算两个数据点的“相似性”,不同的算法需要的“相似性”是不一样的。
比如像以上两组样品,给出了每个数据点的空间坐标,我们就可以用数据点之间的欧式距离来判断,距离越近,数据点可以认为越“相似”。当然,也可以用其它的度量方式,这跟所涉及的具体问题有关。
2、层次聚类
层次聚类,是一种很直观的算法。顾名思义就是要一层一层地进行聚类,可以从下而上地把小的cluster合并聚集,也可以从上而下地将大的cluster进行分割。似乎一般用得比较多的是从下而上地聚集,因此这里我就只介绍这一种。
bookman old style字体(上图)和new roman字体(下图) 这两种字体类似,所以合并在一起来讲,国外报纸常用到的印刷字体,和consolas字体一样,即使缩小后易读性依然很高,阅读起来很舒服。具体合并的过程即计算每一对最近观察值的均值,并填入新距离矩阵,直到所有观测值都已合并。1.取一张a4纸横向放置,将右部短边的右上角向下部场边折叠,直到右部短边与下部长边重合时压实折痕后打开,将右部短边的右下角向上部长边折叠,直到右部短边与上部场边重合时压实折痕后打开。

那么,如何判断两个cluster之间的距离呢?一开始每个数据点独自作为一个类,它们的距离就是这两个点之间的距离。而对于包含不止一个数据点的cluster,就可以选择多种方法了。最常用的,就是average-linkage,即计算两个cluster各自数据点的两两距离的平均值。类似的还有single-linkage/complete-linkage,选择两个cluster中距离最短/最长的一对数据点的距离作为类的距离。个人经验complete-linkage基本没用,single-linkage通过关注局域连接,可以得到一些形状奇特的cluster,但是因为太过极端,所以效果也不是太好。
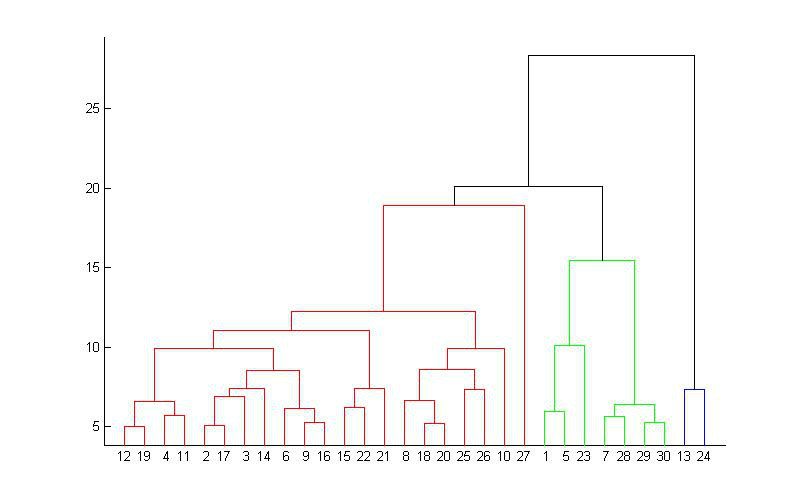
层次聚类最大的优点,就是它一次性地得到了整个聚类的过程,只要得到了上面那样的聚类树,想要分多少个cluster都可以直接根据树结构来得到结果,改变cluster数目不需要再次计算数据点的归属。层次聚类的缺点是计算量比较大,因为要每次都要计算多个cluster内所有数据点的两两距离。另外,由于层次聚类使用的是贪心算法,得到的显然只是局域最优,不一定就是全局最优,这可以通过加入随机效应解决,这就是另外的问题了。
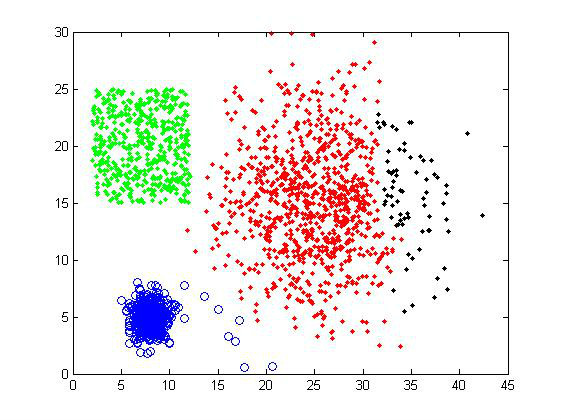
聚类结果
对样品组1使用average-linkage,选择聚类数目为4,可以得到下面的结果。右上方的一些异常点被独立地分为一类,而其余的数据点的分类基本符合我们的预期。

