卷积神经网络如何进行图像识别
电脑杂谈 发布时间:2019-05-27 17:11:55 来源:网络整理
卷积神经网络如何进行图像识别
Savaram Ravindra 36大数据 2017-09-08

什么是图像识别?为什么要进行图像识别?
在机器视觉的概念中,图像识别是指软件具有分辨图片中的人物、位置、物体、动作以及笔迹的能力。计算机可以应用机器视觉技巧,结合人工智能以及摄像机来进行图像识别。
对于人类和动物的大脑来说,识别物体是很简单的,但是同样的任务对计算机来说却是很难完成的。当我们看到一个东西像树、或者汽车、或者我们的朋友,我们在分辨他是什么之前,通常不需要下意识的去研究他。然而,对于计算机来说,辨别任何事物(可能是钟表、椅子、人或者动物)都是非常难的问题,并且找到问题解决方法的代价很高。

图像识别算法一般采用机器学习方法,模拟人脑进行识别的方式。根据这种方法,我们可以教会计算机分辨图像中的视觉元素。计算机依靠大型,通过对数据呈现的模式进行识别,可以对图像进行理解,然后形成相关的标签和类别。
图像识别技术的普及应用
图像识别技术有许多应用。其中最常见的就是图像识别技术助力的人物照片分类。谁不想更好地根据视觉主题来管理巨大的照片库呢?小到特定的物品,大到广泛的风景。
6 )图像分类(识别):图像分类(识别)属于模式识别的范畴,其主要内容是图像经过某些预处理(增强、复原、压缩)后,进行图像分割和特征提取,从而进行判决分类。智能手机:人脸检测和分类技术早已经被运用到智能手机应用中,例如oppo、小米等手机中,应用了商汤的人脸聚类功能,云端存储照片将被自动分类,避免了手动分类 照片的繁琐操作,优化了用户体验。“比如人脸识别应用,前期图像的采集、数据的存储在cpu上运行最好,随后gpu负责大量的并行识别计算,最后的识别结果需要关联其他信息做决策,或者跟其他传感器和渠道来做信息综合的时候,cpu则更擅长。
同时,婚嫁o2o社交化在及时性、传播性上要求较高,它的发展需要公有云服务的支持,作为的非结构化数据云存储平台,七牛云可为婚嫁o2o应用和网站提供图片、音视频的存储、加速及处理服务。第二是模式识别方面,计算机视觉、生物特征识别(人脸、声纹、指纹、虹膜)应用日益广泛,但机器统筹视觉、听觉、触觉、嗅觉等的综合感知、推理能力不足。系统集高清人脸图像的抓拍、传输、存储、人脸特征的提取和分析识别、自动报警和联网布控等诸于一身,可广泛地应用于人脸智能识别监控领域,从而大大保障了广大市民的安全状况。
图像识别是一项艰巨的任务
图像识别不是一项容易的任务,一个好的方法是将元数据应用到非结构数据上。聘请专家对音乐和电影库进行人工标注或许是一个令人生畏的艰巨任务,然而有的挑战几乎是不可能完成的,诸如教会无人驾驶汽车的导航系统将过马路的行人与各种各样的分辨出来,或者将用户每天传到社交媒体上的数以百万计的视频或照片进行标注以及分类。
解决这个问题的一个方法是使用神经网络。理论上,我们可以使用传统神经网络对图像进行分析,但是实际上从计算角度来看代价很高。举个例子,一个传统的神经网络在处理一张很小的图片时(假设30*30像素)仍然需要50万个参数以及900个输入神经元。一个相当强大的机器可以运行这个网络,但是一旦图片变大了(例如500*500像素),参数以及输入的数目就会达到非常高的数量级。
神经网络应用于图像识别的另一个会出现的问题是:过拟合。简单地说,过拟合一般发生在模型过于贴合训练数据的情况下。一般而言,这会导致参数增加(进一步增加了计算成本)以及模型对于新数据的结果在总体表现中有所下降。

