干货|看大牛如何复盘递归神经网络!
电脑杂谈 发布时间:2019-05-31 10:32:26 来源:网络整理
在大牛的眼中,递归神经网络(RNNs)的运作就像孩子们玩的手机游戏(也叫做华人耳语(私下传话),其实就是暗指递归神经网络是一个封闭的形式运作的。)。在RNN的每个处理步骤,RNN必须对已收到的新信息进行编码并将信息通过一组反馈连接传递到下一个处理步骤。对于设计神经网络模型(RNN)来说,最大的挑战就是要保证通过反馈连接每次传递的信息量不会降低。同样重要的是要确保纠错信息可以通过反向传播通过模型。Hochreiter和Schmidhuber是第一个解决这些问题的人,他们将一个称为长期记忆模式(LSTM模式)装配到RNN上。其实,他们的方法就是引入网络门控机制,以此来控制信息存储、更新和抹去。LSTM模式其实还是在以孩子们玩手机游戏的方式运作,但可以使用复印机的精度进行操作。由于LSTM模型的出现,已经有几个RNN架构计划使用网络门控机制。
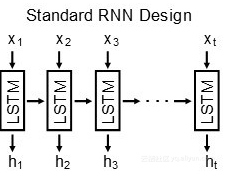

任何机制都有它的局限性,下面我们来了解一下,具有门控机制的RNN模型的局限性,假设你有100000符号序列,第一个符号必须通过门控机制100000次。除了LSTM模型的门,其他的门都可能是不完全开放的,假设门是99.99%开的,信号从第一个符号将降低到0.9999⊃1;⁰⁰⁰⁰⁰原始值的0.0000454。所以即使严格执行复印机模型精度,如果序列是从一开始就是非常长的信息序列,最后的结果是信息还是会遭受到很大的损失。
为了克服现有RNN架构的局限性,一个新的模型需要包括反馈连接到每个处理步骤,而不仅仅是前面的步骤递归向量。 一个解决方案是使用注意力机制,假设我们想对时间序列数据进行建模使用循环神经网络(RNN)并且使用注意力机制。 在每一个处理步骤,RNN的输出都要被注意力机制模型加权。 然后将每一个步骤加权输出聚合在一起加权平均。加权平均值的结果称为上下文向量。 上下文向量可以表示信息在数据中的任何时间点的聚合效果。

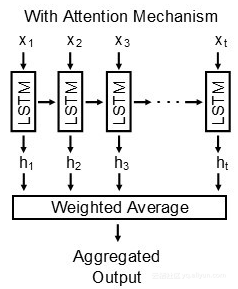
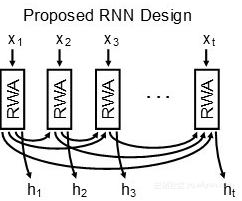
注意力机制的主要约束是对整个时间序列数据只产生一个上下文向量。 在生成上下文向量之前,必须将整个数据序列读入模型。换句话说,注意力机制是静态的。为了克服这个限制,我们最近提出了一种新的方法来计算注意机制——使用移动平均值。因为注意力机制只不过是一个加权平均值,所以它的计算是一个正在运行的计算过程。这需要从每个处理步骤保存分子和分母,以在下一次迭代中使用。通过保持注意力机制的移动平均值,每个时间步长都能产生一个新的上下文向量。通过这种方法,注意力机制变得动态,可以在模型运行中计算。

i=ix1为指数加权移动平均算法的加权因子,1表示第1个指数加权数,1 = 1,2,… m,m表示指数加权个数。与2016年相比,2017年,平均品牌资源力、品牌传播力和品牌发展力相对保持稳定,未存在明显差异,平均品牌带动力降低了近4个百分点,而平均品牌经营力提升较为明显,提升幅度达到了7.5个百分点。

通过usb3.0连接pc,在整体数据传输i/o端性能以及底层数据测试对比方面,从对比数据中我们可以清楚看到几乎所有项测试usb3.0相较于usb2.0的性能提升均在2倍左右,并且基于出色的控制器性能让数据在传输中更稳定,保证了数据在随机传输和持续传输方面的稳定性表现。和上一个版本一样,spec cpu 2006包括了cint2006和cfp2006两个子项目,前者用于测量和对比整数性能,后者则用于测量和对比浮点性能,spec cpu 2006中对spec cpu 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。spec cpu 2006是spec组织推出的cpu子系统评估软件最新版,我们之前使用的是spec cpu 2000.和上一个版本一样,spec cpu 2006包括了cint2006和cfp2006两个子项目,前者用于测量和对比整数性能,后者则用于测量和对比浮点性能,spec cpu 2006中对spec cpu 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。
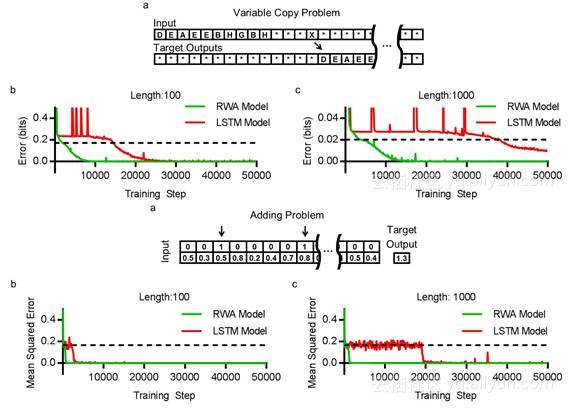
从图中可以看出,RWA模型能更好地扩展到更长的序列。 我们不期望RWA模型总是优于并且能够RNN模型,像LSTM那样。LSTM模型可能是更好的选择(在一些例子中),当最近的信息比旧信息更重要时。这就是说,我们可能想要一个拥有对过去有记忆的RNN模型,这也是我们除了RWA模型以外的替代方法。
作者介绍:Jared Ostmeyer
计算生物学博士后研究员。 目前在德州达拉斯生活和工作。
声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息存储空间服务。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-102639-1.html
-

-
申伟宁
我是比较含蓄的那一波
-
周溥溥
谋求战略均衡点
 QQ黑名单能恢复么?
QQ黑名单能恢复么? 常见分布式系统 分布式存储比较
常见分布式系统 分布式存储比较 diskeeper_diskeeper 16_diskeeper怎么样
diskeeper_diskeeper 16_diskeeper怎么样 嵌入式软件反编译中静态库功能识别的实现方法
嵌入式软件反编译中静态库功能识别的实现方法
王八蛋的美国佬