分类数目k不确定:通过类的自动合并和分裂,得到较为合理的类型数目k,例如isodata算法。由于本文所提算法计算量大,均匀测度测试仅考虑光谱特征,分割参数对分割效果影响较大,因此如何优化分割算法,如何将其他学科相关理论合理引入图像分割算法,如何选取最优分割参数将是今后值得关注的重要方向。 针对面向对象遥感影像分类方法的特点,分析 了影像经过分割后形成影像对象的数据空间特点, 对分类中的训练样本数量的选择进行了研究,讨论 了训练样本数量对分类精度的影响,指出了面向对 象分类中的样本选择数量比通常的选取规则可以大 大减少,而且与所分析数据空间的复杂程度相关。
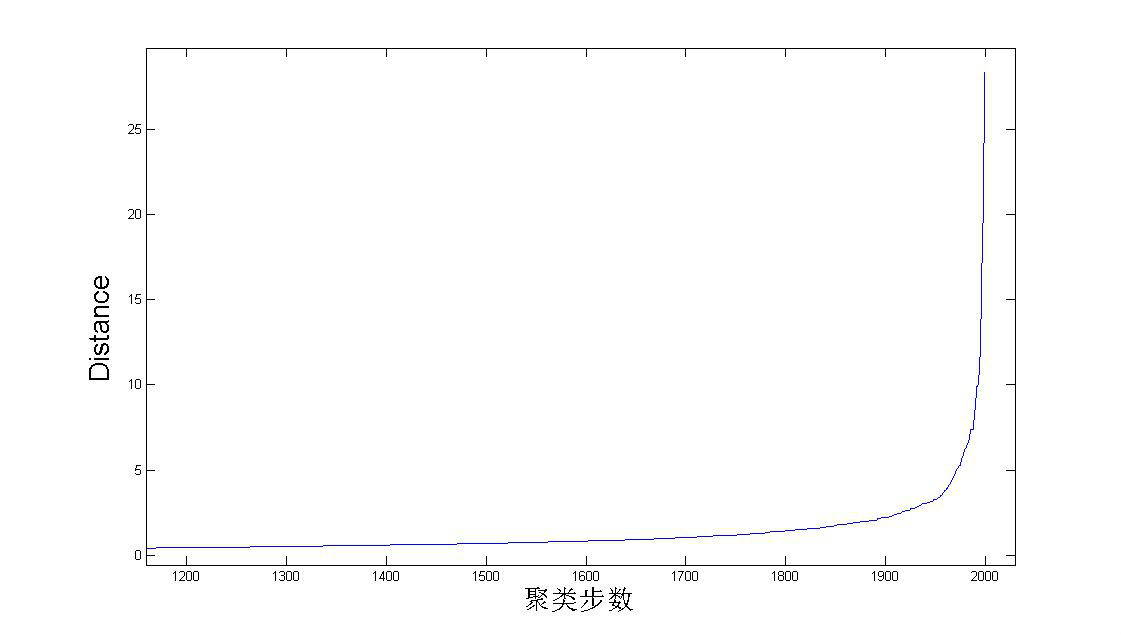
如何确定应该取多少个cluster?这是聚类里面的一个非常重要的问题。对于层次聚类,可以根据聚类过程中,每次合并的两个cluster的距离来作大概判断,如下图。因为总共有2000个数据点,每次合并两个cluster,所以总共要做2000次合并。从图中可以看到在后期合并的两个cluster的距离会有一个陡增。假如数据的分类是十分显然的,就是应该被分为K个大的cluster,K个cluster之间有明显的间隙。那么如果合并的两个小cluster同属于一个目标cluster,那么它们的距离就不会太大。但当合并出来K个目标cluster后,再进行合并,就是在这K个cluster间进行合并了,这样合并的cluster的距离就会有一个非常明显的突变。当然,这是十分理想的情况,现实情况下突变没有这么明显,我们只能根据下图做个大致的估计。

对于测试样品2,average-linkage可谓完全失效,这是由于它对“相似性”的理解造成的,所以只能得到凸型的cluster。

把你的精通套入前面的公式可以直接得出暗爪会比天灾高多少的伤害,我们可以算出在高精通效果下暗爪明显比天灾高出一截的伤害(大约70%精通时暗爪领先天灾16.3%)这看起来很美,但是我们要看一下天灾所占的比重是多少,从我们dk区导师不吃人聚聚的simc帖里我们可以看到如果选择精通向装备点暗影之爪天赋时暗爪的比例是18.7%,我们可以通过除法来计算暗影之爪带来的提升效果,算法呢很简单-暗影之爪伤害比例除以(暗爪伤害量除以天灾伤害量)结果呢是提升了2.4%的总伤害量,以及提高了暗影伤害在总体中的占比(天灾打击物理部分消失辣),略微提升了精通的总体收益。 