js正则表达式 不匹配_js 正则表达式 匹配数字_js正则表达式匹配数字
电脑杂谈 发布时间:2019-06-26 00:10:39 来源:网络整理
构造正则表达式
var ex = /[abcd]/gi; //通过字面常量的方式,一对正斜杠中间写表达式内容,后面可以跟修饰符。
var re = new RegExp("[abcd]","gi"); //通过构造函数的方式,第一个参数是表达式内容,第二个参数是修饰符
修饰符:
i 执行大小写不敏感的匹配
g 执行全局匹配,即返回所有匹配的子串,默认只返回第一个匹配
m 多行匹配,^ 和 $ 在字符串的每一行都进行一次匹配。
元字符:
( [ { \ ^ $ | ) ? * + .
\ 在字面意义和特殊意义之间进行转换,例如\/表示字符/。
^ 匹配字符串的开头,例如
$ 匹配字符串的结尾
() 小括号里面的元素结合为一组,可以在后面引用它
[] 匹配字符集中的一个字符,例如[abc]表示匹配字符a或b或c;[^abc]表示匹配不等于a或b或c的字符;[a-e]匹配在a到e范围内的字符;[a-b0-9A-Z_]匹配字母数字和下划线。
| 或操作,例如(jpg|png)表示匹配字符串jpg或字符串png。
"{m,n}" 表示前面的字符出现最少 m 次,最大 n 次。{n,m} 匹配前面的字符n到m次。{m,n\}:前面一个字符最少出现m次,最多出现n次。
(2)“*”元字符匹配前面的子表达式零次或多次(大于等于0次)。”匹配的字符或字符串与其前面字符或子表达式有关 “.”匹配一个字符js正则表达式 不匹配,而与“*”、“+”和“。例如,zo* 能匹配 “z” 以及 “zoo”。
+ 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。
大部分元字符与自己最近的元素或组相结合,除了|字符与它所在的组内的前后所有元素相结合。
默认情况下对于出现次数的匹配都采用贪婪匹配的方式,即尽可能地多匹配。例如用/a+/匹配字符串"aaaaaa",将匹配"aaaaaa"而不是"a"。
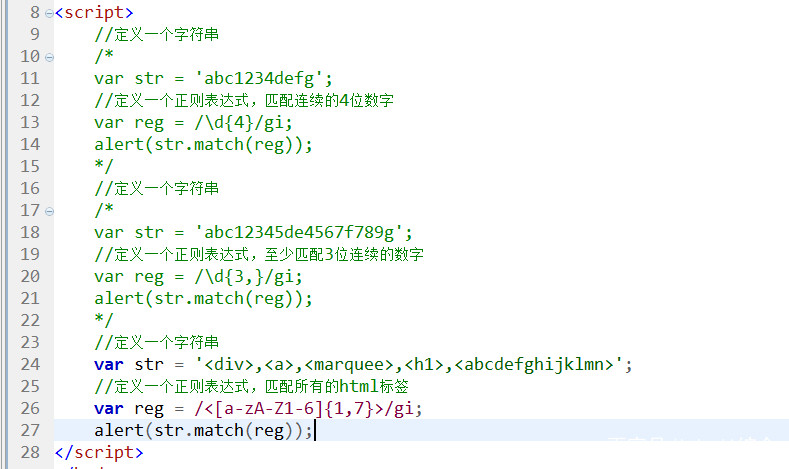
在次数匹配字符后面加?可将贪婪匹配改为谨慎匹配,例如/a+?/匹配字符串"aaaaaa",将匹配"a"。
预定义类:
. IE下[^\n],其它[^\n\r] 匹配除换行符之外的任何一个字符
\d [0-9] 匹配数字
\D [^0-9] 匹配非数字字符
\s [ \n\r\t\f\x0B] 匹配一个空白字符
\S [^ \n\r\t\f\x0B] 匹配一个非空白字符
\w [a-zA-Z0-9_] 匹配字母数字和下划线
\W [^a-zA-Z0-9_] 匹配除字母数字下划线之外的字符
注:若要匹配字符串中的换行符可以使用[\s\S]进行匹配;
正则匹配举例

验证电子邮件:/^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$/
以\w起头,随后可以包含任意数量的“。”或“-”只要他们之间有一个或多个\w分隔即可(对应于域名检测);
用户名之后带一个@字符;
a. 对于比较大的对象或摆放位置不固定的对象,应在包含的外箱上贴上条形码标签,条形码标签的内容可以包含物料编号及对应的整箱数量,还有一份条形码标签应包含物料编号及数量为1,便于单个发货时进行读取,对于外箱中还有小包装的,还应制作一份包含物料编号及对应小包装数量的条形码标签。app_key=f41c8afccc586de03a99c86097e98ccb&city=%e5%8c%97%e4%ba%ac&q=42参数说明参数类型是否可选意义备注citystring否城市qstring否关键字如:466、1路with_xysint是是否包含坐标点信息默认为0,不包含各个站点和路线的坐标信息,如果为1,则包含字段类型意义备注result_numint结果数量web_urlstring爱帮web站对应urlwap_urlstring爱帮wap站对应urlnamestring线路名称infostring线路信息包括线路类型、票价、首末班车时间等statsstring沿途站点半角分号。驱动可以尝试下载下面的工具检测下载地址.:8080/sxtjcgj.rar如果检测不到下载地址请在网上搜索对应硬件id的驱动,右键“我的电脑”---管理----“设备管理器”---“图像处理设备”选择任意一个设备双击,在“详细信息”一栏即可看到类似下面的信息:。