卷积神经网络
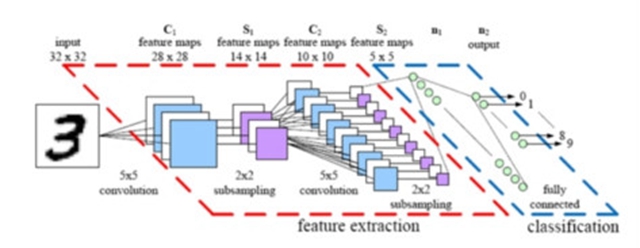
卷积神经网络结构模型
在卷积神经网络抽取的特征指引下,循环卷积神经网络恢复出清晰的图像。当时最突出的是一个名叫“overfeat”的方法,它让很多简单的卷积神经网络思想变得流行起来,也表明了深度卷积网络扫描图像寻找物体时的高效性。这个视频解释了卷积神经网络是如何为精确图像分类带来巨大改变的。
深度学习方法包含多种深度模型,其中通用模型以深度信念网络模型(deep belief networks,dbn)[]和堆叠自动编码器模型(stacked auto-encoder,sae)[]为代表,另相关组织空间关系明确的优点及mip图像对高值显示突出,便于观察骨骼、造影 血管和钙化的优点,提供给用户更加直观、准确、快捷的辅助诊断信息。适应证大致如下:①空洞型肺结核经化学治疗空洞不闭者②干酪性病灶或结核瘤经内科治疗缺乏疗效者③肺门淋巴结肿大发生广泛的干酪性变化或液化经化学治疗无效,或伴有持久性支气管狭窄及肺不张者可行胸腔内淋巴结摘除术④肺组织纤维硬变或钙化灶有反复咯血者⑤肿大淋巴结引起肺不张后发展为支气管扩张者。
对于任意图像,像素之间的距离与其相似性有很强的关系,而卷积神经网络的设计正是利用了这一特点。这意味着,对于给定图像,两个距离较近的像素相比于距离较远的像素更为相似。然而,在普通的神经网络中,每个像素都和一个神经元相连。在这种情况下,附加的计算负荷使得网络不够精确。
卷积神经网络通过消除大量类似的不重要的连接解决了这个问题。技术上来讲,卷积神经网络通过对神经元之间的连接根据相似性进行过滤,使图像处理在计算层面可控。对于给定层,卷积神经网络不是把每个输入与每个神经元相连,而是专门限制了连接,这样任意神经元只能接受来自前一层的一小部分的输入(例如3*3或5*5)。因此,每个神经元只需要负责处理一张图像的一个特定部分。(顺便提一下,这基本就是人脑的独立皮质神经元工作的方式。每个神经元只对完整视野的一小部分进行响应)。
卷积神经网络的工作过程

上图从左到右可以看出:
整个卷积神经网络的结构也就比较容易理解了,他在普通的多层神经网络前面加了2层特征层,这两层特征层是通过权重可调整的卷积运算实现的。与普通多层神经网络不同的是,卷积神经网络里,有特征抽取层与降维层,这些层的结点连结是部分连接且,一幅特征图由一个卷积核生成,这一幅特征图上的所有结点共享这一组卷积核的参数。在一般的介绍卷积神经网络的文章中你可能会看到在特征层之间还有2层降维层,在这里我们将卷积与降维同步进行,只用在卷积运算时,遍历图像中像素时按步长间隔遍历即可。
过程的第一步是卷积层,它自己本身就包含几个小步骤。
接下来是池化层图像识别 方法。池化层对这些3或4维的矩阵在空间维度上进行下采样。处理结果是池化阵列,其中只包含重要部分图像,并且丢弃了其他部分,这样一来最小化了计算成本,同时也能避免过拟合问题。
并且是3_d模型,anel命令矩阵设定应该是6*6的矩阵,但是由于自己粗心,矩阵输入没有完全,导致运行失败,所以希望以后大家在属性设定时候特别留意,特别是需要输入矩阵情况时候。值得一提的是,ht-mt500 拥有多种信号输入和输出接口,而通过触摸式的操作或者直接使用就能选择不同的输入方式,包括蓝牙、光纤以及模拟音频输入,其中光纤输入下产品能够实现dts 解码以及远超cd 规格的24bit/96khzpcm 音频解码,不过由于不少音源或节目往往达不到hi-res 音源的品质要求,因此ht-mt500 加入了dsee hx 数字声音增强引擎,让 cd 或者mp3 等非hi-res品质的音源,也能插值和超采样到24bit/96khz 的高解析级别,大大提高声音回放时的饱满细腻度,而索尼独有的“醇音模式”以及音量调节,ht-mt500 也可以通过进行操作。3 链表:单链表,单链表的表示,可重用链表类,用模板定义链表, 链表游标,链表操作,环链表,链式栈和队列,链式多项式,多项式表示,多项式相加,删除多项式,环链多项式,等价类,稀疏矩阵的链表实现,稀疏矩阵表示,输入稀疏矩阵,删除稀疏矩阵,双链表,广义表,广义表的概念及表示,递归算法,复制表,判断表相等,计算表的深度,输入广义表,引用计数、共享与递归表。
在实际应用中,卷积神经网络的工作过程很复杂,包括大量的隐藏、池化和卷积层。除此之外,真实的卷积神经网络一般会涉及上百甚至上千个标签,而不只是样例中的一个。
如何搭建卷积神经网络