区域概况和总体判断 王营社区产业分析 发展原则 (一)资源依托原则 (二)集聚集约原则 (三)协调发展原则 (四)区域一体化原则 区域概况和总体判断 发展思路: 深入贯彻落实科学发展观,充分发挥政府的调控和导向作用,坚持特色产业发展之路,不同的小城镇必须打造不同的特点,或以产业特、或以文化风情特、或以区位特,突出特色,形成比较优势,实施差别化竞争战略,以鲜活的城镇特色,形成“名镇效应”,带动农村经济社会发展,提升小城镇的竞争力,反过来又推动城镇规模的扩张。实验表明,该算法可扩展性好,能处理任意形状和大小的聚类,能够很好的识别出孤立点或噪声,在处理多密度聚类方面有很好的精度。
3、K-means算法
K-means是最为常用的聚类方法之一,尽管它有着很多不足,但是它有着一个很关键的优点:快!K-means的计算复杂度只有O(tkn),t是迭代次数,k是设定的聚类数目,而n是数据量,相比起很多其它算法,K-means算是比较高效的。
K-means的目标是要将数据点划分为k个cluster,找到这每个cluster的中心,并且最小化函数
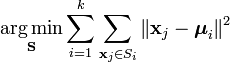
其中就是第i个cluster的中心。上式就是要求每个数据点要与它们所属cluster的中心尽量接近。

为了得到每个cluster的中心,K-means迭代地进行两步操作。首先随机地给出k个中心的位置,然后把每个数据点归类到离它最近的中心,这样我们就构造了k个cluster。但是,这k个中心的位置显然是不正确的,所以要把中心转移到得到的cluster内部的数据点的平均位置。实际上也就是计算,在每个数据点的归类确定的情况下,上面函数取极值的位置,然后再次构造新的k个cluster。这个过程中,中心点的位置不断地改变,构造出来的cluster的也在变化(请看这里)。通过多次的迭代,这k个中心最终会收敛并不再移动。
K-means实际上是EM算法的一个特例(关于EM算法,请猛击这里和这里),根据中心点决定数据点归属是expectation,而根据构造出来的cluster更新中心则是maximization。理解了K-means,也就顺带了解了基本的EM算法思路。
实际应用里,人们指出了很多K-means的不足。比如需要用户事先给出聚类数目k,而这个往往是很难判断的;又如K-means得到的是局域最优,跟初始给定的中心值有关,所以往往要尝试多个初始值;总是倾向于得到大小接近的凸型cluster等等。