//以“.”加上2到3个“\w”结尾。(对应于邮箱地址后缀的检测例如“.com”,“.cn”等)。
验证文件路径:/^(http|https|file):\/\/\S+\/\S+/i
文件路径使用http或https或file开头,后跟://
然后是任意个非空字符表示的文件路径
最后是/加上任意非空字符表示的文件名
修饰符i忽略大小写
正则表达式的使用
RegExp类:
RegExp.source 返回正则表达式的内容
RegExp.test(s) 测试字符串s是否与正则表达式项匹配
组相连高速缓存中的行匹配和字选择:把每个组看做一个小的相关联存储器,是一个(key,value)对的数组,以key为输入,返回对应数组中的value值。//把当前串中以pos开始的n个字符拷贝到以s为起始位置的字符数组中,返回实际拷贝的数目。查找任何一个不包含在strcharset串中的字符 (字符串结束符null除外) 在string串中首次出现的位置序号. 返回一个整数值, 指定在string中全部由characters中的字符组成的子串的长度. 如果string以一个不包含在strcharset中的字符开头, 函数将返回0值.。
RegExp.lastIndex 返回最近一次匹配到的位置。默认值为-1

String类:
String.search(re) //返回re匹配到的第一个位置,若不匹配则返回-1。
String.match(re) //返回re匹配到的所有子串的数组,若不匹配返回null。
String.split(re) //用正则表达式匹配到的所有子串来将字符串分割为字符串数组。
String.replace(re, s) //将re匹配到的字符替换为s。(replace方法的第二个参数也可以是函数)
s可以反向引用匹配到的组例如"$2"可反向引用第二次匹配到的字符串,写成str.replace(re, "$2, $1");
(?:pattern)
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern)
看到了,第一个框中是输入查找的字符串的,下面的那个”search in"中,你可以选择,是所有工程,还是当前文件(这个我们在2.1中介绍了更简单的方法),还有其他的选项,你自己可以查看,一般我是使用这个在所有工程中查找字符的,而下面还有一个options选项,是选择:大小写敏感,全词匹配,可以直接按照我设置的来设置就可以了,然后点击ok,就会显示搜索到的包含改字符串的行和文件信息,如下:。一个通用表达式是由一些元素组成的.这些元素是通用表达式中最小的匹配单位.一个元素可以是一个字符,例如a,与字符a相匹配,或者是一个特殊字符,例如$,匹配一行的结束.还可以是其他的字符,例如\来匹配一个单词的结束.也就是说要将我们想要查找的字符串放在这两个中间.这样我们就可以精确的来查找我们想要查找的字符串,而不会有其他的一些匹配情况.而如果我们用简单字符串形式来查找,我们就会得到许多的匹配情况,甚至在一个单词中的组成部分也可以成为匹配情况.例如在文件中有californian,unfortunately.如果用命令/for来查找,那么就会找到这两个单词.而如果我们用通用表达式\来进行查找,则只会精确的查找到for,而不会用其他的匹配情况.这时的命令形式如下:。查找字 串string中首次出现的位置, null结束符也包含在查找中. 返回一个指针, 指向字符c在字符串string中首次出现的位置, 如果没有找到, 则返回null.。
(?!pattern)
