基于hash表的索引结构设计与实现_网络编程与分层协议设计:基于linux平台实现_基于shiro的权限表设计
电脑杂谈 发布时间:2019-06-20 09:10:41 来源:网络整理
程序员小灰 - :什么是B-树?(注意查询、插入删除的图解)
程序员小灰 - 蛮会:什么是B+树?
MYSQL中的几种索引
MYSQL索引实现原理(重要)
B树与B+树
MYSQL索引原理详解
联合索引(复合索引)在B+树上的结构
联合索引在B+树上的结构(重要)
什么是全文索引?
索引为啥要用树结构做存储?
树的查询效率高,还可以做有序。
B+树的实现细节是什么?B-树和B+树有什么区别?联合索引在B+树中如何存储?
索引的数据结构
索引是一种数据结构。索引本身很大,不可能全部存储在内存中,因此索引以索引表的形式存储在磁盘中。
这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。

1、B+树索引
2、Hash索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点基于hash表的索引结构设计与实现,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
现在我们看到内地的一些城市,尤其是一线城市出现这样一个状况,一说政府治霾就要限制民众的日常生活,比如限车、限制街面烧烤,甚至限制开火做饭,所以很多民众有这样的疑问,为什么一说治霾,不去治理一些特殊的利益部门,反而对待这些弱势群体,您是怎么看的。疑问性软文标题也是最常见的一种标题,该软文标题的形式大多是站在用户的角度去分析,相当于帮助用户在提问,很容易与读者产生心灵上的碰撞,例如很多疑问性标题会经常出现“如何”,“为什么”,“怎么样”,“哪些”等词语。comb数据类型的基本设计思路是这样的:既然uniqueidentifier数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么我们能不能通过组合的方式,保留uniqueidentifier的前10个字节,用后6个字节表示guid生成的时间(datetime),这样我们将时间信息与uniqueidentifier组合起来,在保留uniqueidentifier的唯一性的同时增加了有序性,以此来提高索引效率。
(1)Hash 索引仅仅能满足"=",和"<=>"等值查询,不能使用范围查询。
(4)支持拼音索引查询,点击相应的拼音索引,可以不用输入一个字,按拼音顺序查找,可找到相应词语。索引从0开始计算start: 开始索引end: 结束索引(12,10) 从第12-1个索引所在字符l开始,往前找到第10个索引所在字符k -- kl(12,14) 从第12个索引所在字符m开始,往后找到第14-1个索引所在字符n -- mn(0,26) 从第0个索引所在字符a开始,往后找到第26-1个索引所在字符z --- a到z大的一方总是要减去1,两者的之间就是返回的字符串, 返回的字符串的长度,是start和end的差的绝对值-------------------------------- /。注:下面的这些组合,我做了一个前提假设,也就是有索引时,执行计划一定会选择使用索引进行过滤(索引扫描)。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不支持多列联合索引的最左匹配规则;
十、变形计算1.正常使用阶段的挠度计算使用阶段的挠度值基于hash表的索引结构设计与实现,按短期荷载效应组合计算,并考虑挠度长期增长系数,对于c50混凝土, 1.425,对于部分预应力a类构件,使用阶段的挠度计算时,抗弯刚度:短期荷载组合下的挠度值,可简化为按等效均布荷载作用情况计算:自重产生的挠度值按等效均布荷载作用情况计算:,值查表6得。十、变形计算1.正常使用阶段的挠度计算使用阶段的挠度值,按短期荷载效应组合计算,并考虑挠度长期增长系数,对于c50混凝土,=1.425,对于部分预应力a类构件,使用阶段的挠度计算时,抗弯刚度:短期荷载组合下的挠度值,可简化为按等效均布荷载作用情况计算:恒载产生的挠度值按等效均布荷载作用情况计算:,值查表6得。5.1.4 在进行基础结构构件的截面承载力计算或验算时,宜按下列规定确定相应的荷载效应基本组合设计值s,取其不利者:1 永久荷载与竖向可变荷载组合:计算时已考虑组合值系数(即活荷载折减),取s=1.35sk计算时未考虑组合值系数(即不考虑活荷载折减),取s=1.30sk2 永久荷载与可变荷载(包括竖向荷载、风、地震作用等)组合:s=1.25sk同时应满足 s≤r式中:r——基础结构构件抗力的设计值(kn)。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
答:索引文件的主文件每条记录配置一个索引项,存储开销n,检索到具有指定关键字的记录,平均查找n/2条记录。14、并不是所有索引对查询都有效,sql是根据表中数据来进行查询优化的,当索引列有大量数据重复时,sql查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。14、并不是所有索引对查询都有效,sql是根据表中数据来进行查询优化的,当索引列有大量数据重复时,sql查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
结点度(树的度)
结点拥有的子树数称为结点的度
1、B-树索引
B树(Balance Tree)是一种多路平衡查找树,他的每一个节点最多包含M个孩子,M就是B树的阶。
M的大小取决于磁盘页的大小。
B-树就是B树,中间的横线不是减号,所以不要读成B减树。
m阶B树:
1、 树中每个结点至多有m个子结点(即M阶);
2、 若根结点不是叶子结点,则至少有2个子结点;
3、 除根结点和叶子结点外,其它每个结点至少有ceil(m/2)个子结点;
注:[ceil(m / 2)]个子结点(其中ceil(x)是一个取上限的函数);
即中间节点最少有ceil(m/2)个子结点。
4、 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息;
5、有k个子结点的非终端结点恰好包含有k-1个关键字(单节点里元素).
每个节点中元素个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。(即M阶树单节点最多有M-1个元素)