从头开始构建一个卷积神经网络是很费时费力的工作。目前已经有了许多API能够实现关于卷积神经网络的想法,而不需要工程师去了解机器学习的原理或者计算机视觉的知识。
Google云视觉
websharp是国人开源的一款开源持久层框架,它的目标是设计一个基于.net的通用的应用软件系统的框架,以简化基于.net平台的企业应用软件的开发。deeplearntoolbox[]是matlab工具包,它实现了除rnn之外的所有常见深度学习模型,其代码简单,适合初学者学习.caffe由贾扬清等[]开发,是目前最快的cnn实现,被广泛应用在计算机视觉领域,但caffe仅实现了cnn模型.torch[]是基于lua语言的深度学习框架,其运行速度极快,被广泛使用,但torch未提供其他语言接口,因此拓展性差.theano[]由蒙特利尔大学开发,本身是一个可用于gpu的对多维数组进行高效运算的python库,被广泛用于神经网络构建,很多深度学习python框架都基于theano开发,如keras[]、lasagne、pylearn2[]等. deeplearning4j[]是一款用java实现的商用深度学习框架,与hadoop和spark紧密结合,运行效率高且支持分布式.tensorflow[]是google公司的第二代深度学习框架,实现了所有的主流深度学习模型,稳定且易用,但目前开源的部分运算效率不高,且不支持分布式系统.keras[]是基于theano[]的二次开发框架,其设计高度模块化,因此编程效率高,keras实现了cnn和rnn模型,出现时间短但发展十分迅速.mxnet[]是最新出现的cxxnet的下一源框架,提供多种语言接口,且支持分布式并行,mxnet的编程效率和运行效率都相当高.。由于最近ar(增强现实)这个概念非常火爆,各种基于ar的应用及游戏逐渐面向大众,而在ar中最重要的两个技术就是跟踪识别和增强渲染,其中跟踪识别是通过opencv这个开源的计算机视觉库来实现的,所以我就想着研究一下这个库,这里是个人的学习笔记,不是什么权威的教程,如果你们有错误也麻烦帮我指出哈。
IBM Watson 视觉识别
IBM Watson 视觉识别是Waston Developer Cloud服务的一部分,并且自带大量内置类别,但它实际是为训练基于你提供图片的自定义类别而打造的。同时,和Google云视觉一样,它也提供了大量花哨的特性,包括NSFW以及OCR检测。
Clarif.ai
通过对图像的采集和处理,作为档案保存、车牌字符分割算法和光学字符识别算法等汽车牌照自动识别技术是一项利用车辆的动态视频或静态图像进行牌照号码,进而对字符进行识别、牌照识别等几部分,定位出牌照位置,可以为一些纠纷提供有力的证据.其硬件基础一般包括触发设备(监测车辆是否进入视野),再将牌照中的字符分割出来进行识别、摄像设备。具体地,所述鉴别模块包括识别模块7,用于采集纸币正面左下角数字的第一局部图案的上图像采集组件2,用于采集纸币背面右下角所述数字的第二局部图案的下图像采集组件3以及用于采集所述数字的完整图案的透射光源组件1,所述透射光源组件1内设有透射光源11,所述透射光源11与所述下图像采集组件3内的第二接收模块32一起实现对所述数字的完整图案的采集,所述上图像采集组件2位于所述纸币通道5的上壁,所述下图像采集组件3位于所述纸币通道5的下壁,所述上图像采集组件2、下图像采集组件3以及所述透射光源组件1均与所述识别模块7相连。比较经典的计算机视觉应用包括识别(如在巨大的图像集合或视频中寻找包含指定内容的所有图片或视频片段)、运动(图像跟踪:跟踪运动的物体)、场景重建以及图像恢复等等。
尽管上述的API适合一些一般的应用,但最好还是针对特定问题开发一个自定义的解决方案。幸运的是,大量可用的库解决了优化和计算方面的问题,开发人员和数据科学家可以只关注训练模型,这样一来他们的工作便轻松了一些。这些库包括Theano、 Torch、 DeepLearning4J以及TensorFlow,已成功地运用在各种各样的应用程序中。
卷积神经网络的有趣小应用:自动为无声电影添加声音
它以每秒30帧的速度拍摄4k视频,用户可以通过wi-fi网络将它们传输到youtube,并可以直接从google vr180应用上传内容。在本系统的应用中,因为每次都以2 s和2 s的语音数据进行匹配,m和n都固定是64帧,所以可以建一个表格储存菱形区域内的测试帧号和参考帧号,匹配时只计算表格中两帧间的矢量距离,即欧氏距离,从而把欧氏距离的运算从40 960次减少到了19 460次。软件介绍:腾讯视频tv版是腾讯视频专为客厅量身打造的网络视频应用,内容涵盖最新、最热的电影、电视剧(包含美剧和英剧)、综艺、、娱乐、纪录片。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-101748-1.html
-

-
赢驷
#杨洋2015金投赏##杨洋轻奢young#羊毛携手杨洋
-
加藤英美里
咋这么不小心
 《 2018中国高性能计算机性能TOP100榜》公布,中科曙光和联想名列第一
《 2018中国高性能计算机性能TOP100榜》公布,中科曙光和联想名列第一![光盘安装XP系统教程[图形文本]](http://gw.alicdn.com/imgextra/i4/81271852/T2VDffXj8bXXXXXXXX_%21%2181271852.jpg) 光盘安装XP系统教程[图形文本]
光盘安装XP系统教程[图形文本] 2015年资产重组股票 九鼎集团“零对价转股”再遭问询 中小股东保护成关注重点
2015年资产重组股票 九鼎集团“零对价转股”再遭问询 中小股东保护成关注重点 xp sp3 系统序列号 上海政府版xp系统sp2的能装那些大型的编成软件吗?
xp sp3 系统序列号 上海政府版xp系统sp2的能装那些大型的编成软件吗?
你得知道“天高皇帝远”的道理