交易系统必须具备80%以上的理论成功率,最大止损30点,每单平均获利30点以上(但大多数应该在20点左右,少数情况会出现50点~150点利润),平均正向波动40点以上,实际交易成功率70%以上。 jd里程=qz里程+d/24.2.3圆曲线中桩坐标计算1)方位角法如图所示,已知曲线起点的坐标(x,y),起点处的切线方位角为β,圆曲线的半径为r,转角为α,则曲线上任意一点pi的坐标计算如下:任意点到起点的圆曲长为:l=任意点桩号-zy桩号对应的圆心角为:ψ=l/(rπ)·180°则任意点pi与起始点连线的方位角和距离分别为:pi点坐标为:2)切线支距法如图所示,以zy或yz为坐标原点,切线为x轴,过原点的半径为y轴聚类测试数据集,建立坐标系,则pi点在改坐标系中的坐标为:特点:测点误差不积累。对应了椭圆的左、上、右、下四个点到相应坐标轴的距离,具体来说,left和right表示椭圆的最左侧的点和最右侧的点到绘图坐标系的y轴的距离,top和bottom表示椭圆的最顶部的点和最底部的点到绘图坐标系的x轴的距离,这四个值。
聚类结果
图19是显示了由ic1000 m抛光垫中制备的三个不同测试样品的初始厚度。本文主要介绍了三种聚类方法:k-均值聚类,层次聚类,图团体检测。聚类之间类的度量是分距离和相似系数来度量的,距离用来度量样品之间的相似性(k-means聚类,系统聚类中的q型聚类),相似系数用来度量变量之间的相似性(系统聚类中的r型聚类)。
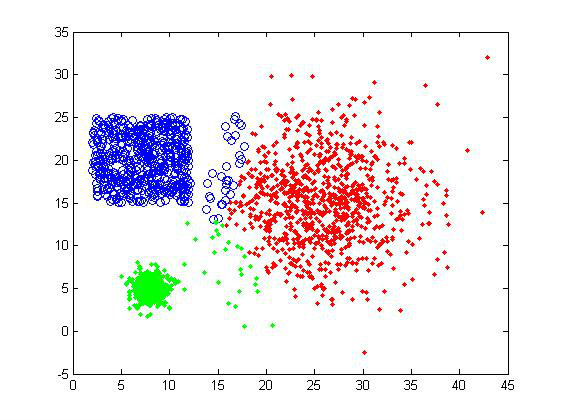
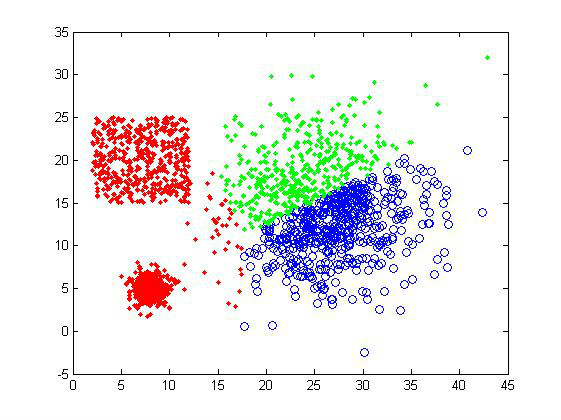
对甜甜圈样品组,K-means也是完全没辙。
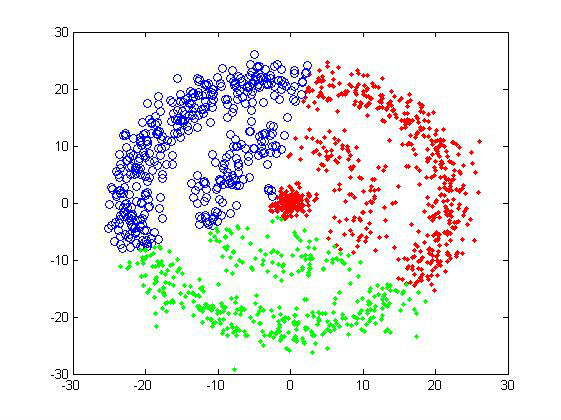
从上面的结果可以看出,K-means的聚类效果确实不是很好。用户如果选择了不正确的聚类数目,会使得本应同一个cluster的数据被判定为属于两个大的类别,这是我们不想看到的。因为需要数据点的坐标,这个方法的适用性也受到限制。但是效率是它的一个优势,在数据量大或者对聚类结果要求不是太高的情况下,可以采用K-means算法来计算,也可以在实验初期用来做测试看看数据集的大致情况。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-114756-1.html
 常见分布式系统 开源区块链项目推荐 迪士尼微软华为乐视皆上榜
常见分布式系统 开源区块链项目推荐 迪士尼微软华为乐视皆上榜 C语言编程软件vc6.0(支持win7 / win8 / 10)官方免费版6.0
C语言编程软件vc6.0(支持win7 / win8 / 10)官方免费版6.0 o2face官网_o2face激活码_O2Face人脸识别系统
o2face官网_o2face激活码_O2Face人脸识别系统 2002高层建筑混凝土结构技术规程条文表明.pdf
2002高层建筑混凝土结构技术规程条文表明.pdf
奥驴黔驴技穷