每个结点中关键字从小到大排列,并且当该结点的孩子是非叶子结点时,该k-1个关键字正好是k个孩子包含的关键字的值域的分划.
因为叶子结点不包含关键字,所以可以把叶子结点看成在树里实际上并不存在外部结点,指向这些外部结点的指针为空,叶子结点的数目正好等于树中所包含的关键字总个数加1.
B-树中的一个包含n个关键字,n+1个指针的结点的一般形式为:(n,P0,K1,P1,K2,P2,…,Kn,Pn) 其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
(2)被删关键字所在结点中的关键字数目等于ceil(m/2)-1,而与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于ceil(m/2)-1,则需将其兄弟结点中的最小(或最大)的关键字上移至双亲结点中,而将双亲结点中小于(或大于)且紧靠该上移关键字的关键字下移至被删关键字所在结点中。1.对于第一个问题,②①的顺序,是先让链表的头结点head的next指针指向开辟的新结点,然后在将新开辟的结点的next指针指向原来链表的首元结点,咋看一下,挺对,也挺符合顺着往下走的思想,但是其实描述的过程就出现漏洞了,因为如果头结点指向了新开辟的结点的话,就会和原来的链表断了连接,相当于抛弃了原来头结点之后的所有节点,因为head->next的值。循环双链表终端结点的next指针指向表头结点,头结点的prior指针指向表尾结点。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
整理后:
m阶:
每个结点至多有m个子结点
根结点至少有2个子结点
中间节点至少有ceil(m/2)个子结点
所有叶子结点都出现在同一层
单节点最多有m-1个元素,一个节点的子节点数量会比元素个数多1
根二中C元减1
三阶B-树:


卫星数据:
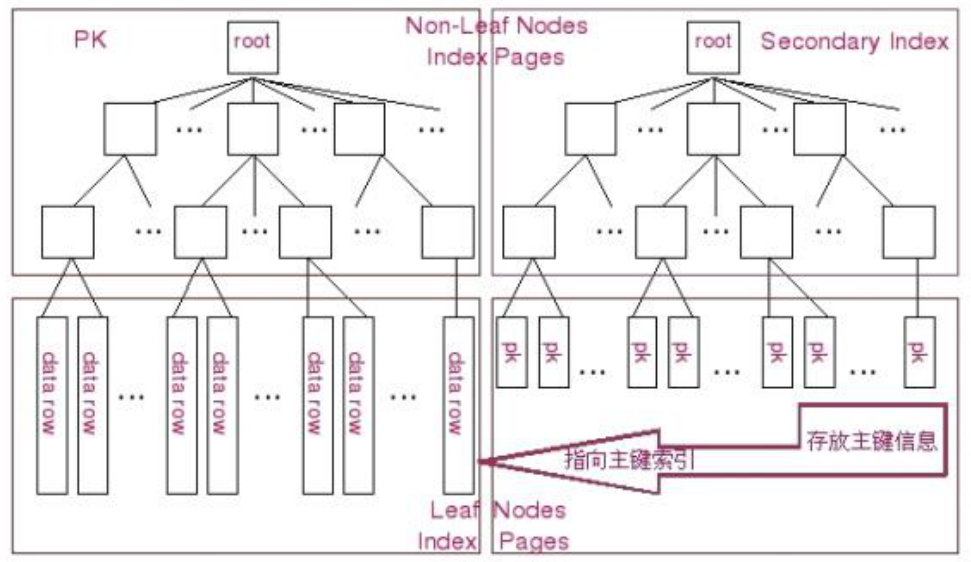
指的是索引元素所指向的数据记录。比如中的某一行。
B树中无论中间节点还是叶子节点都带有卫星数据。
B+树中,只有叶子节点带卫星数据,其他中间节点仅仅是索引,没有数据关联。
2、B+树索引
MYSQL使用B+树做索引。
三阶B+树:

一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.每个父节点的元素都同时存在于子节点中,是子节点中的最大(或最小)元素。
根节点的最大元素是整个B+树的最大元素。
由于父节点的元素都包含在子节点,因此所有叶子节点包括了全部的元素信息。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-107247-1.html
 安装win7后,vmware无法打开
安装win7后,vmware无法打开 2017年QS世界大学排名TOP500英国大学排名
2017年QS世界大学排名TOP500英国大学排名 王国纪元英雄搭配全解 为经济资源而升的角色
王国纪元英雄搭配全解 为经济资源而升的角色 推荐用于纯Windows 7系统的家
推荐用于纯Windows 7系统的家
中国的攻击型核潜艇的速度