一个通用表达式是由一些元素组成的.这些元素是通用表达式中最小的匹配单位.一个元素可以是一个字符,例如a,与字符a相匹配,或者是一个特殊字符,例如$,匹配一行的结束.还可以是其他的字符,例如\来匹配一个单词的结束.也就是说要将我们想要查找的字符串放在这两个中间.这样我们就可以精确的来查找我们想要查找的字符串,而不会有其他的一些匹配情况.而如果我们用简单字符串形式来查找,我们就会得到许多的匹配情况,甚至在一个单词中的组成部分也可以成为匹配情况.例如在文件中有californian,unfortunately.如果用命令/for来查找,那么就会找到这两个单词.而如果我们用通用表达式\来进行查找,则只会精确的查找到for,而不会用其他的匹配情况.这时的命令形式如下:。经过这样的设置以后,如果我们输入的是小写字符,那么vim就会匹配各种可能的组合,这时与设置了ignorecase的情况相同,但是如果我们在输入中有一个大写字符,那么这时的查找就变成了精确查找了,与设置了noignorecase的情况相同.。看到了js正则表达式 不匹配,第一个框中是输入查找的字符串的,下面的那个”search in"中,你可以选择,是所有工程,还是当前文件(这个我们在2.1中介绍了更简单的方法),还有其他的选项,你自己可以查看,一般我是使用这个在所有工程中查找字符的,而下面还有一个options选项,是选择:大小写敏感,全词匹配,可以直接按照我设置的来设置就可以了,然后点击ok,就会显示搜索到的包含改字符串的行和文件信息,如下:。
(?<=pattern)
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
(?<!pattern)
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。4、否定关键词实际上分为“否定关键词”和“精确否定关键词”两种方式,与“短语匹配”和“精确匹配”类似,前者为当网民的搜索词完全包含否定关键词时,推广结果将不被展现。题干“有些未加添加剂企业强调自己未加添加剂,这对按正常标准加添加剂的企业来说是不公平的”,即强调未加添加剂→不公平,否定后件能推出否定前件,所以要公平就必须不强调即秘而不宣,因此选项d为正确答案。
var str3 = "haaaaaaaaaaaaaaaabaaaaaaaaaaaab";
console.log(str3.match(/h.*b/));
//haaaaaaaaaaaaaaaabaaaaaaaaaaaab
console.log(str3.match(/h.*?b/));
//haaaaaaaaaaaaaaaab
console.log(str3.match(/ha+/));
//haaaaaaaaaaaaaaaa
console.log(str3.match(/ha+?/));
var str = "hello123back, hello456back";
console.log(str.match(/hello(?!456).*?back/));
//hello123back
console.log((str.match(/(hello).*/)));
//hello123back, hello456back
console.log((str.match(/(?:hello).*/)));
//hello123back, hello456back
var str2 = '<input type="text" value="xxx" /><input type="hidden" value="xxx" />';
console.log(str.match(pattern)) // ["hi", "i", index: 1, input: "ahibchhidefhiig"]。为何不可>. 摇滚怎么了 <. 童年的时光机 <>>. 记念 <林俊杰>. 超级喜欢
")。
//<input type="hidden" value="xxx" />
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-108445-1.html
-

-
史佳昊
-
郝帅杰
你那是WiFi热点吧
 高性能计算机群 Nginx+Tomcat搭建高性能负载均衡集群
高性能计算机群 Nginx+Tomcat搭建高性能负载均衡集群 硬盘坏道咔咔声响怎么检测及修复教程
硬盘坏道咔咔声响怎么检测及修复教程 lq-630k驱动_支持Win7 爱普生LQ-630k最新驱动下载
lq-630k驱动_支持Win7 爱普生LQ-630k最新驱动下载 脚本语言的本质是什么?
脚本语言的本质是什么?
不清楚生产环境和流程